
消息中間件作為分散式系統的重要成員,各大公司及開源均有許多解決方案。目前主流的開源解決方案包括RabbitMQ、RocketMQ、Kafka、ActiveMQ等。消息這個東西說簡單也簡單,說難也難。簡單之處在於好用方便,接入簡單使用簡單,非同步操作能夠解耦系統間的依賴,同時失敗後也能夠追溯重試。難的地 ...

消息中間件作為分散式系統的重要成員,各大公司及開源均有許多解決方案。目前主流的開源解決方案包括RabbitMQ、RocketMQ、Kafka、ActiveMQ等。消息這個東西說簡單也簡單,說難也難。簡單之處在於好用方便,接入簡單使用簡單,非同步操作能夠解耦系統間的依賴,同時失敗後也能夠追溯重試。難的地方在於,設計一套可以支撐業務的消息機制,並提供高可用架構,解決消息存儲、消息重試、消息隊列的負載均衡等一系列問題。然而難也不代表沒有方法或者“套路”,熟悉一下原理與實現,多看幾個框架的源碼後多總結勢必能找出一些共性。
消息框架大同小異,熟練掌握其原理、工作機制是必要的。就拿用的比較多的RocketMQ為引,來說說消息引擎的設計與實現。阿裡的消息引擎經過了從Notify到Napoli、再到MetaQ三代的發展,現在已經非常成熟,在不同部門的代碼中現在沒準都還可以從代碼里看到這一系列演進過程。當前的Apache RocketMQ 就是阿裡將MetaQ項目捐贈給了Apache基金會,而內部還是沿用MetaQ的名稱。
首先詮釋幾個消息相關的基本概念。
- 每個消息隊列都必須建立一個Topic。
- 消息可以分組,每個消息隊列都至少需要一個生產者Producer和一個消費者Consumer。生產者生產發送消息,消費者接收消費消息。
- 每個消費者和生產者都會分批提個ID。
RocketMQ 系統架構
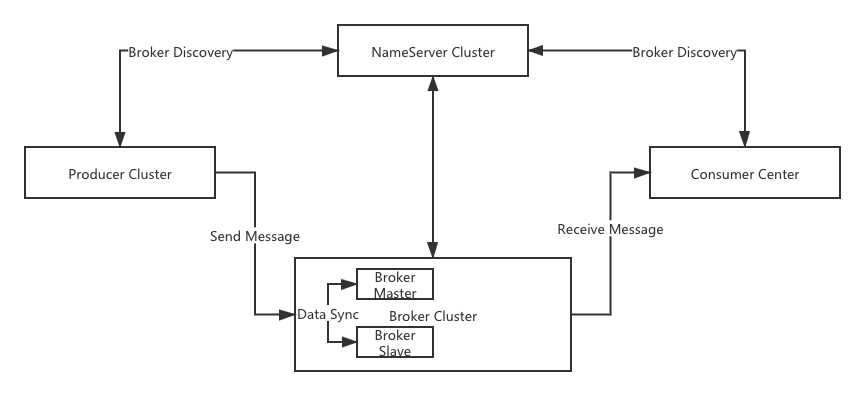
接下來再來看看RocketMQ的架構,如圖所示,簡要描述一下幾種角色及作用。
- NameServer
- NameServer是消息Topic的註冊中心,用於發現和管理消息生產者、消費者、及路由關係。
- Broker
- 消息存儲與轉發的中轉站,使用隊列機制管理數據存儲。Broker中會存儲多份消息數據進行容錯,以Master/Slave的架構保證系統的高可用,Broker中可以部署單個或多個Master。單個Master的場景,Master掛掉後,Producer新產生的消息無法被消費,但已經發送到Broker的消息,由於Slave節點的存在,還能繼續被Consumer所消費;如果部署多個Master則系統能能正常運轉。
- 另外,Broker中的Master和Slave不是像Zookeeper集群中用選舉機制進行確定,而是固定的配置,這也是在高可用場景需要部署多個Master的原因。
- 生產者將消息發送到Broker中後,Broker會將消息寫到本地的CommitLog文件中,保存消息。
- Producer
- 生產者會和NameServer集群中某一節點建立長鏈接,定時從NamerServeri獲取Topic路由信息,並且和Broker建立心跳。
- Consumer
- 消費者需要給生產者一個明確的消費成功的回應,MetaQ才會認為消費成功,否則失敗。失敗後,RocketMQ會將消息重新發回Broker,在指定的延遲時間內進行重試,當重試達到一定的次數後(預設16次),MetaQ則認為此消息不能被消費,消息會被投遞到死信隊列。
這個架構看其實是否很熟悉?好像接觸過的一些分散式系統的架構和這個長的都比較像是吧,甚至只要裡面框圖的角色稍微換換就能變成另外一個框架的介紹,比如Dubbo/Redis...。
並且在RocketMQ架構設計中,要解決的問題與其他分散式框架也可以觸類旁通。Master/Slave機制,天然的讀寫分離方式都是分散式高可用系統的典型解決方案。
負載均衡
負載均衡是消息框架需要解決的又一個重要問題。當系統中生產者生產了大量消息,而消費者有多個或多台機器時,就需要平衡負載,讓消息均分地被消費者進行消費。目前RocketMQ中使用了多種負載均衡演算法。主要有以下幾種,靜態配置由於過於簡單,直接為消費者配置需要消費的隊列,因此直接忽略。
- 求平均數法
- 環形隊列法
- 一致Hash演算法
- Machine Room演算法
- 靜態配置
來看一下源碼,RocketMQ內部對以上負載均衡演算法均有實現,並定義了一個介面 AllocateMessageQueueStrategy,採用策略模式,每種負載均衡演算法都依靠實現這個介面實現,在運行中,會獲取這個介面的實例,從而動態判斷到底採用的是哪種負載均衡演算法。
1 public interface AllocateMessageQueueStrategy { 2 3 /** 4 * Allocating by consumer id 5 * 6 * @param consumerGroup current consumer group 7 * @param currentCID current consumer id 8 * @param mqAll message queue set in current topic 9 * @param cidAll consumer set in current consumer group 10 * @return The allocate result of given strategy 11 */ 12 List<MessageQueue> allocate( 13 final String consumerGroup, 14 final String currentCID, 15 final List<MessageQueue> mqAll, 16 final List<String> cidAll 17 ); 18 19 /** 20 * Algorithm name 21 * 22 * @return The strategy name 23 */ 24 String getName(); 25 }
1. 求平均數法
