
1、基本概念 數據讀寫性能主要是IO次數,單次從磁碟讀取單位是頁,即便只讀取一行記錄,從磁碟中也是會讀取一頁的()單頁讀取代價高,一般都會進行預讀) (1)扇區是磁碟的最小存儲單元 (2)塊是文件系統的最小存儲單元,比如你保存一個記事本,即使只輸入一個字元,也要占用4KB的存儲,這就是最小存儲的意思 ...
1、基本概念
數據讀寫性能主要是IO次數,單次從磁碟讀取單位是頁,即便只讀取一行記錄,從磁碟中也是會讀取一頁的()單頁讀取代價高,一般都會進行預讀)
(1)扇區是磁碟的最小存儲單元
(2)塊是文件系統的最小存儲單元,比如你保存一個記事本,即使只輸入一個字元,也要占用4KB的存儲,這就是最小存儲的意思
(3)頁是B+樹的最小存儲單元
| 單元 | 誰的(歸屬) | 最小大小 |
|---|---|---|
| 扇區 | 磁碟 | 512B |
| 塊 | 文件系統 | 4K |
| 頁 | B+ | 16K |
2、有無索引的讀取數據比較
無索引情況下,會直接在磁碟中讀取經過多次IO才能找到需要的數據,首先讀取這個扇區的數據,需要將磁頭放到這個扇區上方,這個過程叫做尋道,花費時間叫做尋道時間,然後磁碟旋轉將目標扇區旋轉到磁頭下,這個過程耗時叫旋轉耗時,磁碟讀取數據時間包含尋道和旋轉時間。
有索引情況下,會讀取索引數據經過幾次IO就能找到需要的數據。下麵計算通過索引(B+TREE,主鍵id採用bigint占用8位元組,一行數據占用1KB)計算:
(1)第一層
一個頁16K,每一個索引鍵的大小8位元組(bigint)+6位元組(指針大小),因此第一層可存儲16*1024/14=1170個索引鍵。
(2)第二層
第二層只存儲索引鍵,能存儲多少個索引鍵呢?1170(這麼多個頁,有第一層延伸的指針)1170(每頁的索引鍵個數,跟第一步計算一致)=1368900
如果第二層存儲數據呢?1170(這麼多個頁,有第一層延伸的指針)16(16KB的頁大小/1KB的數據大小)=18720,也就是能存儲一萬多條數。
(3)第三層
直接看三層能存儲多少數據?1170*1170*16=21902400,是不是很強大,此處應該有掌聲和鮮花,3次IO就可以查詢到2千多萬左右的數據,也就是這麼大的數據量如果通過主鍵索引來查找是很快,這就是explain一個sql時,type=const為什麼性能是最優的。
3、mysql索引類型
表級別索引設置
(1)應用層:唯一索引,普通索引,複合索引
(2)存儲結構:BTree(BTree或B+Tree)、Hash索引,full-index全文索引,R-Tree索引。
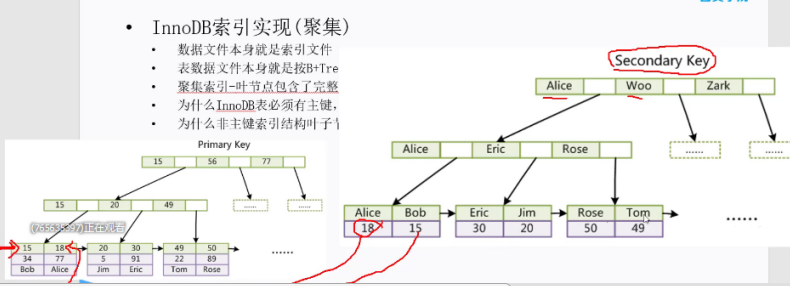
(3)數據物理順序與鍵值邏輯:聚集索引,非聚集索引。
聚集索引的B+Tree中的葉子節點存放的是整張表的行記錄數據。輔助索引與聚集索引的區別在於輔助索引的葉子節點並不包含行記錄的全部數據,而是存儲相應行數據的聚集索引鍵,即主鍵。
聚簇索引是對磁碟上實際數據重新組織以按指定的一個或多個列的值排序的演算法。特點是存儲數據的順序和索引順序一致。 一般情況下主鍵會預設創建聚簇索引,且一張表只允許存在一個聚簇索引。
聚簇索引的葉子節點就是數據節點,而非聚簇索引的葉子節點仍然是索引節點,只不過有指向對應數據塊的指針。
4、B-TREE
(1)特點
B-樹相對B樹,B-樹的各層節點要存儲數據,導致每頁能夠容納的節點就很少,直接導致樹深度加大
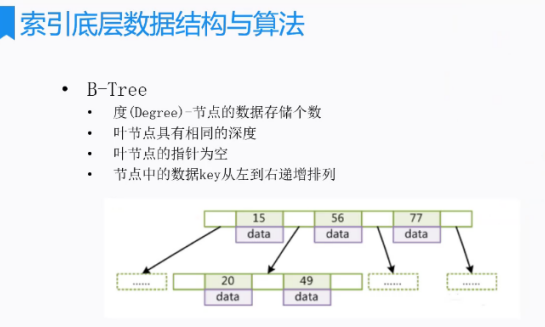
(2)實例
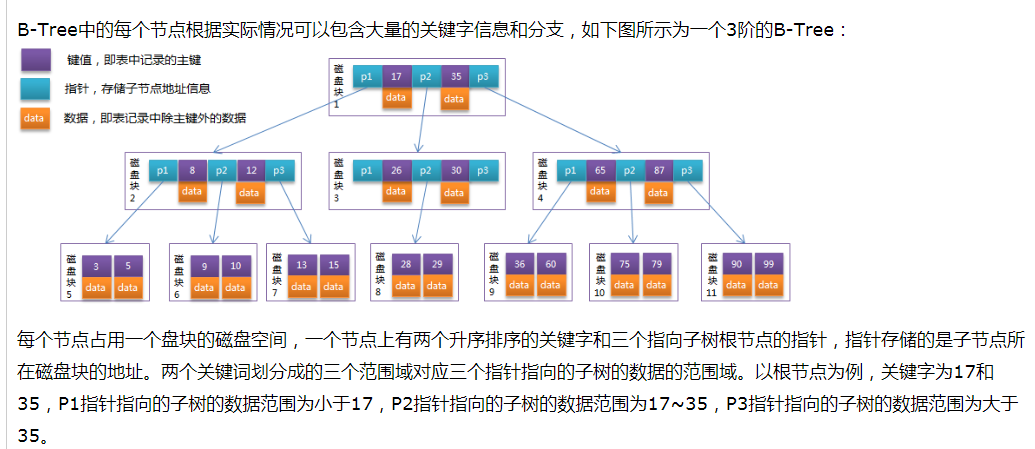

