
redis 主從複製 master 節點提供數據,也就是寫。slave 節點負責讀。 不是說master 分支不能讀數據,也能只是我們希望將讀寫進行分離。 slave 是不能寫數據的,只能處理讀請求 主從實現 客戶端 127.0.0.1:6379 伺服器 212.64.89.173:6379 方式一 ...
redis 主從複製
master 節點提供數據,也就是寫。slave 節點負責讀。
不是說master 分支不能讀數據,也能只是我們希望將讀寫進行分離。
slave 是不能寫數據的,只能處理讀請求
主從實現
客戶端 127.0.0.1:6379 伺服器 212.64.89.173:6379
方式一
客戶端發送請求同步命令
slaveof masterip masterport
slaveof 212.64.89.173 6379
方式二
客戶端啟動伺服器參數
redis-server --slaveof masterip masterport
redis-server --slaveof 212.64.89.173 6379
方式三
在客戶端的配置文件中寫入 slaveof 信息
redis.conf
slaveof 212.64.89.173 6379
註意 斷開主從鏈接方式: 客戶端執行 slaveof no one
設置鏈接密碼
server 端
服務啟動後設置
config set requierpass <password>
配置文件添加密碼
# redis.conf
requirepass <password>
client 端
命令設置密碼
auth <password>
配置文件設置密碼
masterauth <password>
啟動客戶端設置密碼
redis-cli -a <password>
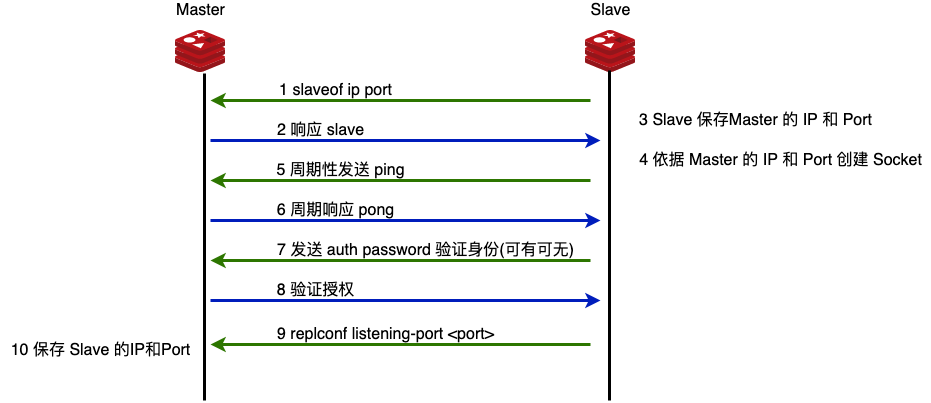
建立連接
建立鏈接的過程就是希望 master 和 slave 都保有對方的 IP 和 Port。
數據同步
數據的同步分兩部分,全量同步和增量同步,在增量同步結束後,master 應當保存Slave 同步數據的位置。

