
桔妹導讀:滴滴HBase團隊日前完成了0.98版本 → 1.4.8版本滾動升級,用戶無感知。新版本為我們帶來了豐富的新特性,在性能、穩定性與易用性方便也均有很大提升。我們將整個升級過程中面臨的挑戰、進行的思考以及解決的問題總結成文,希望對大家有所幫助。 1. 背景 目前HBase服務在我司共有國內、 ...

桔妹導讀:滴滴HBase團隊日前完成了0.98版本 -> 1.4.8版本滾動升級,用戶無感知。新版本為我們帶來了豐富的新特性,在性能、穩定性與易用性方便也均有很大提升。我們將整個升級過程中面臨的挑戰、進行的思考以及解決的問題總結成文,希望對大家有所幫助。
1. 背景
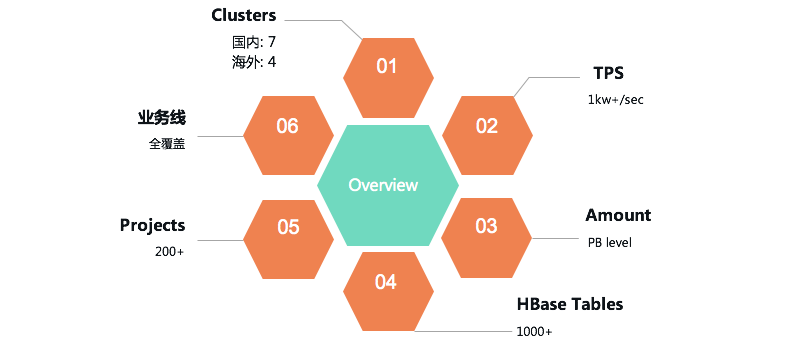
目前HBase服務在我司共有國內、海外共計11個集群,總吞吐超過1kw+/s,服務著地圖、普惠、車服、引擎、金融等幾乎全部部門與業務線。
然而有一個問題持續困擾著我們:版本較社區落後較多——HBase線上集群使用0.98版本,而社區目前最新的release版本為2.3。這為我們的工作帶來了很多額外的掣肘與負擔,主要包括以下幾點:
- 新特性引入成本極高:
0.98版本可以算是HBase第一個穩定版本,但過於老舊,社區已經不再維護。想要backport新特性難度越來越大。 - 自研patch維護成本較高:
我們基於0.98版本有數十個大大小小的自研patch,涵蓋了從label分組、ACL鑒權等大的feature到監控體系建設、審計日誌優化等Improvement以及各種bug fix。這些patch或是新版本中已支持但和我們實現有差異,或是由於版本差異過大無法合入社區,而且隨著時間線的拉長,這種問題只會進一步惡化。 - 上層組件對於HBase存在一定需求:
得益於活躍的HBase生態圈,目前我們的用戶使用形態也比較豐富,OLAP(Kylin)、時空索引(GeoMesa)、時序(OpenTSDB)、圖(JanusGraph)等等場景不一而足。然而這些上層引擎無一例外,最新版本沒有任何一款是依賴0.98版本HBase的。
因此對於HBase團隊而言,升級迫在眉睫刻不容緩。
2.挑戰
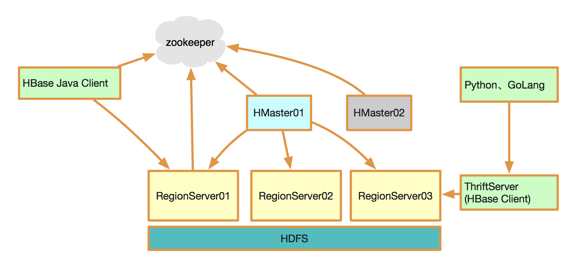
首先簡單介紹一下HBase的架構。HBase是一個典型的主從結構——主備Master用於管理集群;RegionServer用於響應處理用戶讀寫請求;使用ZooKeeper保障集群內的一致性;節點間通過RPC通信;底層數據文件HFile存儲於HDFS中。
此外HBase具有相當豐富的上下游生態,從以StreamingSQL為代表的實時任務到Spark、MR等批處理任務,通過下圖可以得窺一二:
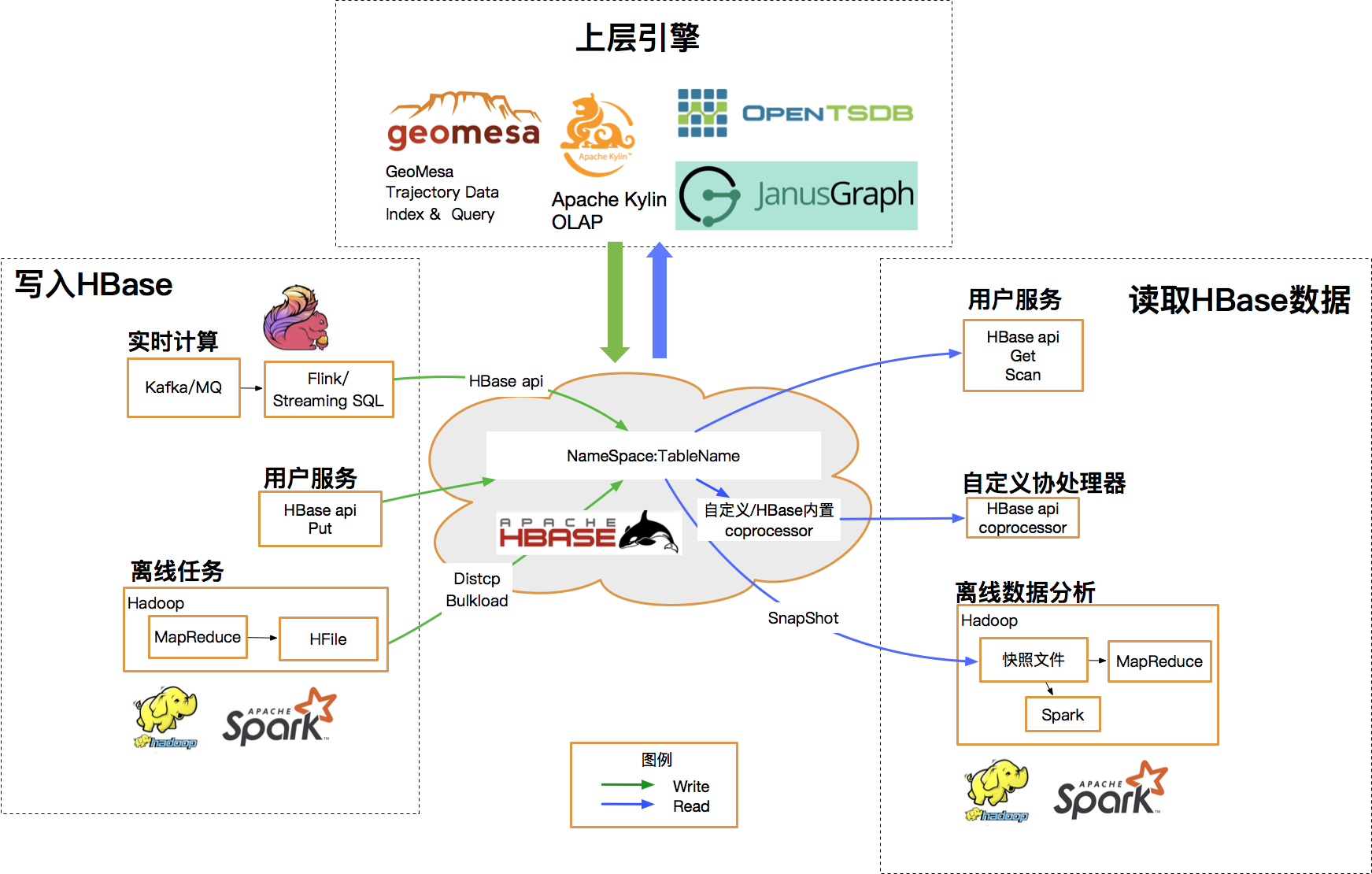
基於以上對集群架構和上下游生態的梳理,可以明確升級過程中我們主要面臨的挑戰有:
