
什麼叫大數據,“大”,說的並不僅是數據的“多”!不能用數據到了多少TB ,多少PB 來說。 對於大數據,可以用四個詞來表示:大量,多樣,實時,不確定。 也就是數據的量龐大,數據的種類繁雜多樣話,數據的變化飛快,數據的真假存疑。 大量:這個大家都知道,想百度,淘寶,騰訊,Facebook,Twitte ...
什麼叫大數據,“大”,說的並不僅是數據的“多”!不能用數據到了多少TB ,多少PB 來說。
對於大數據,可以用四個詞來表示:大量,多樣,實時,不確定。
也就是數據的量龐大,數據的種類繁雜多樣話,數據的變化飛快,數據的真假存疑。
大量:這個大家都知道,想百度,淘寶,騰訊,Facebook,Twitter等網站上的一些信息,這肯定算是大數據了,都要存儲下來。
多樣:數據的多樣性,是說數據可能是結構型的數據,也可能是非結構行的文本,圖片,視頻,語音,日誌,郵件等。
實時:大數據需要快速的,實時的進行處理。如果說對時間要求低,那弄幾個機器,對小數據進行處理,等個十天半月的出來結果,這樣也沒有什麼意義了。
不確定: 數據是存在真偽的,各種各樣的數據,有的有用,有的沒用。很難辨析。
根據以上的特點,我們需要一個東西,來:
1.存儲大量數據
2.快速的處理大量數據
3.從大量數據中進行分析
於是就有了這樣一個模型hadoop。
一.什麼是hadoop?
1.Hadoop是Apache旗下的一套開源軟體平臺,是用來分析和處理大數據的軟體平臺。
2.Hadoop提供的功能:利用伺服器集群,根據用戶的自定義業務邏輯, 對海量數據進行分散式處理。
3.Hadoop的核心組件:由底層往上分別是 HDFS、Yarn、MapReduce。
4.廣義上來說,Hadoop通常指的是指一個更廣泛的概念->Hadoop生態 圈。
5.雲計算是分散式計算、並行計算、網格計算、多核計算、網路存儲、虛 擬化、負載均衡等傳統電腦技術和互聯網技術融合發展的產物。藉助 IaaS(基礎設施即服務)、PaaS(平臺即服務)、SaaS(軟體即服務)等業 務模式,把強大的計算能力提供給終端用戶。
6.現階段,雲計算的兩大底層支撐技術為虛擬化和大數據技術。
7.HADOOP則是雲計算的PaaS層的解決方案之一,並不等同於PaaS,更不等同於雲計算本身。
8.HADOOP應用於數據服務基礎平臺建設。
9.HADOOP用於用戶畫像。
10.HADOOP用於網站點擊流日誌數據挖掘
