
Redis集群 ·Redis集群提供了一種運行Redis安裝的方法,在該安裝中,數據會在多個Redis節點之間自動分片。 Redis集群在分區期間還提供了一定程度的可用性,這實際上是在某些節點出現故障或無法通信時有繼續工作的能力。但是,如果發生較嚴重故障(例如,大多數主節點不可用時),集群將停止運行 ...
Redis集群
·Redis集群提供了一種運行Redis安裝的方法,在該安裝中,數據會在多個Redis節點之間自動分片。
Redis集群在分區期間還提供了一定程度的可用性,這實際上是在某些節點出現故障或無法通信時有繼續工作的能力。但是,如果發生較嚴重故障(例如,大多數主節點不可用時),集群將停止運行。
實際上,Redis集群能給你帶來什麼?
- 自動在多個節點之間拆分數據集的能力。
- 當一部分節點出現故障或無法與集群中其他節點通信時,仍然可以繼續操作。
Redis集群TCP埠
每個Redis集群節點都需要打開兩個TCP連接。用於服務客戶端的常規RedisTCP埠,例如6379,再加上將數據埠加10000的埠,比如在示例中為16379。
第二個值更大一點的埠用於集群匯流排,也就是使用二進位協議的節點到節點之間的通信通道。節點將集群匯流排用於故障檢測,配置更新,故障轉移授權等。客戶端永遠不要嘗試與集群匯流排埠進行通信,而應始終與普通的Redis命令埠進行通信,但是請確保您在防火牆中同時打開了這兩個埠,否則Redis集群節點將無法進行通信。
命令埠和集群匯流排埠的偏移量是固定的,並且始終為10000。
請註意,對於每個節點,要使Redis集群正常工作,您需要:
- 用於與客戶端通信的常規通信埠(通常為6379),向那些需要訪問集群的所有客戶端以及所有其他集群節點(使用客戶端埠進行key遷移)開放。
- 集群匯流排埠(客戶端埠+ 10000)必須可以從所有其他集群節點訪問。
如果您沒有同時打開兩個TCP埠,則集群將無法正常工作。
集群匯流排使用不同的二進位協議進行節點到節點的數據交換,它更適合於在節點之間使用較少的帶寬和較少的處理時間來交換信息。
Redis集群數據分片
Redis集群不使用一致性哈希,而是使用一種不同形式的分片,從概念上講每個key都是我們稱為hash槽的一部分。
Redis集群中有16384個hash槽,要計算給定key的hash槽,需將key的CRC16值用16384取模。
Redis集群中的每個節點都負責hash槽的子集,例如,您可能有一個包含3個節點的集群,其中:
- 節點A包含從0到5500的hash槽。
- 節點B包含從5501到11000的hash槽。
- 節點C包含從11001到16383的hash槽。
這樣可以輕鬆添加和刪除集群中的節點。例如,如果我想添加一個新節點D,則需要將一些hash槽從節點A,B,C移到D。類似地,如果我想從集群中刪除節點A,則只需移動A所服務的hash槽到B和C。當節點A為空時,我可以將其從集群中完全刪除。
因為將hash槽從一個節點移動到另一個節點不需要停止操作,所以添加刪除節點或更改節點服務的hash槽的百分比不需要停機。
只要單個命令執行(或整個事務或Lua腳本執行)中涉及的所有key都屬於同一個hash槽,Redis集群就支持多key操作。用戶可以通過使用稱為hash標簽的概念來強制多個key成為同一hash槽的一部分。
hash標簽記錄在Redis集群規範中,註意,如果key的{}中的括弧之間有一個子字元串,則僅對字元串中的內容進行hash處理,例如,一個叫{foo}的key和另一個叫{foo} 的 key保證在同一hash槽中,並且可以在以多個key作為參數的命令中一起使用。
Redis集群主備模式
為了在主節點子集發生故障或無法與大多數節點通信時保持可用,Redis集群使用主備模型,其中每個hash槽具有從1(主節點本身)到N個副本(N -1個其他備份節點)。
在一個包含節點A,B,C的集群中,如果節點B失敗,則集群將無法繼續,因為我們不能為 5501-11000 範圍內的hash槽提供服務。但是,在創建集群(或稍後)時,我們向每個主節點添加一個備份節點,以便最終集群由作為主節點的A,B,C和作為備份節點的A1,B1,C1組成 ,如果節點B發生故障,系統將能夠持續運行。節點B1複製B,並且B發生故障,集群會將節點B1提升為新的主節點,並將繼續正常運行。
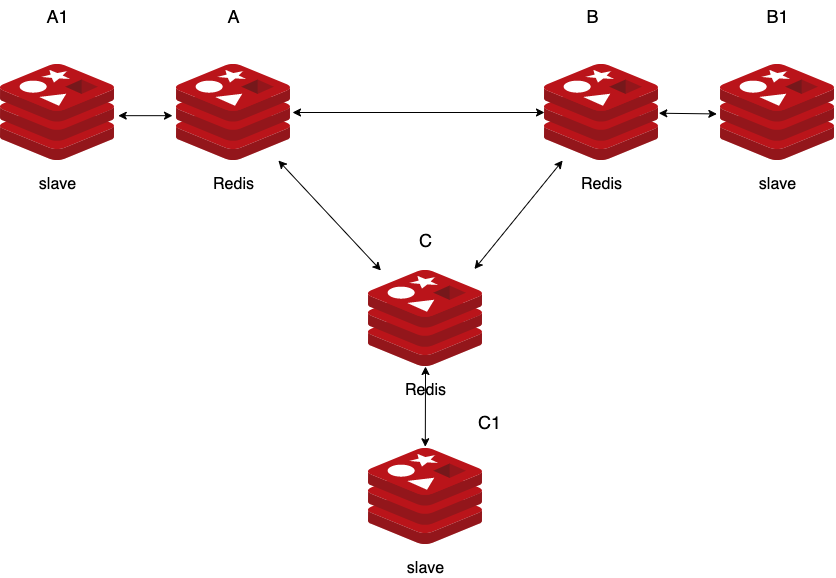
但是請註意,如果節點B和B1同時失敗,則Redis集群無法繼續運行。
Redis集群的一致性保證
Redis集群無法保證強一致性。 實際上,這意味著在某些情況下,Redis集群可能會丟失系統給客戶端的已經確認的寫操作。
Redis集群可能丟失寫入的第一個原因是因為它使用非同步複製。這意味著在寫入期