- RPC介面相容性問題:
升級不可能一蹴而就,因此我們需要確保所有RPC通信介面新舊版本完美相容。 - HFile相容性問題;
不同版本中底層文件的數據格式有差異。1.4.8版本預設使用HFile v3,幸運的是0.98版本雖然使用HFile v2,但已經可以相容v3。這樣我們就不需要再額外backport相關patch到0.98版本。此外也是基於這方面的因素,官方文檔中說明0.98版本想要升級到2.x版本,必須以1.x版本作為過渡——這也是我們本次升級選擇1.4.8版本的原因。 - 自有patch相容性問題:
如上文所述,我們需要全量梳理自研的數十個patch——高版本是否有替代方案、替代方案是否相容、是否需要移植到新版本、移植後的功能/性能/相容性測試等。 - 上下游相容性問題:
這一點大家看上圖就好不需再贅述,每一種引擎的應用都需確保完全相容。 - 可能引入的新問題:
HBase的社區release版本迄今仍然非常活躍,但同時這也意味著可能存在很多潛藏的問題(事實上我們在升級過程中也遇到了,解決了並反哺給社區)——這一點其實沒有什麼太好的辦法,只能要求我們隨時緊密跟進社區,洞察新進展,即時發現問題修複問題。
基於以上這些挑戰點,其實不難得出一個結論:我們需要設計並實施大量的前置準備工作以保證升級過程的可靠性,但這並不是什麼壞消息,因為只要我們的準備工作足夠細緻完善,順利升級的把握和信心也就越強——這個思路在我們今後的工作中也同樣適用。
下麵簡單列舉了我們完成的準備工作:
- Release Note review
- 自研patch移植與測試
- 基礎功能測試、性能測試
- 高階功能測試(Bulkload,Snapshot,Replication,Coprocessor等)
- 社區後續小版本patch梳理跟進(截止目前實際合入的有100餘個)
- 跨版本相容性測試、RPC介面相容性梳理
- 全量測試集制定與實施,涵蓋HBase ,Phoenix,GeoMesa,OpenTSDB,Janusgraph等所有使用場景
- 軟體包及配置文件準備
3. 升級方案
升級方案主要有兩種:新建集群+數據遷移 和 滾動升級。
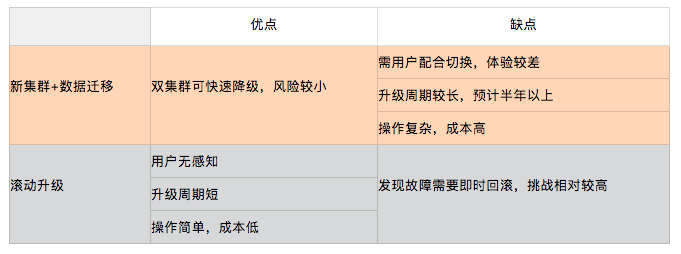
實際上滾動升級的方案一定是最優選,主要是出於對“release版本仍然不夠穩定”的擔憂,我們一度有所猶豫。但最終基於“充分的準備與測試”帶給我們的信心,最終我們仍然選擇了滾動升級。
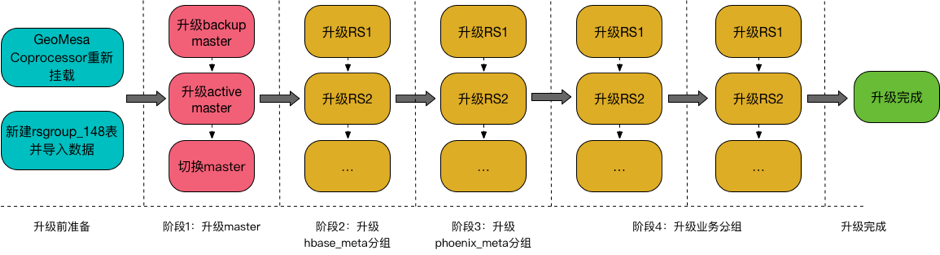
簡單說明滾動升級的大致步驟:
- 解決相容性問題,主要體現在新建rsgroup元數據表並重寫數據、
- 掛載新的coprocessor等;
- 升級master節點;
- 升級meta分組;
- 依次升級業務分組;
4. 實操及問題
我們從19年下半年啟動了這一輪滾動升級的調研與準備,今年3月下旬正式開始線上操作,截至5月初已完成了國內外共計9個集群的升級工作,用戶無感知。
