
MMU存在的意義 [導讀] 本文從記憶體管理的發展歷程角度層層遞進,介紹MMU的誕生背景,工作機制。而忽略了具體處理器的具體實現細節,將MMU的工作原理從概念上比較清晰的梳理了一遍。 MMU誕生之前: 在傳統的批處理系統如DOS系統,應用程式與操作系統在記憶體中的佈局大致如下圖: 應用程式直接訪問物理內 ...
MMU存在的意義
[導讀] 本文從記憶體管理的發展歷程角度層層遞進,介紹MMU的誕生背景,工作機制。而忽略了具體處理器的具體實現細節,將MMU的工作原理從概念上比較清晰的梳理了一遍。
MMU誕生之前:
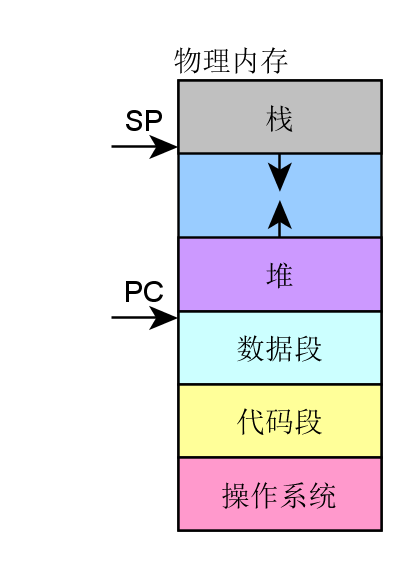
在傳統的批處理系統如DOS系統,應用程式與操作系統在記憶體中的佈局大致如下圖:
- 應用程式直接訪問物理記憶體,操作系統占用一部分記憶體區。
- 操作系統的職責是“載入”應用程式,“運行”或“卸載”應用程式。
如果我們一直是單任務處理,則不會有任何問題,也或者應用程式所需的記憶體總是非常小,則這種架構是不會有任何問題的。然而隨著電腦科學技術的發展,所需解決的問題越來越複雜,單任務批處理已不能滿足需求了。而且應用程式需要的記憶體量也越來越大。而且伴隨著多任務同時處理的需求,這種技術架構已然不能滿足需求了,早先的多任務處理系統是怎麼運作的呢?
程式員將應用程式分段載入執行,但是分段是一個苦力活。而且死板枯燥。此時聰明的電腦科學家想到了好辦法,提出來虛擬記憶體的思想。程式所需的記憶體可以遠超物理記憶體的大小,將當前需要執行的留在記憶體中,而不需要執行的部分留在磁碟中,這樣同時就可以滿足多應用程式同時駐留記憶體能併發執行了。
從總體上而言,需要實現哪些大的策略呢?
- 所有的應用程式能同時駐留記憶體,並由操作系統調度併發執行。需要提供機制管理I/O重疊,CPU資源競爭訪問。
- 虛實記憶體映射及交換管理,可以將真實的物理記憶體,有可變或固定的分區,分頁或者分段與虛擬記憶體建立交換映射關係,並且有效的管理這種映射,實現交換管理。
這樣,衍生而來的一些實現上的更具體的需求:
- 競爭訪問保護管理需求:需要嚴格的訪問保護,動態管理哪些記憶體頁/段或區,為哪些應用程式所用。這屬於資源的競爭訪問管理需求。