間會發生以下情況:
- 您的客戶端向B主節點寫入數據。
- B主節點向您的客戶端答覆“確定”。
- B主節點將寫操作傳播到其備份節點B1,B2和B3。
如您所見,B在回覆客戶端之前不會等待B1,B2,B3的確認,因為這會對Redis造成延遲,因此,如果您的客戶端進行了寫操作,然後B會確認,但是在它把寫操作發送給備份節點之前崩潰了,此時其中一個備份節點(未接收到寫操作)可以升級為主節點,這樣就永遠丟失該寫操作。這與配置為每秒將數據刷新到磁碟的大多數資料庫所發生的情況非常相似,因此由於過去使用不涉及分散式系統的傳統資料庫系統的經驗,您已經可以對此進行合理推斷。同樣,您可以通過強制資料庫在答覆客戶端之前刷新磁碟上的數據來提高一致性,但這通常會導致性能過低。在Redis集群下,這相當於同步複製。
基本上,在性能和一致性之間進行權衡是必須的。
Redis集群在需要時可以通過WAIT命令實現同步寫,這使得丟失寫的可能性大大降低,但是請註意,即使使用同步複製,Redis集群也不實現強一致性:在更複雜的情況下,總是有可能存在一種場景,就是一個無法接收數據的備份節點被選為主節點。
還有一種值得註意的情況,Redis集群也會丟失寫操作,這種情況發生在網路分區期間,在該分區中,客戶端與少數實例(至少包括主節點)隔離。
以我們的6個節點集群為例,該集群由A,B,C,A1,B1,C1組成,具有3個主節點
和3個備份節點。還有一個客戶,我們將其稱為Z1。
發生分區後,可能在分區的一側有A,C,A1,B1,C1,而在另一側有B和Z1。
Z1仍然能夠對B進行寫操作,B將接受其寫入。如果分區在很短的時間內恢復正常,則集群將繼續正常運行。但是,如果分區持續的時間足以使B1升級為該分區的多數端的主節點,則Z1向B發送的寫操作將丟失。
請註意,Z1將能夠發送到B的寫入量有一個最大的視窗:如果已經有足夠的時間使大分區選舉出一個主節點,則小分區中的每個主節點都將停止接受寫入。該時間是Redis集群的一個非常重要的配置指令,稱為節點超時。
在節點超時之後,主節點被視為發生故障,並且可以用其副本之一替換。類似地,在超過指定的時間後,主節點還是無法感知大多數其他主節點,此主節點進入錯誤狀態並停止接受寫入。
Redis集群配置參數
我們將創建一個集群部署作為例子。在繼續之前,讓我們介紹一下Redis集群里的redis.conf文件中引入的配置參數。
繼續閱讀下去您就會獲得更多清晰的要點。
- cluster-enabled <yes/no> : 如果設置為yes,Redis實例中將會啟用集群支持。否則,該實例將像往常一樣作為獨立實例啟動。
- cluster-config-file
: 請註意,儘管有此選項,但它是不允許用戶可編輯的配置文件,而是Redis集
群節點在每次有變更時(基本上是狀態)都會自動持久保存的集群配置文件,以便能夠在啟動時重新讀取它。
該文件列出了諸如集群中其他節點的內容,狀態,持久變數等等之類的東西。通常,在收到某些消息時,此文件將被
重寫並刷新到磁碟上。 - cluster-node-timeout <毫秒> :Redis集群節點在被認為故障前的最長間隔時間。如果無法訪問主節點的時間超過指定的時間長度,則它的備份節點將對
其進行故障轉移。此參數也控制Redis集群中的其他重要事情。值得註意的是,在指定的時間內無法連通大多數主節點
的每個節點都將停止接受查詢請求。 - cluster-slave-validity-factor
:如果設置為零,則備份節點將始終嘗試對主節點進行故障轉移,而不管主節點和備份節點之間的鏈接斷開
狀態的時間長短。如果該值為正,則將最大斷開時間計算為節點超時時間乘以此選項提供的因數,如果該節點是備份
節點,並且主鏈接斷開的時間超過了指定的時間,它將不會嘗試啟動故障轉移。例如,如果節點超時設置為5秒,而有
效性因數設置為10,則備份節點與主節點斷開連接超過50秒將不會嘗試對其主節點進行故障轉移。請註意,如果沒有
備份節點可以對其進行故障轉移,則任何不為零的值都可能導致Redis集群在主節點發生故障後不可用。
在這種情況下,只有當原始主節點重新加入集群後,集群才會返回可用狀態。 - cluster-migration-barrier
:主節點需要保持連接的備份節點的最小數量,以便另一個備份節點遷移到一個沒有任何備份節點覆蓋的主
節點。有關更多信息,請參見本教程中有關副本遷移的相應部分。 - cluster-require-full-coverage <yes / no>:如果設置為yes,預設情況下,如果某個節點未覆蓋一定比例的key空間,集群將停止接受寫入。如果該選項設
置為no,即使此節點僅能處理有關key的部分子集的請求,集群仍將提供查詢。
創建和使用一個Redis集群
