
前言 本文的文字及圖片來源於網路,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯繫我們以作處理。 互聯網是由一個個站點和網路設備組成的大網,我們通過瀏覽器訪問站點,站點把HTML、JS、CSS代碼返回給瀏覽器,這些代碼經過瀏覽器解析、渲染,將豐富多彩的網頁呈現我們眼前。 ...
前言
本文的文字及圖片來源於網路,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯繫我們以作處理。
互聯網是由一個個站點和網路設備組成的大網,我們通過瀏覽器訪問站點,站點把HTML、JS、CSS代碼返回給瀏覽器,這些代碼經過瀏覽器解析、渲染,將豐富多彩的網頁呈現我們眼前。
很多人學習python,不知道從何學起。
很多人學習python,掌握了基本語法過後,不知道在哪裡尋找案例上手。
很多已經做案例的人,卻不知道如何去學習更加高深的知識。
那麼針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!
一、爬蟲是什麼?
如果我們把互聯網比作一張大的蜘蛛網,數據便是存放於蜘蛛網的各個節點,而爬蟲就是一隻小蜘蛛,沿著網路抓取自己的獵物(數據)爬蟲指的是:向網站發起請求,獲取資源後分析並提取有用數據的程式。
從技術層面來說就是 通過程式模擬瀏覽器請求站點的行為,把站點返回的HTML代碼/JSON數據/二進位數據(圖片、視頻) 爬到本地,進而提取自己需要的數據,存放起來使用;
二、爬蟲的基本流程
用戶獲取網路數據的方式:
方式1:瀏覽器提交請求—>下載網頁代碼—>解析成頁面
方式2:模擬瀏覽器發送請求(獲取網頁代碼)->提取有用的數據->存放於資料庫或文件中
爬蟲要做的就是方式2。
1、發起請求
使用http庫向目標站點發起請求,即發送一個Request
Request包含:請求頭、請求體等
Request模塊缺陷:不能執行JS 和CSS 代碼
2、獲取響應內容
如果伺服器能正常響應,則會得到一個Response
Response包含:html,json,圖片,視頻等
3、解析內容
解析html數據:正則表達式(RE模塊),第三方解析庫如Beautifulsoup,pyquery等
解析json數據:json模塊
解析二進位數據:以wb的方式寫入文件
4、保存數據
資料庫(MySQL,Mongdb、Redis)
文件
三、http協議 請求與響應

Request:用戶將自己的信息通過瀏覽器(socket client)發送給伺服器(socket server)
Response:伺服器接收請求,分析用戶發來的請求信息,然後返回數據(返回的數據中可能包含其他鏈接,如:圖片,js,css等)
ps:瀏覽器在接收Response後,會解析其內容來顯示給用戶,而爬蟲程式在模擬瀏覽器發送請求然後接收Response後,是要提取其中的有用數據。
四、 request
1、請求方式:
常見的請求方式:GET / POST
2、請求的URL
url全球統一資源定位符,用來定義互聯網上一個唯一的資源 例如:一張圖片、一個文件、一段視頻都可以用url唯一確定
url編碼
https://www.baidu.com/s?wd=圖片
圖片會被編碼(看示例代碼)
網頁的載入過程是:
載入一個網頁,通常都是先載入document文檔,
在解析document文檔的時候,遇到鏈接,則針對超鏈接發起下載圖片的請求
3、請求頭
User-agent:請求頭中如果沒有user-agent客戶端配置,服務端可能將你當做一個非法用戶host;
cookies:cookie用來保存登錄信息
註意:一般做爬蟲都會加上請求頭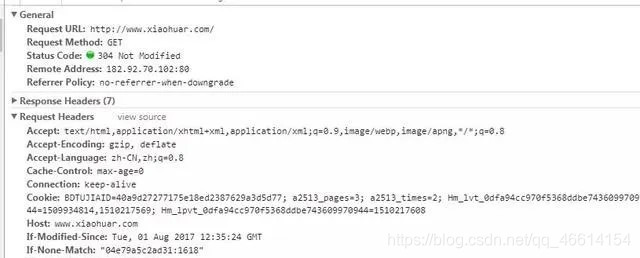

請求頭需要註意的參數:
(1)Referrer:訪問源至哪裡來(一些大型網站,會通過Referrer 做防盜鏈策略;所有爬蟲也要註意模擬)
(2)User-Agent:訪問的瀏覽器(要加上否則會被當成爬蟲程式)
(3)cookie:請求頭註意攜帶
4、請求體
請求體如果是get方式,請求體沒有內容 (get請求的請求體放在 url後面參數中,直接能看到)如果是post方式,請求體是format dataps:1、登錄視窗,文件上傳等,信息都會被附加到請求體內2、登錄,輸入錯誤的用戶名密碼,然後提交,就可以看到post,正確登錄後頁面通常會跳轉,無法捕捉到post
五、 響應Response
1、響應狀態碼
200:代表成功
301:代表跳轉
404:文件不存在
403:無許可權訪問
502:伺服器錯誤
2、respone header
響應頭需要註意的參數:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多個,是來告訴瀏覽器,把cookie保存下來
(2)Content-Location:服務端響應頭中包含Location返回瀏覽器之後,瀏覽器就會重新訪問另一個頁面
3、preview就是網頁源代碼
JSO數據
如網頁html,圖片
二進位數據等
六、總結
1、總結爬蟲流程:
爬取—>解析—>存儲
2、爬蟲所需工具:
請求庫:requests,selenium(可以驅動瀏覽器解析渲染CSS和JS,但有性能劣勢(有用沒用的網頁都會載入);) 解析庫:正則,beautifulsoup,pyquery 存儲庫:文件,MySQL,Mongodb,Redis
不管你是零基礎還是有基礎都可以獲取到自己相對應的學習禮包!包括Python軟體工具和2020最新入門到實戰教程。加群695185429即可免費獲取。