顧名思義,就是根據消息隊列的數量和消費者的數量,求出單個消費者上應該負擔的平均消費隊列數,然後根據消費者的ID,按照取模的方式將消息隊列分配到指定的consumer上。具體代碼可以去Github上找,截取核心演算法代碼如下, mqAll就是消息隊列的結構,是一個MessageQueue的List,cidAll是消費者ID的列表,也是一個List。考慮mqAll和cidAll固定時以及變化時,當前消費者節點會從隊列中獲取到哪個隊列中的消息,比如當 averageSize 大於1時,這時每個消費者上的消息隊列就不止一個,而分配在每個消費者的上的隊列的ID是連續的。
1 int index = cidAll.indexOf(currentCID); 2 int mod = mqAll.size() % cidAll.size(); 3 int averageSize = 4 mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size() 5 + 1 : mqAll.size() / cidAll.size()); 6 int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod; 7 int range = Math.min(averageSize, mqAll.size() - startIndex); 8 for (int i = 0; i < range; i++) { 9 result.add(mqAll.get((startIndex + i) % mqAll.size())); 10 } 11 return result;
2. 環形平均法
這種演算法更為簡單。首先獲取當前消費者在整個列表中的下標index,直接用求餘方法得到當前消費者應該處理的消息隊列。註意mqAll的size和cidAll的size可以是任意的。
- 當ciAll.size() == mqAll.size() 時,該演算法就是類似hashtable的求餘分桶。
- 當ciAll.size() > mqAll.size() 時,那麼多出的消費者上並不能獲取到消費的隊列,只有部分消費者能夠獲取到消息隊列並執行,相當於在消費者資源充足的情況下,由於隊列數少,所以使用其中一部分消費者就能滿足需求,不用額外的開銷。
- 當ciAll.size() < mqAll.size() 時,這樣每個消費者上需要負載的隊列數就超過了1個,並且區別於直接求平均的方式,分配在每個消費者上的消費隊列不是連續的,而是有一定步長的間隔。
1 int index = cidAll.indexOf(currentCID); 2 for (int i = index; i < mqAll.size(); i++) { 3 if (i % cidAll.size() == index) { 4 result.add(mqAll.get(i)); 5 } 6 } 7 return result;
3. 一致Hash演算法
迴圈所有需要消費的隊列,根據隊列toString後的hash值計算出處理當前隊列的最近節點並分配給該節點。routeNode 中方法稍微複雜一些,有時間建議細看,這裡就只說功能。
1 Collection<ClientNode> cidNodes = new ArrayList<ClientNode>(); 2 for (String cid : cidAll) { 3 cidNodes.add(new ClientNode(cid)); 4 } 5 6 final ConsistentHashRouter<ClientNode> router; //for building hash ring 7 if (customHashFunction != null) { 8 router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt, customHashFunction); 9 } else { 10 router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt); 11 } 12 13 List<MessageQueue> results = new ArrayList<MessageQueue>(); 14 for (MessageQueue mq : mqAll) { 15 ClientNode clientNode = router.routeNode(mq.toString()); 16 if (clientNode != null && currentCID.equals(clientNode.getKey())) { 17 results.add(mq); 18 } 19 } 20 21 return results;
4. Machine Room演算法
基於機房的Hash演算法。這個命名看起來很詐唬,其實和上面的普通求餘演算法是一樣的,只不過多了個配置和過濾,為了把這個說清楚就把源碼貼全一點。可以看到在這個演算法的實現類中多了一個成員 consumeridcs,這個就是consumer id的一個集合,按照一定的約定,預先給broker命名,例如us@metaq4,然後給不同集群配置不同的consumeridcs,從而實現不同機房處理不同消息隊列的能力。
1 /* 2 * Licensed to the Apache Software Foundation (ASF) under one or more 3 * contributor license agreements. See the NOTICE file distributed with 4 * this work for additional information regarding copyright ownership. 