註意:手動部署Redis集群,瞭解其某些操作非常重要。 但是,如果要儘快建立集群並運行,請跳過本節和下一節,直接轉到使用 create-cluster 腳本創建Redis集群。
要創建集群,我們需要做的第一件事就是讓一些空Redis實例運行在集群模式下。基本上,這意味著不能使用常規Redis實例來創建集群,因為需要配置特殊模式,以便Redis實例啟用集群特定的功能和命令。
以下是最小的Redis集群配置文件:
port 7000 # 埠號
cluster-enabled yes # 是成為cluster節點
cluster-config-file nodes.conf # 節點配置文件
cluster-node-timeout 5000 # 節點超時時間
appendonly yes # 是否使用aof
啟用集群模式的只需要直接打開cluster-enabled命令。每個實例還包含該節點配置存儲位置的文件路徑,預設情況下為nodes.conf。 該文件不會被人接觸。 它只是由Redis集群實例在啟動時生成,併在需要時進行更新。
請註意,按預期工作的最小集群要求至少包含三個主節點。 對於您的第一個測試,強烈建議啟動一個包含三個主節點和三個備份節點的六個節點集群。為此,輸入一個新目錄並創建以下目錄,該目錄以我們將在給定目錄中運行的實例的埠號命名。就像是:
mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005
在從7000到7005的每個目錄中創建一個redis.conf文件。作為配置文件的模板,只需使用上面的小示例,但請確保根據目錄名稱用正確的埠號替換埠號7000。現在,將您的redis-server可執行文件(從GitHub不穩定分支中的最新資源編譯而來)複製到cluster-test目錄中,最後在您喜歡的終端應用程式中打開6個終端選項卡。
像這樣啟動每個實例,每個選項卡一個:
cd 7000
../redis-server ./redis.conf
從每個實例的日誌中可以看到,由於不存在nodes.conf文件,因此每個節點都會為其分配一個新的ID。
[82462] 26 Nov 11:56:55.329 * No cluster configuration found, I'm 97a3a64667477371c4479320d683e4c8db5858b1
該ID將由該實例永久使用,以使該實例在集群的上下文中具有唯一的名稱。每個節點都使用該ID而不是IP或埠記住其他每個節點。 IP地址和埠可能會更改,但是唯一的節點標識符在節點的整個生命周期中都不會改變。我們將此標識符簡稱為節點ID。
創建集群
現在,我們有許多實例正在運行,然後需要通過向節點寫入一些有意義的配置來創建集群。
如果您使用的是Redis 5,這很容易完成,這是因為redis-cli中嵌入了Redis集群命令行實用程式,我們可以使用它來創建新集群,檢查或重新分片現有集群等。
對於Redis版本3或4,有一個稱為redis-trib.rb的較老的工具,它非常相似。您可以在Redis源代碼分發的src目錄中找到它。 您需要安裝redis gem才能運行redis-trib。
gem install redis
第一個示例,即集群創建,將在Redis 5中使用redis-cli以及在Redis 3和4中使用redis-trib來顯示。但是,接下來的所有示例都將僅使用redis-cli,因為您可以看到他們語法非常相似,您也可以使用redis-trib.rb help來獲取有關語法的信息,從而將一個命令行簡單地更改為另一命令行。 重要:請註意,如果需要,可以對Redis 4集群使用Redis 5 redis-cli。
要使用redis-cli為Redis 5創建集群,只需鍵入:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
對於redis 4或者3 請使用redis-trib.rb工具:
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
此處使用的命令是create,因為我們要創建一個新集群。 選項
--cluster-replicas 1表示我們希望每個創建的主節點都具有一個備份節點。其他參數是要用於創建新集群的實例
的地址列表。
顯然,滿足我們要求的唯一設置是創建具有3個主節點和3個從節點的集群。
Redis-cli將為您提供配置。 鍵入yes,將接受建議的配置。集群將被配置並加入,這意味著實例將被啟動然後彼此
之間可以對話。 最後,如果一切順利,您將看到如下消息:
[OK] All 16384 slots covered
意思就是說至少有一個主節點實例服務於16384個槽位中某一個.