二.Hadoop的生態圈和核心組件

這就相當於一個生態系統,或者可以看成一個操作系統XP,win7,win10
HDFS和MapReduce為操作系統的核心,Hive,Pig,Mathout,Zookeeper,Flume,Sqoop,HBase等,都是操作系統上的一些軟體,或應用。
核心組件:HDFS(分散式文件系統)、YARN(集群資源管理系統)、MapReduce(分散式計算框架)
1.HDFS: 分散式文件存儲系統(Hadoop Distributed File System)
HDFS是塊級別的分散式文件存儲系統。是hadoop中數據存儲管理的基礎,具有高度容錯性,能檢測和應對硬體故障。
包含四個部分:HDFS Client、NameCode(nn)、DataNode(dn)、Secondary NameCode(2nn)
HDFS Client:就是客戶端。1、提供一些命令來管理、訪問 HDFS,比如啟動或者關閉HDFS。
2、與 DataNode 交互,讀取或者寫入數據;讀取時,要與 NameNode 交互,獲取文件的位置信息;寫入 HDFS 的時候,Client 將文件切分成 一個一個的Block,然後進行存儲。
NameCode(nn):元數據節點,存儲文件的元數據。如文件名、文件目錄結構,文件屬性(生成時間、副本數、文件許可權),以及每個文件的塊列表和塊所在得到DataNode等;管理HDFS的名稱空間和數據塊映射信息,配置副本策略,處理客戶端請求;
它是描述數據的數據,相當於圖書館的檢索系統。
DataNode(dn):數據節點,在本地文件系統存儲文件塊數據,以及塊數據的校驗和。
存儲實際的數據,彙報存儲信息給namenode,相當於書櫃。
Secondary NameCode(2nn):用來監控HDFS狀態的輔助後臺程式,每隔一段時間獲取HDFS元數據的快照。輔助namenode,分擔其工作量:定期合併fsimage和fsedits,推送給namenode。

從圖上來看,HDFS的簡單原理。
Rack1,Rack2,Rack3是三個機架;
1,2,3,4,5,6,7,8,9,10,11,12 是機架上的十二台伺服器。
Block A, Block B, Block C為三個信息塊,也就是要存的數據。
從整體佈局上來看,信息塊被分配到機架上。看似很均勻。這樣分配的目的,就是備份,防止某一個機器宕機後,單點故障的發生。