複製(積壓)緩衝區
它有兩部分組成 偏移量 + 位元組值
結構

創建
1 當啟動AOF 時就會創建 複製積壓緩衝區
2 當被選為 master 節點,必須創建積壓緩衝區
作用
保存所有的對數據修改或資料庫修改的指令,查詢指令不會被記錄。
數據源
所有的進入master 的對數據修改或資料庫修改的指令都會被填充到積壓緩衝區中。
偏移量
1 Master 和 Slave 都會記錄 offset 值, 每次複製都會對比offset 是否一致。如果一致,Master直接從 offset 處開始傳緩衝區數據,如果不一致,那麼Master將遵循 Slave 的offset 來傳。當然會保證命令是完整的。
2 Master 保存有多個 offset 而 Slave 僅保存自己的。
3 Master發送一次,記錄一次, Slave 接受一次記錄一次。
關於Master註意
1如果master 數據量過大,應該避免業務高峰期進行數據同步。避免造成 master 阻塞
2 數據緩衝區滿, 此時將會丟棄最早的記錄(FIFO),如果全量複製的時間開銷過大,則可能在開增量複製時候已經存在數據丟失,這會導致Master 和 Slave 數據不一致,為了保證一致性,必須開始新一輪的全量複製,完成後緩衝區又被填滿並存在丟棄,則會讓Slave進入死迴圈。
因此數據緩衝區要設置的大小合適(依具體情況而定)。
repl-backlog-size 1mb # 預設的大小為 1MB
3 master 單機記憶體不應該占用主機記憶體過多。一般的 50 ~ 70% 預留下 30% ~ 50%來進行bgsave 、 創建複製緩衝區、執行其他業務等。
關於Slave註意
1 為避免slave進行全量複製、部分複製時伺服器響應阻塞或數據不同步,建議關閉此期間的對外服務。
slave-server-stale-data yes|no
2 數據同步階段,master 發送給 slave 信息可以理解 master 是 slave 的一個客戶端,主動向slave發送命令。
3 多個slave同時對master請求數據同步,master發送的RDB文件增多,會對帶寬造成巨大衝擊,如果master寬頻不足,因此數據同步需要根據業務需求,適量錯峰。
4 slave過多時,應該對拓撲結構進行調整,由一主多從結構變為樹狀結構,中間結點即是master,也是slave。但是使用樹狀結構時,因為層級越深,數據同步時延越大,因此將強一致性的數據放在頂層節點,一致性稍弱的數據放在靠底層的節點。
命令傳播
當master資料庫狀態被修改後,導致主從伺服器資料庫狀態不一致,此時需要讓主從數據同步到一致的狀態,同步的動作成為命令傳播
master將接受到的數據變更命令發送給slave,slave接受命令後執行命令。
網路閃斷閃連 忽略
短時間網路中斷 部分複製
長時間網路中斷 全量複製
伺服器運行ID(runid)
每台伺服器每次運行都會產生的身份識別碼,同一個伺服器多次運行產生的runid是不一樣的。
形式:runid 由 40 個字元組成 一般是16進位的字元串
info server
run_id:409b6e9ea2e5c32958de8f365711598c98489f13
心跳機制
master
指令 PING
周期 repl-ping-slave-period 預設是 10s
作用 判斷 slave 是否線上
查詢 INFO replication 獲取最後一次 slave 連接時間間隔 lag = 0 / 1 屬於正常
slave
指令 REPLCONF{offset}
周期: 1s
作用1: 彙報自己的複製偏移量 獲取最新的數據變更指令
作用2: 判斷 master 是否存活
心跳註意事項
當 salve多數掉線 或者網路延時過高時,master 會拒絕所有的同步信息。
min-slaves-to-write 2 # 最小的 slave 數量
min-slaves-max-lag 8 # 最長的
當 slave 的數量小於2 ,或者所有的時延都大於等於 8 時,會強 關閉 master 的血功能來停止數據同步。
Slave 的數量和延時由REPLCONF{offset} 命令確認。
完整的主從複製流程

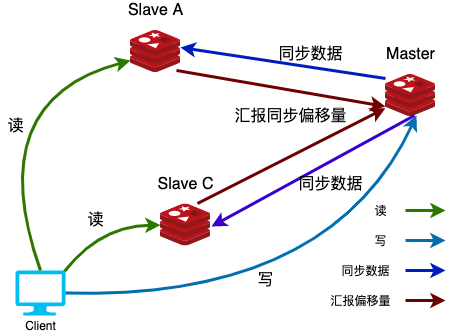
讀寫分離
在redis主從架構中,Master節點負責處理寫請求,Slave節點只處理讀請求。對於寫請求少,讀請求多的場景,例如電商詳情頁,通過這種讀寫分離的操作可以大幅提高併發量,通過增加redis從節點的數量可以使得redis的QPS達到10W+。
負載均衡
基於主從結構,配合讀寫分離,由slave分擔master負載,並根據需求的變化,改變slave的數量,通過多個從節點分擔數據讀取負載,大大提高Redis伺服器併發量與數據吞吐量
故障恢復
當master出現問題時,由slave提供服務,實現快速的故障恢復
數據冗餘
實現數據熱備份,時持久化之外的一種數據冗餘方式
高可用基石
基於主從複製,構建哨兵模式與集群,實現redis 的高可用方案。