使用create-cluster腳本創建一個Redis集群
如果您不想如上所述通過手動配置和執行單個實例來創建Redis集群,則可以使用更簡單的系統(但是您將不會學到同樣多的操作細節)。
只需檢查Redis發行版中的utils / create-cluster目錄。內部有一個名為create-cluster的腳本(名稱與包含在其中的目錄相同),它是一個簡單的bash腳本。 為了啟動具有3個主節點和3個備份節點的6節點集群,只需鍵入以下命令:
- create-cluster start
- create-cluster create
在步驟2中,當redis-cli希望您接受集群佈局時,回覆yes。
現在,您可以與集群進行交互,預設情況下,第一個節點將從埠30001開始。 完成後,使用以下命令停止集群:
create-cluster stop.
關於如何運行這個腳本的更多信息,請閱讀目錄里的README。
集群操作
到目前為止,Redis集群的問題之一是缺少客戶端庫的實現。
據我所知有以下實現:
- redis-rb-cluster 是我(@antirez)編寫的Ruby實現,可作為其他語言的參考。它是原始redis-rb的簡單包裝,實現了最小語義以有效地與集群通信。
- redis-py-cluster redis-rb-cluster的Python實現。支持大多數redis-py功能。正在積極發展中。
- 流行的Predis支持Redis集群,該支持最近已更新並且正在積極開發中。
- 使用最廣泛的Java客戶端,Jedis最近添加了對Redis集群的支持,請參閱項目README中的Jedis集群部分。
- StackExchange.Redis提供對C#的支持(並且應與大多數.NET語言,VB,F#等相容)
- thunk-redis提供對Node.js和io.js的支持,它是基於thunk/promise的redis客戶端,具有管道和集群功能。
redis-go-cluster是Go語言的
Redis集群的實現,它使用了Redigo library client作為基本客戶端,通過結果聚合實現了MGET/MSET。 - ioredis是流行的Node.js客戶端,為Redis集群提供了強大的支持。
- 當使用-c開關啟動時,redis-cli程式實現了基本的集群支持。
測試Redis集群的一種簡單方法是嘗試上述任何客戶端,或者僅嘗試redis-cli命令。以下是使用後者進行交互的示例:
$ redis-cli -c -p 7000
redis 127.0.0.1:7000> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:7002
OK
redis 127.0.0.1:7002> set hello world
-> Redirected to slot [866] located at 127.0.0.1:7000
OK
redis 127.0.0.1:7000> get foo
-> Redirected to slot [12182] located at 127.0.0.1:7002
"bar"
redis 127.0.0.1:7000> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"
註意:如果使用腳本創建集群,則節點可能會偵聽不同的埠,預設情況下從30001開始。
redis-cli的支持非常基礎,因此它始終基於以下事實:Redis集群節點能夠將客戶端重定向到正確的節點。一個嚴格的客戶端可以做得更好,並且可以在hash槽和節點地址之間緩存映射,以便直接使用與節點的正確連接。僅在集群配置中發生某些更改時(例如,在故障轉移之後或系統管理員通過添加或刪除節點來更改集群佈局之後),才會刷新映射。
使用redis-rb-cluster寫一個簡單的應用程式
在繼續展示如何操作Redis集群之前,比如執行故障轉移或重新分片之類的操作,我們需要創建一些示例應用程式,或者至少要能夠理解簡單的Redis集群客戶端交互的語義。
通過這種方式,我們可以運行一個示例,同時嘗試使節點發生故障或開始重新分片,以瞭解Redis集群在現實環境下的行為。只是觀察一個沒有寫入任何數據的集群是沒有幫助的。
本節說明瞭redis-rb-cluster的一些基本用法,其中顯示了兩個示例。 首先是以下內容,它是redis-rb-cluster發行版中的example.rb文件:
1 require './cluster'
2
3 if ARGV.length != 2
4 startup_nodes = [
5 {:host => "127.0.0.1", :port => 7000},
6 {:host => "127.0.0.1", :port => 7001}
7 ]
8 else
9 startup_nodes = [
10 {:host => ARGV[0], :port => ARGV[1].to_i}
11 ]
12 end
13
14 rc = RedisCluster.new(startup_nodes,32,:timeout => 0.1)
15
16 last = false
17
18 while not last
19 begin
20 last = rc.get("__last__")
21 last = 0 if !last
22 rescue => e
23 puts "error #{e.to_s}"
24 sleep 1
25 end
26 end
27
28 ((last.to_i+1)..1000000000).each{|x|
29 begin
30 rc.set("foo#{x}",x)
31 puts rc.get("foo#{x}")
32 rc.set("__last__",x)
33 rescue => e
34 puts "error #{e.to_s}"
35 end
36 sleep 0.1
37 }
該程式做了一件非常簡單的事情,它將foo
因此,如果您運行該程式,其結果將和以下命令是一樣的效果:
- SET foo0 0
- SET foo1 1
- SET foo2 2
- ...