HDFS有很多特點:
① 保存多個副本,且提供容錯機制,副本丟失或宕機自動恢復。預設存3份。
② 運行在廉價的機器上。
③ 適合大數據的處理。多大?多小?HDFS預設會將文件分割成block,64M為1個block。然後將block按鍵值對存儲在HDFS上,並將鍵值對的映射存到記憶體中。如果小文件太多,那記憶體的負擔會很重。(從2.7.3版本開始,官方關於Data Blocks 的說明中,block size由64 MB變成了128 MB的。)
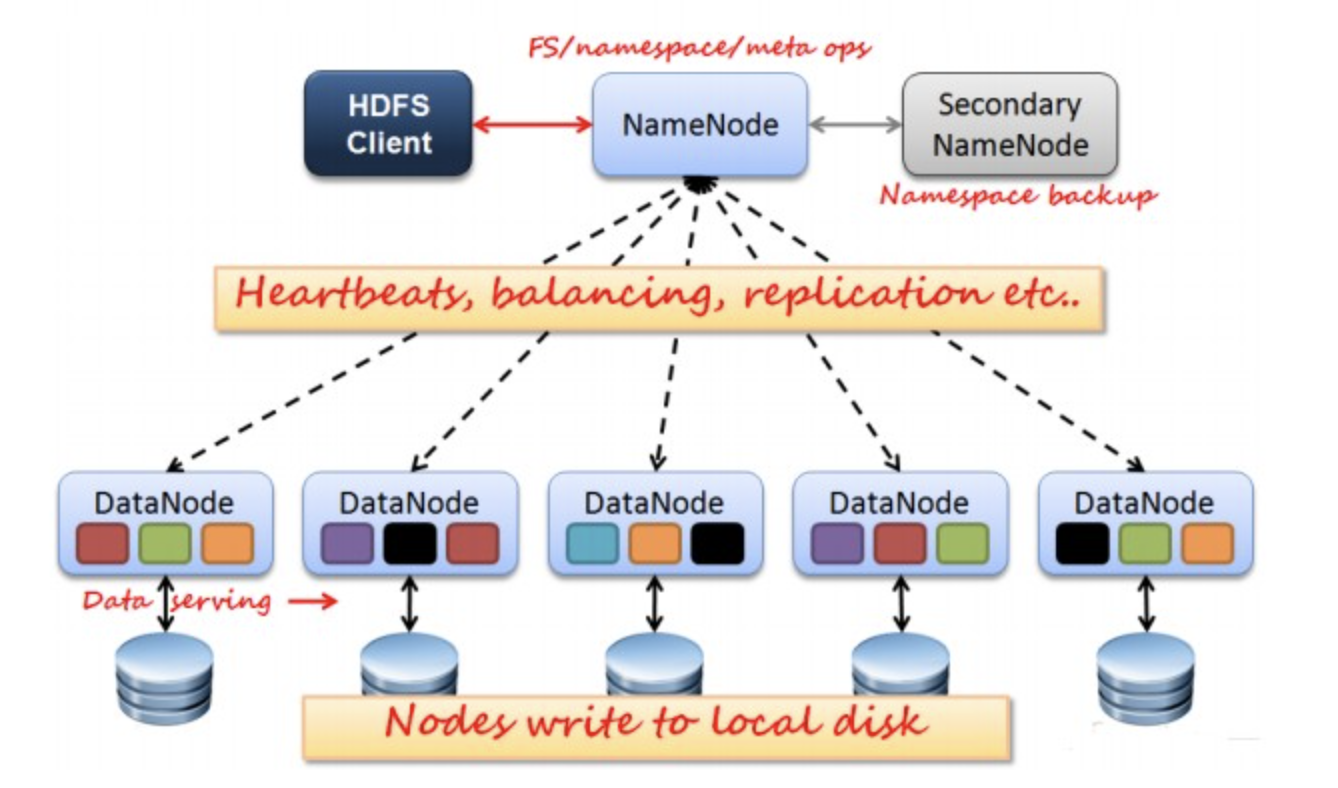
如上圖所示,HDFS也是按照Master和Slave的結構。分NameNode、SecondaryNameNode、DataNode這幾個角色。
HDFS Client:就是客戶端。
1、提供一些命令來管理、訪問 HDFS,比如啟動或者關閉HDFS。
2、與 DataNode 交互,讀取或者寫入數據;讀取時,要與NameNode 交互,獲取文件的位置信息;寫入 HDFS 的時候,Client 將文件切分成 一個一個的Block,然後進行存儲。
NameNode:是Master節點,是大領導。管理數據塊映射;處理客戶端的讀寫請求;配置副本策略;管理HDFS的名稱空間;
SecondaryNameNode:是一個小弟,分擔大哥namenode的工作量;是NameNode的冷備份;合併fsimage和fsedits然後再發給namenode。
DataNode:Slave節點,奴隸,幹活的。負責存儲client發來的數據塊block;執行數據塊的讀寫操作。
熱備份:b是a的熱備份,如果a壞掉。那麼b馬上運行代替a的工作。
冷備份:b是a的冷備份,如果a壞掉。那麼b不能馬上代替a工作。但是b上存儲a的一些信息,減少a壞掉之後的損失。
fsimage:元數據鏡像文件(文件系統的目錄樹。)
edits:元數據的操作日誌(針對文件系統做的修改操作記錄)
namenode記憶體中存儲的是=fsimage+edits。
SecondaryNameNode負責定時預設1小時,從namenode上,獲取fsimage和edits來進行合併,然後再發送給namenode。減少namenode的工作量。
工作原理:
寫操作
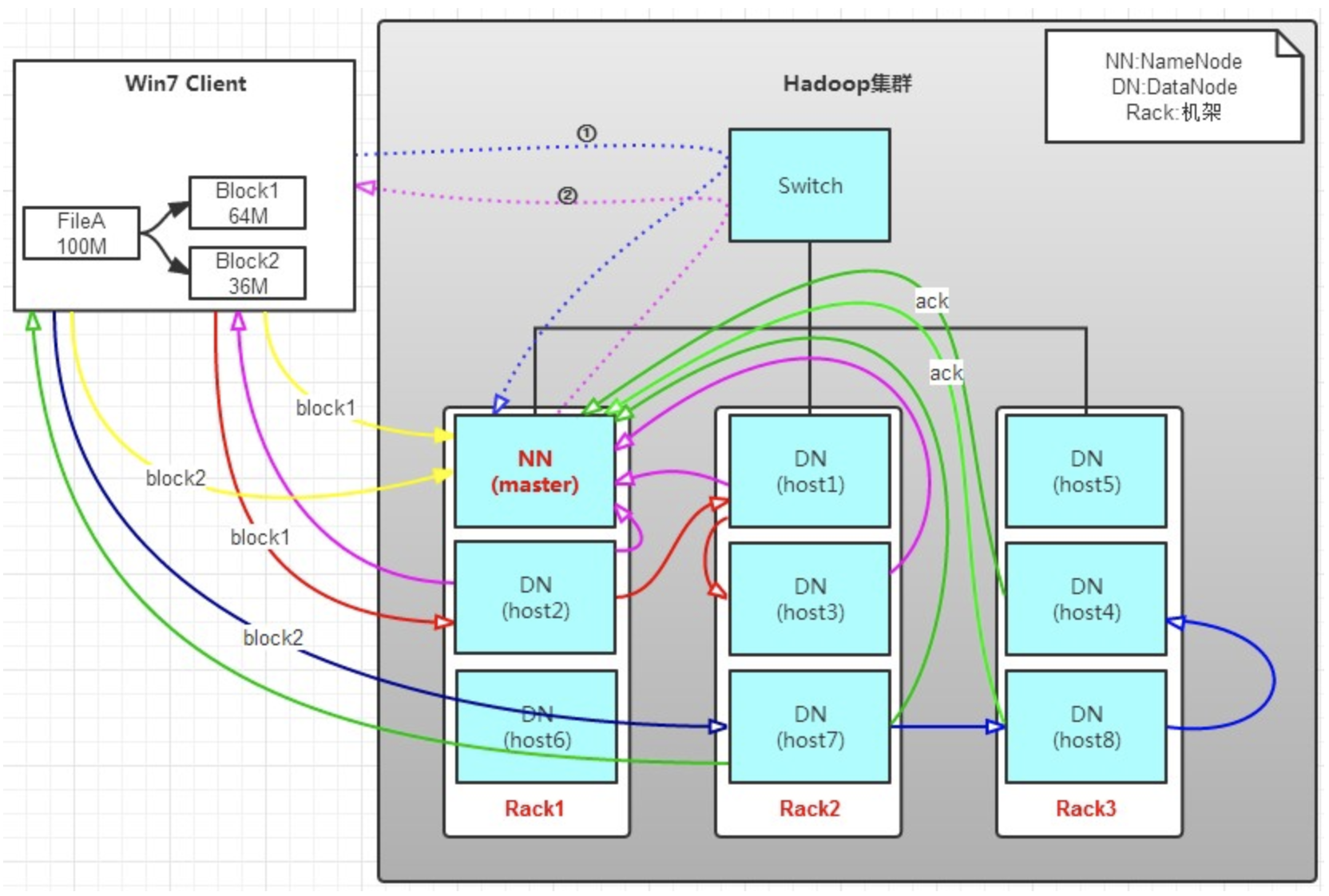
