
問題來源 2020年5月3日星期天。晚上7點39分,正是結賬的高峰期,然而就是在這個時候系統崩潰了。牽扯到錢的事沒一件事小事,可以定性此為重大事故。 造成的後果: 有人必須要背鍋了,先恢復再找問題源頭,再找誰的問題(這種鍋絕大多數是開發的問題)。 問題處理 常見思路:回滾、重啟大法!!! 先恢復再查 ...
問題來源
2020年5月3日星期天。晚上7點39分,正是結賬的高峰期,然而就是在這個時候系統崩潰了。牽扯到錢的事沒一件事小事,可以定性此為重大事故。
造成的後果:

有人必須要背鍋了,先恢復再找問題源頭,再找誰的問題(這種鍋絕大多數是開發的問題)。
問題處理
常見思路:回滾、重啟大法!!! 先恢復再查原因
f12 訪問看問題到底在哪裡?

502服務端錯誤,可以肯定與代碼健壯性有關。
重啟回滾能解決百分之80的問題,但這裡的路徑多了一個/,路由是不是有問題,看日誌,或看相關服務的連接。nginx就做了一個反向代理,我覺得還是跟請求的代碼有關,讓他們抓包看看流量到哪了,先看看解析有沒有問題,然後直接用ip能不能到ng,解析沒問題的話,確定一下功能變數名稱訪問能到ng不,後端直接在ng上用curl測試下正常不,代碼問題直接回滾,不二話,功能變數名稱問題看看是不是被劫持了。
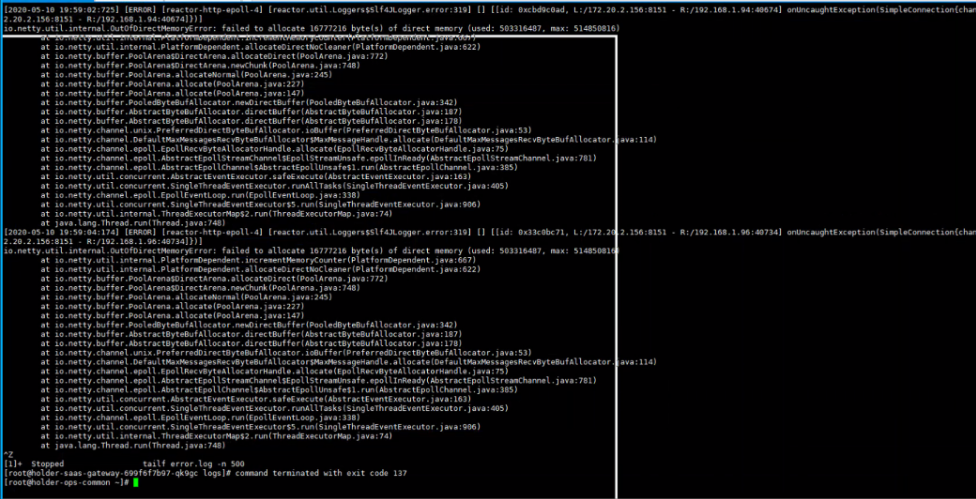
GC了,....網關,開發自己寫的...
其實最開始出現問題,後面會出現有的可以訪問,有的不行,我們的gatway是設置彈性伸縮的,剛纔確實伸縮了,但是有些流量還是轉到了舊的pod上,因為GC了,所以不能訪問gatway。
OOM是不會影響埠 埠只有是否被開放 或者服務是否正確啟動才會有埠的問題,OOM是記憶體的問題和你服務埠無關,Pod中查詢OOM的問題:java應用出現記憶體溢出老正常了。最好加上監控(監控Pod的IO之類的),重啟也行,加入註冊中心,服務不可用 剔除。
善後工作
- 監控日誌,報警出來
- 做探針?
探針沒用,因為服務埠都在,pod狀態也是running。所以就是要api,檢測可用性的api。埠不能代表可用性,應該讓開發在網關加一個健康檢查埠。通過curl 健康檢查埠判斷業務是否正常 - prestop
鉤子,有問題,就殺掉,然後剔除註冊中心,滾動更新的時候加上prestop,然後通過curl 註冊中心,將這個pod強制下線
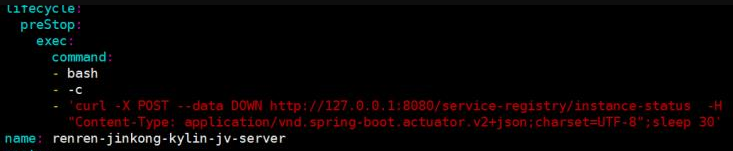
具體參數得問開發
越是重大問題你處理了,越是體現價值,處理好了,應該的,處理不好,背鍋。真現實。