該程式看起來比較複雜,因為它需要在屏幕上顯示錯誤而不是異常退出,因此,對集群執行的每個操作都應該由錯誤處理包裝。
第14行是程式中的第一個有趣的行。它創建Redis集群對象,使用啟動節點列表作為參數,並允許該對象與不同節點建立的最大連接數,最後是超時時間,對於給定的操作多少時間後被視為失敗。
啟動節點不需要是集群的所有節點。但至少有一個節點是可達的。還要註意,只要能夠與第一個節點連接,redis-rb-cluster就會更新此啟動節點列表。您應該期望任何其他嚴格的客戶端都應該採取這種行為。
現在我們已經將Redis集群對象實例存儲在rc變數中,我們可以像使用普通的Redis對象實例一樣使用該對象了。
這恰好發生在第18至26行中:重新啟動示例時,我們不想以foo0重新開始,因此我們將計數器存儲在Redis本身內。上面的代碼旨在讀取此計數器,或者如果不存在該計數器,則為其分配零值。
但是請註意這是一個while迴圈,因為即使集群關閉並返回錯誤,我們也要一次又一次嘗試。普通的應用程式不需要那麼小心。
28和37之間開始主迴圈,在該迴圈中設置key或顯示錯誤。
註意迴圈結束時的sleep調用。在測試中,如果您想儘可能快地寫入集群,則可以刪除sleep(相對來說,這隻是一個很繁忙的迴圈操作,它並沒有真正的並行,因此,在最好的條件下,您通常將獲得每秒10k個操作))。
通常,為了使示常式序更容易被人看懂,寫入速度會減慢。啟動應用程式將產生以下輸出:
ruby ./example.rb
1
2
3
4
5
6
7
8
9
^C (I stopped the program here)
這不是一個非常有趣的程式,我們稍後將使用更好的程式,但是我們已經可以看到程式運行時,在重新分片期間都發生了什麼。
集群重新分片
現在,我們準備嘗試集群重新分片。 為此,請保持example.rb程式運行,以便您查看對程式的運行是否有影響。另外,您可能想註釋一下sleep調用,以便在重新分片期間發生一些更嚴重的寫入負載。重新分片基本上意味著將hash槽從一組節點移動到另一組節點,並且像集群創建一樣,它使用redis-cli程式完成。
要開始重新分片,只需鍵入:
redis-cli --cluster reshard 127.0.0.1:7000
您只需要指定一個節點,redis-cli將自動找到其他節點。
當前redis-cli僅能在管理員支持下重新分片,您不能僅僅說將5%的插槽從該節點移到另一個節點(當然這實現起來很簡單)。 因此,它會以一個問題開始。 首先是您想做多少重分片:
How many slots do you want to move (from 1 to 16384)?
我們可以嘗試重新分派1000個hash槽,如果該示例仍在運行且沒有sleep調用,則該hash槽應已包含少量的key。
然後redis-cli需要知道重新分片的目標是什麼,也就是將接收hash槽的節點。 我將使用第一個主節點,即127.0.0.1:7000,但是我需要指定實例的節點ID。redis-cli已將其列印在列表中,但是如果需要的話,我也可以使用以下命令找到節點的ID:
$ redis-cli -p 7000 cluster nodes | grep myself
97a3a64667477371c4479320d683e4c8db5858b1 :0 myself,master - 0 0 0 connected 0-5460
所以我的目標節點應該是是 97a3a64667477371c4479320d683e4c8db5858b1。
現在,它會問你要從哪些節點獲取這些key。我只輸入all,以便從所有其他主節點獲取一些hash槽。
最終確認後,您會看到一條消息,表明redis-cli將要從一個節點移動到另一個節點,並且將從一側移動到另一側的每個實際的key都會列印出來。
在重新分片過程中,您應該能夠看到示常式序運行不受影響。如果需要,您還可以在重新分片期間停止並重新啟動它多次。重新分片結束時,可以使用以下命令測試集群的運行狀況:
redis-cli --cluster check 127.0.0.1:7000
所有插槽都會被覆蓋到,但是這次127.0.0.1:7000的主節點將具有更多的hash插槽
,大約為6461。
一個更有趣的示例應用程式
我們之前編寫的示常式序不怎麼好。它以一種簡單的方式寫入集群,甚至無需檢查寫入的內容是否正確。從我們的角度來看,接收寫操作的集群可以始終在每個操作里將名為foo的key寫到42這個hash槽里,而我們根本不會註意到。因此,在redis-rb-cluster代碼倉庫中,有一個更有趣的程式,稱為consistency-test.rb。它使用一組計數器,預設為1000,並且發送INCR命令以增加計數器的值。但是,該應用程式不僅可以寫數據,還可以做兩件事:
- 當使用INCR更新計數器時,應用程式會記住該寫入。
- 它還在每次寫入之前讀取一個隨機計數器,並檢查該值是否符合我們的預期,並將其與記憶體中的值進行比較。
這意味著該程式是一個簡單的一致性檢查程式,可以告訴您集群是否丟失了一些寫操作,或者它是否接受了我們未收到確認的寫操作。在第一種情況下,我們將看到一個計數器的值小於我們之前記住的值,而在第二種情況下,該值將更大。
運行一致性測試應用程式每秒產生一行輸出:
$ ruby consistency-test.rb
925 R (0 err) | 925 W (0 err) |
5030 R (0 err) | 5030 W (0 err) |
9261 R (0 err) | 9261 W (0 err) |
13517 R (0 err) | 13517 W (0 err) |
17780 R (0 err) | 17780 W (0 err) |
22025 R (0 err) | 22025 W (0 err) |
25818 R (0 err) | 25818 W (0 err) |
