
例如有這樣一個需求:業務方希望獲取司機實時更新的累計完單量,需保證收到完單事件後秒級更新。由於滴滴訂單量很大,單個司機的完單量從幾單到幾萬單不等,直接查詢底層存儲如MySQL、ElasticSearch等存儲,會對底層存儲造成很大查詢壓力,並且延時也較高,在高併發等情況下容易出現各種問題。在特征服務 ...
例如有這樣一個需求:業務方希望獲取司機實時更新的累計完單量,需保證收到完單事件後秒級更新。由於滴滴訂單量很大,單個司機的完單量從幾單到幾萬單不等,直接查詢底層存儲如MySQL、ElasticSearch等存儲,會對底層存儲造成很大查詢壓力,並且延時也較高,在高併發等情況下容易出現各種問題。在特征服務這邊採用批處理+流處理這樣的Lambda架構來實現這類需求,整個的數據流如下:
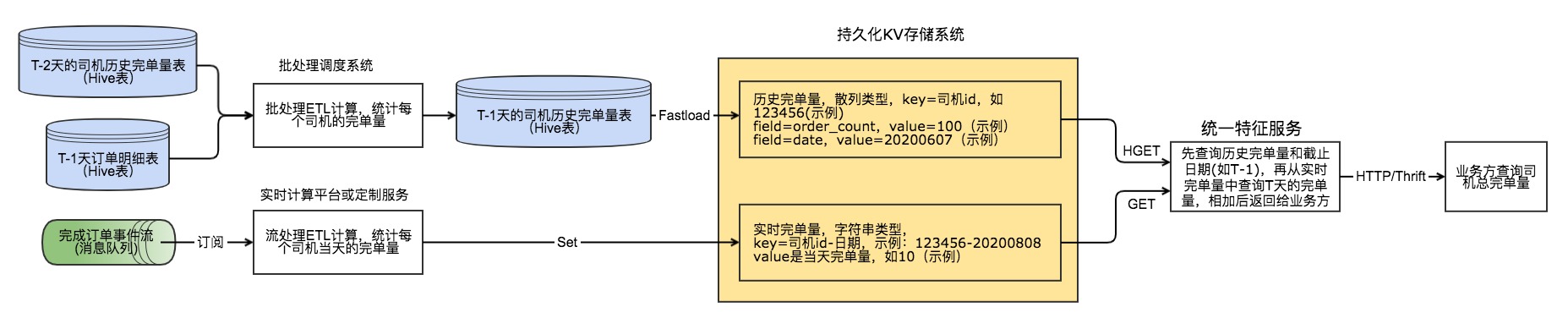
可以看到這是一個典型的Lambda架構,不瞭解的可以參考維基百科:Lambda architecture
在統計特征彙總歷史完單量和實時完單量,需要註意以下情況:當T-1天未準備就緒時,需要使用T-2天的歷史數據、T-1天實時數據、T天實時數據相加。舉例如下:
假設批處理計算司機歷史完單量的任務平均在上午6點完成並導入KV存儲系統。
- 在6月10日0到6時期間,計算邏輯如下:截止到6月8日(含)的歷史完單量 + 6月9日的實時完單量 + 6月10日的實時完單量。
- 在6月10日6到24時期間,計算邏輯如下:截止到6月9日(含)的歷史完單量 + 6月10日的實時完單量。