- 高效的翻譯轉換管理需求:需要實現快速高效的映射翻譯轉換,否則系統的運行效率將會低下。
- 高效的虛實記憶體交換需求:需要在實際的虛擬記憶體與物理記憶體進行記憶體頁/段交換過程中快速高效。
總之,在這樣的背景下,MMU應運而生,也由此可見,任何一項技術的發展壯大,都必然是需求驅動的。這是技術本身發展的客觀規律。
記憶體管理的好處
- 為編程提供方便統一的記憶體空間抽象,在應用開發而言,好似都完全擁有各自獨立的用戶記憶體空間的訪問許可權,這樣隱藏了底層實現細節,提供了統一可移植用戶抽象。
- 以最小的開銷換取性能最大化,利用MMU管理記憶體肯定不如直接對記憶體進行訪問效率高,為什麼需要用這樣的機制進行記憶體管理,是因為併發進程每個進程都擁有完整且相互獨立的記憶體空間。那麼實際上記憶體是昂貴的,即使記憶體成本遠比從前便宜,但是應用進程對記憶體的尋求仍然無法在實際硬體中,設計足夠大的記憶體實現直接訪問,即使能滿足,CPU利用地址匯流排直接定址空間也是有限的。
記憶體管理實現總體策略
從操作系統角度來看,虛擬記憶體的基本抽象由操作系統實現完成:
- 處理器記憶體空間不必與真實的所連接的物理記憶體空間一致。
- 當應用程式請求訪問記憶體時,操作系統將虛擬記憶體地址翻譯成物理記憶體地址,然後完成訪問。
從應用程式角度來看,應用程式(往往是進程)所使用的地址是虛擬記憶體地址,從概念上就如下示意圖所示,MMU在操作系統的控制下負責將虛擬記憶體實際翻譯成物理記憶體。

從而這樣的機制,虛擬記憶體使得應用程式不用將其全部內容都一次性駐留在記憶體中執行:
- 節省記憶體:很多應用程式都不必讓其全部內容一次性載入駐留在記憶體中,那麼這樣的好處是顯而易見,即使硬體系統配置多大的記憶體,記憶體在系統中仍然是最為珍貴的資源。所以這種技術節省記憶體的好處是顯而易見的。
- 使得應用程式以及操作系統更具靈活性。
- 操作系統根據應用程式的動態運行時行為靈活的分配記憶體給應用程式。
- 使得應用程式可以使用比實際物理記憶體多或少的記憶體空間。
MMU 以及TLB
MMU(Memory Management Unit)記憶體管理單元:
- 一種硬體電路單元負責將虛擬記憶體地址轉換為物理記憶體地址
- 所有的記憶體訪問都將通過MMU進行轉換,除非沒有使能MMU。
TLB(Translation Lookaside Buffer )轉譯後備緩衝器* : 本質上是MMU用於虛擬地址到物理地址轉換表的緩存

這樣一種架構,其最終運行時目的,是為主要滿足下麵這樣運行需求:
多進程併發同時併發運行在實際物理記憶體空間中,而MMU充當了一個至關重要的虛擬記憶體到物理記憶體的橋梁作用。
那麼,這種框架具體從高層級的概念上是怎麼做到的呢?事實上,是將物理記憶體採用分片管理的策略來實現的,那麼,從實現的角度將有兩種可選的策略:
-
固定大小分區機制
-
可變大小分區機制
固定大小區片機制

通過這樣一種概念上的策略,將物理記憶體分成固定等大小的片:
- 每一個片提供一個基地址
- 實際定址,物理地址=某片基址+虛擬地址
- 片基址由操作系統在進程動態運行時動態載入
這種策略實現,其優勢在於簡易,切換快速。但是該策略也帶來明顯的劣勢:
- 內部碎片:一個進程不使用的分區中的記憶體對其他進程而言無法使用
- 一種分區大小並不能滿足所有應用進程所需。
可變大小分區機制
記憶體被劃分為可變大小的區塊進行映射交換管理:
- 需要提供基址以及可變大小邊界,可變大小邊界用於越界保護。
- 實際定址,物理地址=某片基址+虛擬地址
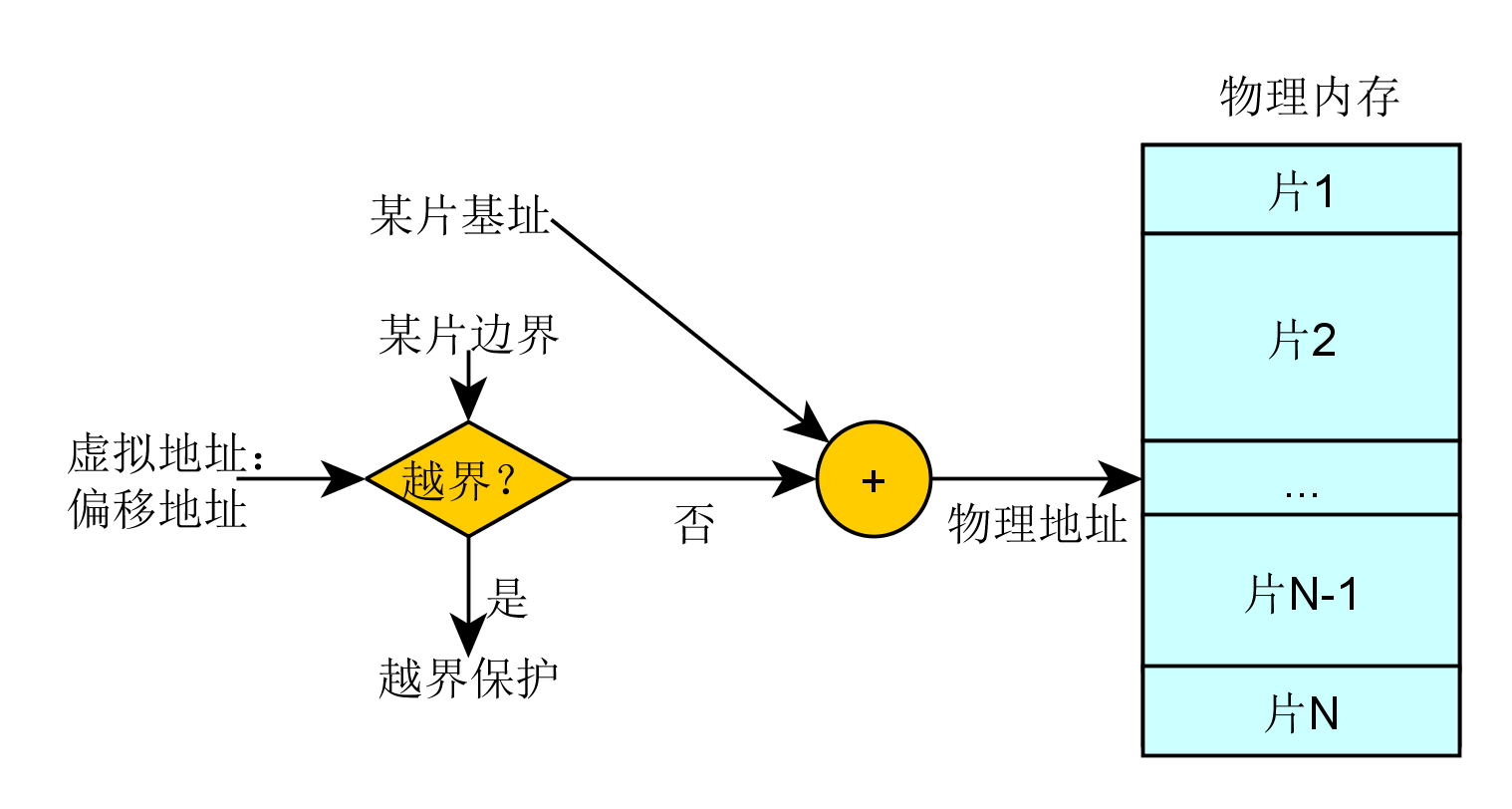
那麼這種策略其優勢在於沒有內部記憶體碎片,分配剛好夠進程所需的大小。但是劣勢在於,在載入和卸載的動態過程中會產生碎片。
分頁機制
分頁機制採用在虛擬記憶體空間以及物理記憶體空間都使用固定大小的分區進行映射管理。
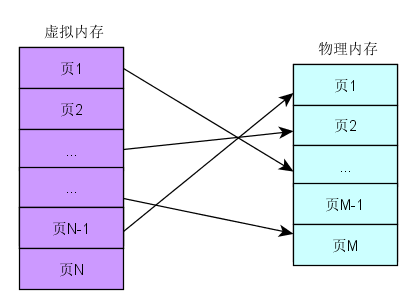
- 從應用程式(進程)角度看記憶體是連續的0-N的分頁的虛擬地址空間。
- 物理記憶體角度看,記憶體頁是分散在整個物理存儲中
- 這種映射關係對應用程式不可見,隱藏了實現細節。
分頁機制是如何定址的呢?這裡介紹的設計理念,具體的處理器實現各有細微差異:
- 虛擬地址包含了兩個部分:虛擬頁序號VPN(virtual paging number)以及偏移量