該行顯示執行的讀取和寫入的次數,以及錯誤的數目(由於系統不可用,因此由於錯誤而無法接受查詢)。如果發現不一致,則將新行添加到輸出中。例如,如果我在程式運行時手動重置了計數器,就會發生這種情況:
$ redis-cli -h 127.0.0.1 -p 7000 set key_217 0
OK
(in the other tab I see...)
94774 R (0 err) | 94774 W (0 err) |
98821 R (0 err) | 98821 W (0 err) |
102886 R (0 err) | 102886 W (0 err) | 114 lost |
107046 R (0 err) | 107046 W (0 err) | 114 lost |
當我將計數器設置為0時,實際值為114,因此程式會報告114的寫丟失了(集群無法記住的INCR命令)。該程式作為測試用例更加有趣,因此我們將使用它來測試Redis 集群故障轉移。
測試故障轉移
註意:在此測試過程中,你應打開一個tab標簽頁併在上面運行一致性測試應用程式。
為了觸發故障轉移,我們可以做的最簡單的事情(也就是在分散式系統中可能發生的語義上最簡單的失敗)是使單個進程崩潰,在我們的例子中是單個主機崩潰。
我們可以使用以下命令來識別主節點並使其崩潰:
$ redis-cli -p 7000 cluster nodes | grep master
3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 127.0.0.1:7001 master - 0 1385482984082 0 connected 5960-10921
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:7002 master - 0 1385482983582 0 connected 11423-16383
97a3a64667477371c4479320d683e4c8db5858b1 :0 myself,master - 0 0 0 connected 0-5959 10922-11422
好了,現在7000,7001,7002都是主節點,我們把7002這台機器用DEBUG SEGFAULT命令使其崩潰。
$ redis-cli -p 7002 debug segfault
Error: Server closed the connection
現在我們可以看看這個一致性測試的輸出的報告是什麼。
18849 R (0 err) | 18849 W (0 err) |
23151 R (0 err) | 23151 W (0 err) |
27302 R (0 err) | 27302 W (0 err) |
... many error warnings here ...
29659 R (578 err) | 29660 W (577 err) |
33749 R (578 err) | 33750 W (577 err) |
37918 R (578 err) | 37919 W (577 err) |
42077 R (578 err) | 42078 W (577 err) |
如您所見,在故障轉移期間,系統無法接受578次讀取和577次寫入,但是在資料庫中並未創建任何不一致的數據。
這聽起來可能是個意外,因為在本教程的第一部分中,我們說過Redis集群在故障轉移期間會丟失寫操作,因為它使用非同步複製。我們沒有說的是,這其實不太可能發生,因為Redis會給客戶端發送回應,並且同樣的命令幾乎同時會複製到備份節點,因此丟失數據的視窗很小。但是,很難觸發這一事實並不意味著它不可能,因此這不會改變Redis集群提供的一致性保證。
現在,我們可以檢查故障轉移之後的集群設置是什麼(請註意,我重新啟動了崩潰的實例,以便它作為備份節點重新加入集群):
$ redis-cli -p 7000 cluster nodes
3fc783611028b1707fd65345e763befb36454d73 127.0.0.1:7004 slave 3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 0 1385503418521 0 connected
a211e242fc6b22a9427fed61285e85892fa04e08 127.0.0.1:7003 slave 97a3a64667477371c4479320d683e4c8db5858b1 0 1385503419023 0 connected
97a3a64667477371c4479320d683e4c8db5858b1 :0 myself,master - 0 0 0 connected 0-5959 10922-11422
3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7005 master - 0 1385503419023 3 connected 11423-16383
3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 127.0.0.1:7001 master - 0 1385503417005 0 connected 5960-10921
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:7002 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385503418016 3 connected
現在,主節點在埠7000、7001和7005上運行。以前是主節點(在埠7002上運行的Redis實例)現在變成了7005的備份節點。
CLUSTER NODES命令的輸出可能看起來很複雜,但實際上非常簡單,由以下標記組成:
- 節點ID
- ip:埠
- 標誌位: 主節點,備份節點, myself, 失敗狀態, ...