在此期間我們也遇到了不少未解問題,這裡摘取一個Critical問題做簡單介紹:
region split過程中疊加RS宕機引發數據丟失:
region split是一個相當複雜的事務過程,大體可分為以下幾步:
- RegionServer開始執行split事務,在ZK region-in-transition下創建該region的節點,標記為SPLIT;
- Master監聽到新的split節點,開始做一些初始化工作,並修改記憶體狀態,完成後將節點狀態改為SPLITING;
- RS監聽到節點狀態變為SPLITING,開始正式執行split——關閉父region、創建子region文件夾並添加引用文件、修改meta表記錄兩個子region並將父region下線;
- 子region上線;
當父region下線、子region還未正式上線時RegionServer宕機,master上的ServerCrashProcedure線程開始進行回滾,會將子region刪除;此外master上還有一個CatalogJanitor線程做數據清理,正常split過程中由於ZK上存在對應節點,這個線程會被阻塞;然而由於RS宕機,臨時節點也隨之消失,該線程正常工作,判斷meta表中父region已經下線,從而將父region刪除——至此父子region皆被刪除,導致數據丟失。
修複方案已提交社區:HBASE-23693
其它patch list:
- HBASE-22620 修複replication znode積壓問題;
- HBASE-21964 支持按Throttle Type取消quota設置;
- HBASE-24401 修複 hbase.server.keyvalue.maxsize=0 時append操作失敗的問題;
- HBASE-24184 修複只使用simple ACL時snapshot相關操作的鑒權問題;
- HBASE-24485 Backport,優化堆外記憶體初始化時間;
- HBASE-24501 Backport,去除ByteBufferArray中非必要的鎖;
- HBASE-24453 Backport,修複挪動表分組時缺少校驗邏輯的問題;
5. 總結
本次升級工作從立項到完結耗時近一年,能夠成功完成非常開心。一方面本次升級極大拉進了內部版本與社區release版本的距離,為更加良性的版本迭代及社區互動夯實了基礎;另一方面新版本引入了諸多新特性,在穩定性、易用性方面都為我們帶來了更為廣闊的成長空間;更重要的是在這個過程中我們自身也沉澱出了一套系統的工作思路與方法論,期待後續可以更好的為業務賦能,為公司創造價值。
作者簡介

滴滴資深貓奴,專註於HBase內核研發,滴滴HBase服務及上下游生態的建設與維護。

**歡迎關註滴滴技術公眾號!
本文由博客群發一文多發等運營工具平臺 OpenWrite 發佈