- 虛擬頁序號VPN是頁表(Page Table)的索引
- 頁表(Page Table)維護了頁框號(Page frame number PFN)
- 物理地址由PFN::Offset進行解析。
舉個慄子,如下圖所示:
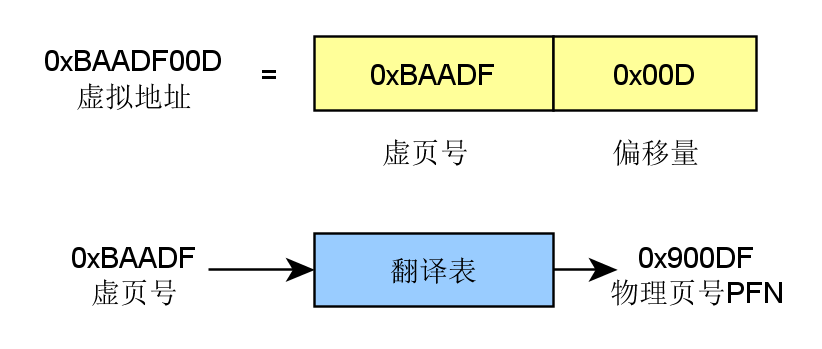
還沒有查到具體的物理地址,憋急,再看一下完整解析示例:
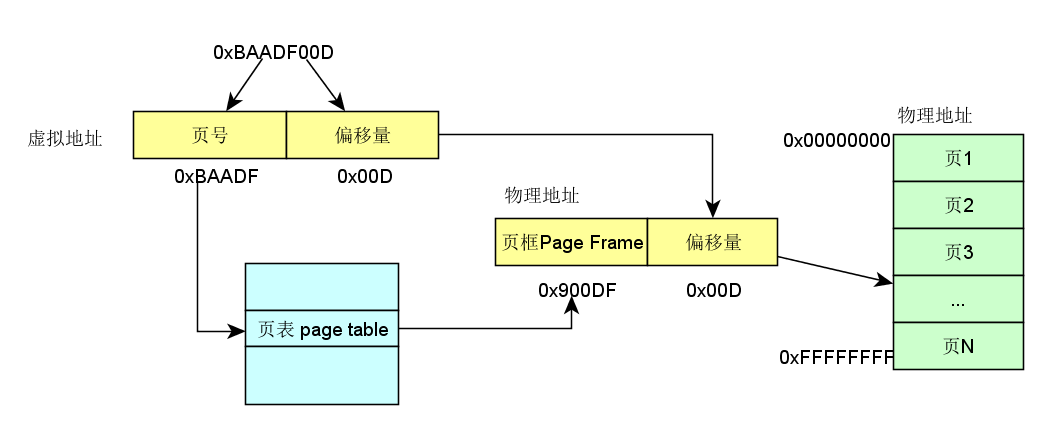
如何管理頁表
對於32位地址空間而言,假定4K為分頁大小,則頁表的大小為100MB,這對於頁表的查詢而言是一個很大的開銷。那麼如何減小這種開銷呢?實際運行過程中發現,事實上只需要映射實際使用的很小一部分地址空間。那麼在一級頁機制基礎上,延伸出多級頁表機制。
以二級分頁機製為例:

單級頁表已然有不小的開銷,查詢頁表以及取數,而二級分頁機制,因為需要查詢兩次頁表,則將這種開銷在加一倍。那麼如何提高效率呢?其實前面提到一個概念一直還沒有深入描述TLB,將翻譯工作由硬體緩存cache,這就是TLB存在的意義。
- TLB 將虛擬頁翻譯成PTE,這個工作可在單周期指令完成。
- TLB由硬體實現
- 完全關聯緩存(並行查找所有條目)
- 緩存索引是虛擬頁碼
- 緩存內容是PTE
- 則由PTE+offset,可直接計算出物理地址
TLB載入
誰負責載入TLB呢?這裡可供選擇的有兩種策略:
- 由操作系統載入,操作系統找到對應的PTE,而後載入到TLB。格式比較靈活。
- MMU硬體負責,由操作系統維護頁表,MMU直接訪問頁表,頁表格式嚴格依賴硬體設計格式。
總結一下
從電腦大致發展歷程來瞭解記憶體管理的大致發展策略,如何衍生出MMU,以及固定分片管理、可變分片管理等不同機制的差異,最後衍生出單級分頁管理機制、多級分頁管理機制、TLB的作用。從概念上相對比較易懂的角度描述了MMU的誕生、機制,而忽略了處理器的具體實現細節。作為從概念上更深入的理解MMU的工作機理的角度,還是不失為一篇淺顯易懂的文章。
文章出自微信公眾號:嵌入式客棧,更多內容,請關註本人公眾號,嚴禁商業使用,違法必究