- 如果自己是備份節點,則是其主節點的ID
- 上一次發出PING後還未收到回覆的持續時間.
- 上一次接收到的PONG的時間.
- 節點的配置epoch (請看 集群規範).
- 此節點的鏈接狀態.
- 服務的插槽...
手動故障轉移
有時,強制進行故障轉移而實際上不會對主節點引起任何問題是很有用的。例如,為了升級主節點之一的Redis進程,最好對其進行故障轉移,以將其轉變為對可用性的影響最小的備份節點。
Redis集群使用CLUSTER FAILOVER 命令支持手動故障轉移,該手動故障轉移必須在要進行故障轉移的主節點的備份節點之一中執行。
與實際的主伺服器故障導致的故障轉移相比,手動故障轉移是不一樣的,但它更安全,因為它們觸發的方式避免了此過程中的數據丟失,只有在系統確定新的主節點已經在運行並且替代了舊的主節點的數據複製功能後,才能將客戶端從原來的主節點切換到新的主節點。
在執行手動故障轉移時在備份節點日誌中可以看到:
# Manual failover user request accepted.
# Received replication offset for paused master manual failover: 347540
# All master replication stream processed, manual failover can start.
# Start of election delayed for 0 milliseconds (rank #0, offset 347540).
# Starting a failover election for epoch 7545.
# Failover election won: I'm the new master.
基本上,連接到我們將要進行故障轉移的主節點的客戶端都已停止。同時,主節點將其複製偏移發送到備份節點,備份節點會在它這邊等待偏移接收完畢。 當複製偏移量完成時,故障轉移開始,並且將向舊的主節點通知配置切換。 當客戶端在舊的主節點上解鎖時,它們將被重定向到新的主節點。
添加新節點
添加新節點的基本過程是先添加一個空節點,然後將一些數據移入該節點(如果它是新的主節點),或者告訴它設置為已知節點的副本(如果它是備份節點)。從添加新的主節點開始,我們兩者都會展示。在這兩種情況下,要執行的第一步都是添加一個空節點。這就像在埠7006中啟動一個新節點(現有的6個節點已經從7000到7005使用新節點)一樣簡單,除了埠號之外,其他節點都使用相同的配置,因此您應該按順序進行操作以符合我們之前節點使用的設置:
- 在你的終端應用上開啟一個新的tab。
- 輸入 cluster-test 目錄.
- 創建一個名字為7006的文件夾.
- 在文件夾里創建redis.conf文件, 就跟其他已經在使用的節點一樣,只是換成了7006埠.
- 最後,通過命令 ../redis-server ./redis.conf 啟動服務,
此時這個服務應該運行起來了。現在我們可以使用redis-cli來向已有的集群添加一個節點。
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
如您所見,我使用add-node命令將新節點的地址指定為第一個參數,並將集群中隨機存在的節點的地址指定為第二個參數。實際上,redis-cli在這裡對我們沒什麼用,它只是向節點發送了CLUSTERMEET消息,這也可以手動完成。不過redis-cli會在運行之前檢查集群的狀態,因此,即使您知道內部結構如何運行,通過redis-cli執行集群操作是仍然是一個好主意。
現在,我們可以連接到新節點,以查看它是否確實加入了集群:
redis 127.0.0.1:7006> cluster nodes
3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 127.0.0.1:7001 master - 0 1385543178575 0 connected 5960-10921
3fc783611028b1707fd65345e763befb36454d73 127.0.0.1:7004 slave 3e3a6cb0d9a9a87168e266b0a0b24026c0aae3f0 0 1385543179583 0 connected
f093c80dde814da99c5cf72a7dd01590792b783b :0 myself,master - 0 0 0 connected
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:7002 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543178072 3 connected
a211e242fc6b22a9427fed61285e85892fa04e08 127.0.0.1:7003 slave 97a3a64667477371c4479320d683e4c8db5858b1 0 1385543178575 0 connected
97a3a64667477371c4479320d683e4c8db5858b1 127.0.0.1:7000 master - 0 1385543179080 0 connected 0-5959 10922-11422
3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7005 master - 0 1385543177568 3 connected 11423-16383
請註意,由於此節點已經連接到集群,因此它已經能夠正確重定向客戶端查詢,通常來說它已經是集群的一部分了。 但是,與其他主節點相比,它有兩個特點:
- 由於沒有分配的hash槽,因此不保存任何數據。
- 因為它是沒有分配插槽的主機,所以當備份節點要成為主節點時,它不會參與選