有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按預設配置。
HDFS分佈在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode發送寫數據請求,如圖藍色虛線①------>。
c. NameNode節點,記錄block信息。並返回可用的DataNode,如粉色虛線②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode發送block1;發送過程是以流式寫入。
流式寫入過程,
1>將64M的block1按64k的package劃分;
2>然後將第一個package發送給host2;
3>host2接收完後,將第一個package發送給host1,同時client想host2發送第二個package;
4>host1接收完第一個package後,發送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1發送完畢。
6>host2,host1,host3向NameNode,host2向Client發送通知,說“消息發送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的消息後,向namenode發送消息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>發送完block1後,再向host7,host8,host4發送block2,如圖藍色實線所示。
9>發送完block2後,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。
10>client向NameNode發送消息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以瞭解到:
①寫1T文件,我們需要3T的存儲,3T的網路流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通信,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關係,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關係;其他機架上,也有備份。
讀操作
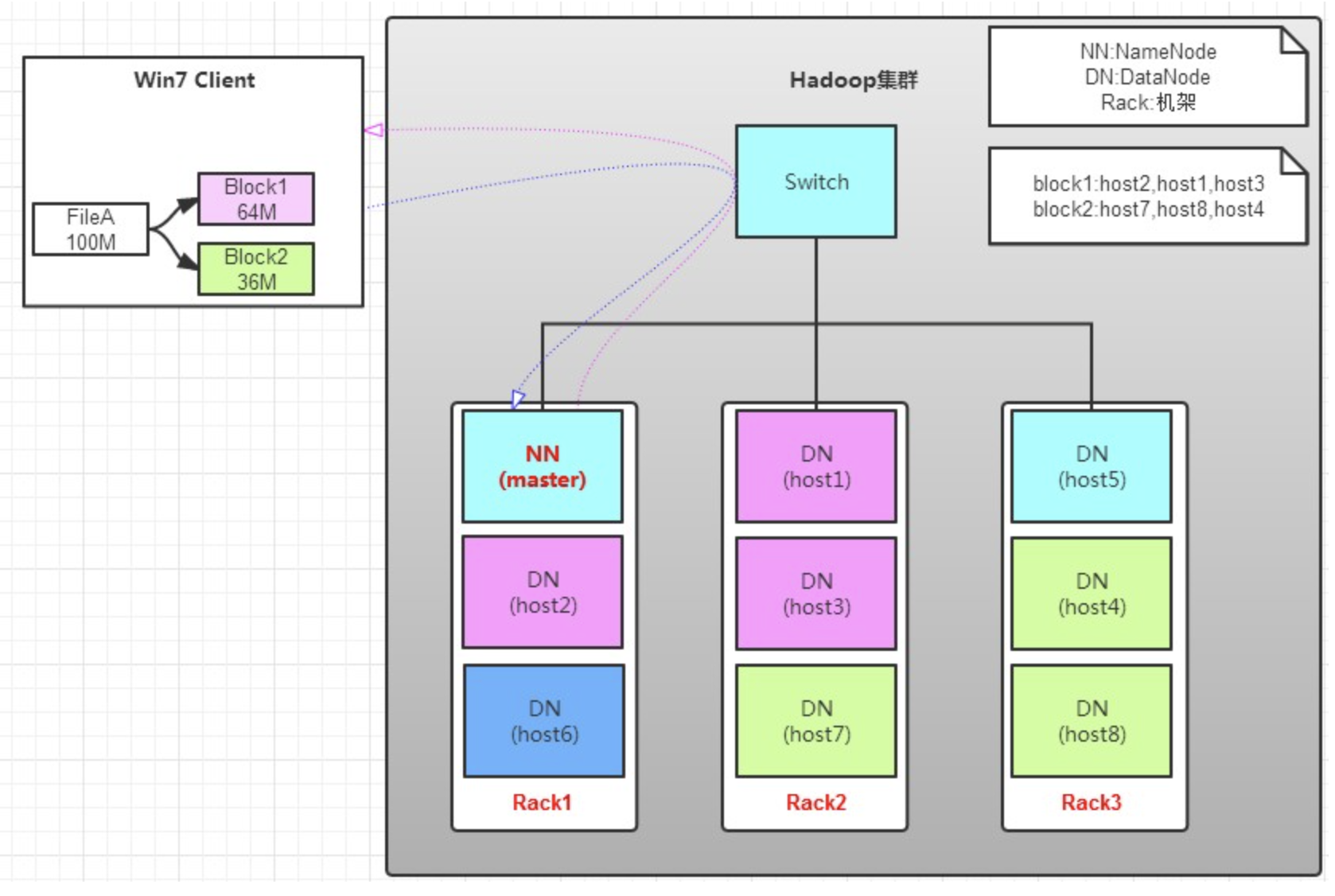
讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。
那麼,讀操作流程為:
a. client向namenode發送讀請求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先後順序的,先讀block1,再讀block2。而且block1去host2上讀取;然後block2,去host7上讀取;
上面例子中,client位於機架外,那麼如果client位於機架內某個DataNode上,例如,client是host6。那麼讀取的時候,遵循的規律是:
優選讀取本機架上的數據。
2. Yarn:分散式資源管理器 (Yet Another Resource Negotiator,另一種資源協調者)
Yarn顧名思義 管理資源的 那麼具有足夠的通用性,可以支持其他的分散式計算模式。
Yarn還能很方便的管理諸如Hive、Hbase、Pig、Spark/Shark等應用。
Yarn可以使各種應用互不幹擾的運行在同一個Hadoop系統中,實現整個集群資源的共用。
包含兩個進程:Nodemanager,ResourceManager
3. MapReduce:分散式計算框架
mapreduce是一種採用分而治之的分散式計算框架,用於處理數據量大的計算。
如一複雜的計算任務,單台伺服器無法勝任時,可將此大任務切分成一個個小的任務,小任務分別在不同的伺服器上並行的執行;最終再彙總每個小任務的結果
MapReduce由兩個階段組成:
Map階段(切分成一個個小的任務)
Reduce階段(彙總小任務的結果)
用戶只需實現map()和reduce()兩個函數,即可實現分散式計算
執行流程圖如下:
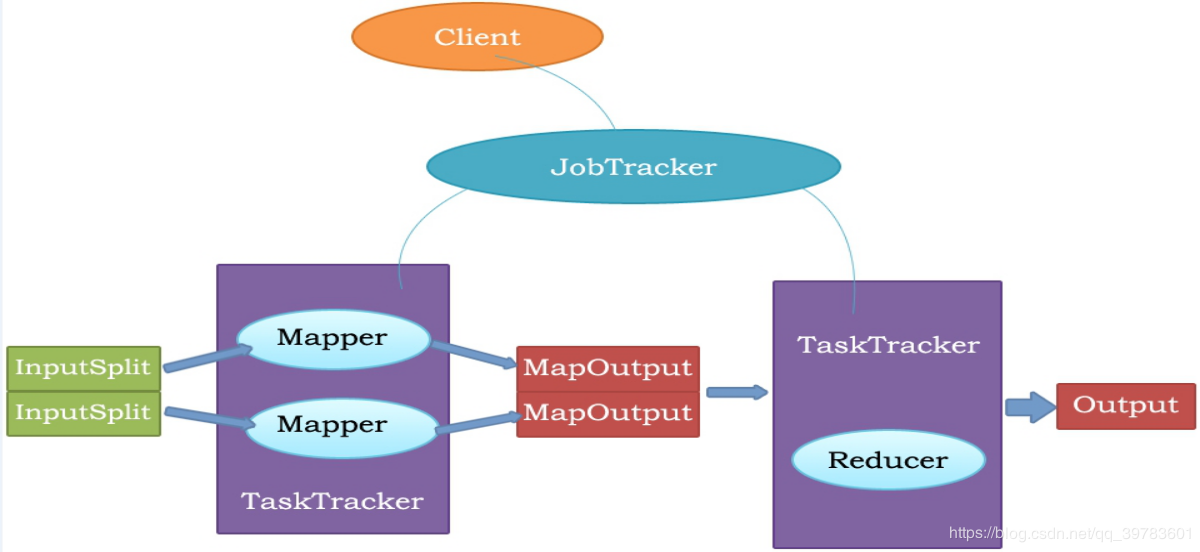
jobtracker
master節點,只有一個,管理所有作業,任務/作業的監控,錯誤處理等,將任務分解成一系列任務,並分派給tasktracker。
tacktracker
slave節點,運行 map task和reducetask;並與jobtracker交互,彙報任務狀態。
map task