5 * The ASF licenses this file to You under the Apache License, Version 2.0 6 * (the "License"); you may not use this file except in compliance with 7 * the License. You may obtain a copy of the License at 8 * 9 * http://www.apache.org/licenses/LICENSE-2.0 10 * 11 * Unless required by applicable law or agreed to in writing, software 12 * distributed under the License is distributed on an "AS IS" BASIS, 13 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 14 * See the License for the specific language governing permissions and 15 * limitations under the License. 16 */ 17 package com.aliyun.openservices.shade.com.alibaba.rocketmq.client.consumer.rebalance; 18 19 import java.util.ArrayList; 20 import java.util.List; 21 import java.util.Set; 22 import com.aliyun.openservices.shade.com.alibaba.rocketmq.client.consumer.AllocateMessageQueueStrategy; 23 import com.aliyun.openservices.shade.com.alibaba.rocketmq.common.message.MessageQueue; 24 25 /** 26 * Computer room Hashing queue algorithm, such as Alipay logic room 27 */ 28 public class AllocateMessageQueueByMachineRoom implements AllocateMessageQueueStrategy { 29 private Set<String> consumeridcs; 30 31 @Override 32 public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, 33 List<String> cidAll) { 34 List<MessageQueue> result = new ArrayList<MessageQueue>(); 35 int currentIndex = cidAll.indexOf(currentCID); 36 if (currentIndex < 0) { 37 return result; 38 } 39 List<MessageQueue> premqAll = new ArrayList<MessageQueue>(); 40 for (MessageQueue mq : mqAll) { 41 String[] temp = mq.getBrokerName().split("@"); 42 if (temp.length == 2 && consumeridcs.contains(temp[0])) { 43 premqAll.add(mq); 44 } 45 } 46 47 int mod = premqAll.size() / cidAll.size(); 48 int rem = premqAll.size() % cidAll.size(); 49 int startIndex = mod * currentIndex; 50 int endIndex = startIndex + mod; 51 for (int i = startIndex; i < endIndex; i++) { 52 result.add(mqAll.get(i)); 53 } 54 if (rem > currentIndex) { 55 result.add(premqAll.get(currentIndex + mod * cidAll.size())); 56 } 57 return result; 58 } 59 60 @Override 61 public String getName() { 62 return "MACHINE_ROOM"; 63 } 64 65 public Set<String> getConsumeridcs() { 66 return consumeridcs; 67 } 68 69 public void setConsumeridcs(Set<String> consumeridcs) { 70 this.consumeridcs = consumeridcs; 71 } 72 }
由於近些年阿裡海外業務的擴展和投入,RocketMQ 等中間件對常見的海外業務場景的支持也更加健全。典型的場景包括跨單元消費以及消息路由。跨單元消費是比較好實現的,就是在consumer中增加一個配置,指定接收消息的來源單元,RocketMQ內部會完成客戶端從指定單元拉取消息的工作。而全球消息路由則是需要一些公共資源,消息的發送方只能將消息發送到一個指定單元/機房,然後將消息路由到另外指定的單元,consumer部署在指定單元。區別在於一個配置在客戶端,一個配置在服務端。
總結
從RocketMQ的設計、原理以及用過的個人用過的其他分散式框架上看,典型的分散式系統在設計中無外乎要解決的就是以下幾點,RocketMQ全都用上了。
- 服務的註冊和發現。一般會有一個統一的註冊中心進行管理維護。
- 服務的提供方和使用方間的通信,可以是非同步也可以是同步,例如dubbo服務同步服務,而消息類型就是非同步通信。
- HA——高可用架構。八字決 ———— “主從同步,讀寫分離”。 要再加一句的話可以是“異地多活”。
- 負載均衡。典型的負載均衡演算法在文章內容裡面已經列出好幾種了,常用的基本也就這些。
當然消息框架設計中用到的套路遠不止這些,包括如何保證消息消費的順序性、消費者和服務端通信、以及消息持久化等問題也是難點和重點,同樣,分散式緩存系統也需要解決這些問題,先寫到這裡,要完全理解並自己設計一個這樣的框架難度還是相當大的。