舉過程。
現在可以使用redis-cli的重新分片功能將hash槽分配給該節點。像上一節中已經展示的那樣,這裡我就不展示了,他們的操作沒有區別,只是將空節點作為目標進行重新分片。
添加一個節點作為副本(備份節點)
添加一個備份節點可以通過2種方式完成。最常用的是用 redis-cli, 不過要用--cluster-slave選項,就像這樣:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave
請註意,此處的命令行與我們用於添加新主節點的命令行完全相同,因此我們並未指定要向其添加副本的主節點。在這種情況下,redis-cli要做的就是將新節點添加給副本較少的主節點中的隨機主節點的副本。但是,您可以使用以下命令行指定想要與新副本一起使用的主節點:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
這樣我們便將新副本分配給特定的主節點。
將副本添加到特定主節點的一種更手動的方法是將新節點添加為空的主節點,然後使用CLUSTER REPLICATE命令將其轉換為副本。 如果將該節點添加為備份節點,但您想將其作為其他主節點的副本進行移動,也一樣適用。
例如,為了給節點127.0.0.1:7005添加副本,此節點當前服務的hash槽正在11423-16383範圍內,節點ID為3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e,我要做的就是連接到新節點(已經作為空的主節點添加到集群)併在新節點上發送命令:
redis 127.0.0.1:7006> cluster replicate 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
就是這樣。 現在,這組hash槽有了一個新副本,並且集群中的所有其他節點都已經知道(幾秒鐘後需要更新其配置)。 我們可以使用以下命令進行驗證:
$ redis-cli -p 7000 cluster nodes | grep slave | grep 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
f093c80dde814da99c5cf72a7dd01590792b783b 127.0.0.1:7006 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543617702 3 connected
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:7002 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543617198 3 connected
節點3c3a0c...現在有了2個備份節點,運行在7002埠(已存在)和7006埠(新加入的)
移除節點
為了移除一個備份節點,只需要在redis-cli上使用del-node 命令:
redis-cli --cluster del-node 127.0.0.1:7000 `<node-id>`
第一個參數只是集群中的一個隨機節點,第二個參數是您要刪除的節點的ID。您也可以用相同的方法刪除主節點,但是要刪除主節點,它必須為空。如果主節點不為空,則需要先將數據重新分片到所有其他主節點。
刪除主節點的另一種方法是在其一個備份節點上對其執行手動故障轉移,併在該節點成為新主節點的備份節點之後刪除該節點。顯然,這在您想要減少集群中的主節點的實際數量時沒什麼用,在這種情況下,需要重新分片。
副本遷移
在Redis集群裡裡任何時間你都可以重新配置一個備份節點使其作為另一個主節點的從屬節點,使用下列命令:
CLUSTER REPLICATE <master-node-id>
但是,有一種特殊情況,您希望副本在沒有系統管理員幫助的情況下自動從一個主節點移動到另一個主節點。副本的自動重新配置稱為副本遷移,它能夠提高Redis集群的可靠性。
註意:您可以在Redis集群規範中閱讀副本遷移的詳細信息,這裡我們僅提供一些一般的想法以及您應該從中受益的信息。
在某些情況下,您可能想讓您的集群副本從一個主節點移動到另一個主節點的原因是,Redis集群通常具有與給定主節點的副本數量相同的故障容忍性。
例如,如果一個主節點及其副本同時失敗,則每個主節點都有一個副本的集群將無法繼續工作,這僅僅是因為沒有其他實例擁有與該主節點服務的相同的hash槽的副本。但是,儘管網路斷裂可能會同時隔離多個節點,但是許多其他類型的故障(例如單個節點本地的硬體或軟體故障)是非常值得註意的一類故障,這類故障不太可能同時發生,因此在每個主節點都有一個備份節點的集群中,如果該備份節點在凌晨4點被關閉,而主節點在凌晨6點被關閉。這仍然會導致集群無法運行。
為了提高系統的可靠性,我們可以選擇向每個主節點添加副本,但這成本很高。副本遷移允許將更多備份節點添加到少數幾個主節點中。因此,您有10個節點,每個節點有1個備份節點,總共20個實例。但是,比如您增加了3個實例作為某些主節點的備份節點,因此某些主節點將具有多個副本了。
使用副本遷移時,如果一個主節點不包含備份節點,則具有多個備份節點的主節點的副本將遷移到孤立的主節點。因此,當您的備份節點在上述示例中的凌晨4點關閉之後,另一個備份節點將接替它;當主節點在凌晨5點也發生故障時,另一個備份節點將被選舉成為主節點,以便集群可以繼續操作。
所以您應該瞭解哪些有關副本遷移的知識?
- 在某個時刻,集群會嘗試從具有最多副本數的主節點中選擇一個副本進行遷移。
- 為了從副本遷移中受益,您只需為集群中的單個主節點添加一些副本,不管是哪個主節點
- 有一個配置參數可控制副本遷移功能,稱為cluster-migration-barrier:您可
以在Redis集群隨附的示例redis.conf文件中瞭解有關此功能的更多信息。
參考