解析每條數據記錄,傳遞給用戶編寫的map()並執行,將輸出結果寫入到本地磁碟(如果為map—only作業,則直接寫入HDFS)。
reduce task
從map 它深刻地執行結果中,遠程讀取輸入數據,對數據進行排序,將數據分組傳遞給用戶編寫的reduce函數執行
原理圖如下:
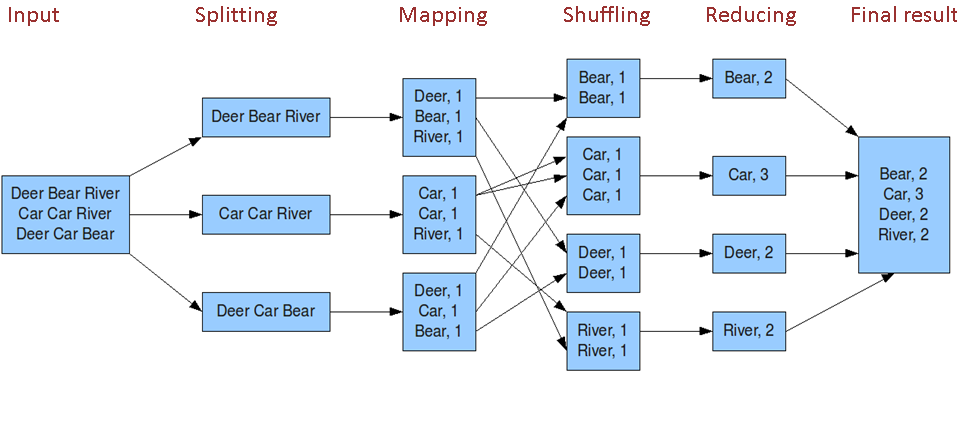
總體來說:是個總分總的結構,先分解成多個小任務,在map階段處理完成後,彙總成少數個小任務server在Reduce階段處理進行排序 分組等操作。
Map階段解說:先把一個大任務分解split成多個小任務
(1) 讀取HDFS中的文件。每一行解析成一個<k,v>。每一個鍵值對調用一次map函數。<0,hello you> <1,hello me>
(2)覆蓋map(),接收(1)產生的<k,v>,進行處理,轉換為新的<k,v>輸出。 <hello,1> <you,1> <hello,1> <me,1>
(3)對(2)輸出的<k,v>進行分區。預設分為一個區。
(4)對不同分區中的數據進行排序(按照k)、分組。分組指的是相同key的value放到一個集合中。 排序後:<hello,1> <hello,1> <me,1> <you,1> 分組後:<hello,{1,1}><me,{1}><you,{1}>
(5)(可選)對分組後的數據進行歸約。
Rduce階段解說:把map階段的結果進行彙總
(1)多個map任務的輸出,按照不同的分區,通過網路copy到不同的reduce節點上。
(2)對多個map的輸出進行合併、排序。覆蓋reduce函數,接收的是分組後的數據,實現自己的業務邏輯,<hello,2> <me,1> <you,1> 處理後,產生新的<k,v>輸出。
(3)對reduce輸出的<k,v>寫到HDFS中。
參考文獻:
https://www.cnblogs.com/laov/p/3434917.html
https://www.jianshu.com/p/f1e785fffd4d,
https://blog.csdn.net/qq_39783601/article/details/104928348,
https://blog.csdn.net/zcb_data/article/details/80402411,
https://www.cnblogs.com/ahu-lichang/p/6645074.html.