5、B+TREE
(1)特點

(2)實例
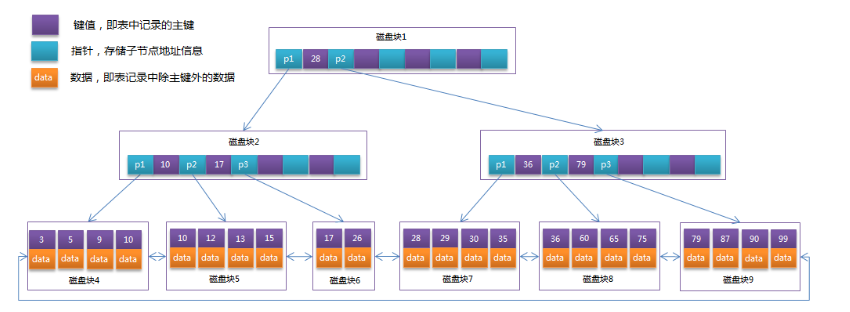

6、MyISAM的索引結構
MyISAM有三個文件,.frm,MYD,MYI分別是表結構,表數據,表索引。先查找主鍵值對應的value,然後根據value查找對應的行

7、innodb索引結構
InnoDB存儲引擎就是用B+Tree實現其索引結構。由frm,ibd文件組成,主鍵索引存儲數據,非主鍵索引存儲主鍵數據
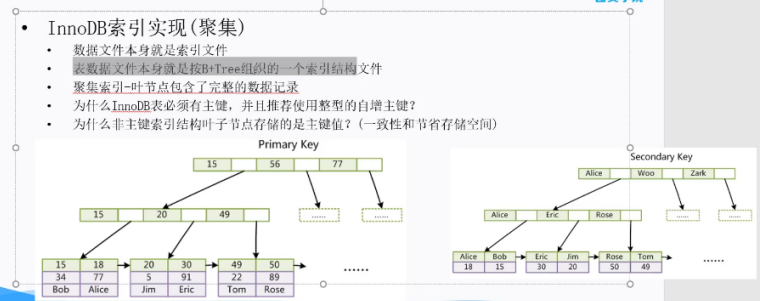
8、innodb和myisam主鍵索引和其他索引區別



