
前言 隨著 Web 2.0 時代的到來,互聯網的網路架構已經從傳統的 架構轉變為更加方便、快捷的 架構,B/S 架構大大簡化了用戶使用網路應用的難度,提高了用戶體驗。 架構帶來了以下兩方面的好處: 客戶端使用統一的瀏覽器( )。由於瀏覽器具有統一性,不需要特殊的配置和網路連接。另外瀏覽器的交互特性使 ...
前言
隨著 Web 2.0 時代的到來,互聯網的網路架構已經從傳統的 C/S 架構轉變為更加方便、快捷的 B/S 架構,B/S 架構大大簡化了用戶使用網路應用的難度,提高了用戶體驗。
B/S 架構帶來了以下兩方面的好處:
- 客戶端使用統一的瀏覽器(
Browser)。由於瀏覽器具有統一性,不需要特殊的配置和網路連接。另外瀏覽器的交互特性使得用戶使用它非常簡便,且用戶行為的可繼承性非常強,也就是用戶只要學會了上網,不管使用哪個應用,一旦學會了,便具備了使用其它任何互聯網服務的經驗。 - 服務端(
Server)基於統一的HTTP。和傳統的 C/S 架構使用自定義的應用層協議不同。使用統一的 HTTP 簡化了開發模式,並且基於 HTTP 的伺服器又很多,如Apache、Nginx、Tomcat等,這些伺服器可以直接拿來使用,不僅如此,連開發服務的通用框架也可以直接拿來使用,不需要單獨開發,如Spring、Spring MVC、MyBatis等,我們只需關註服務的業務邏輯,同樣簡化了我們的開發工作。
B/S 網路架構概述
B/S 基於統一的應用層協議 HTTP 來交互數據,與大多數 C/S 互聯網應用程式採用的長連接的交互模式不同。HTTP 採用無狀態的短連接的通信方式,通常情況下,一次請求就完成了一次數據交互,然後這次通信連接就斷開了。採用這種方式可以有效應對更多的用戶請求。
當在瀏覽器里輸入 antoniopeng.com 這個 URL 並按下回車鍵時,會發生很多操作:
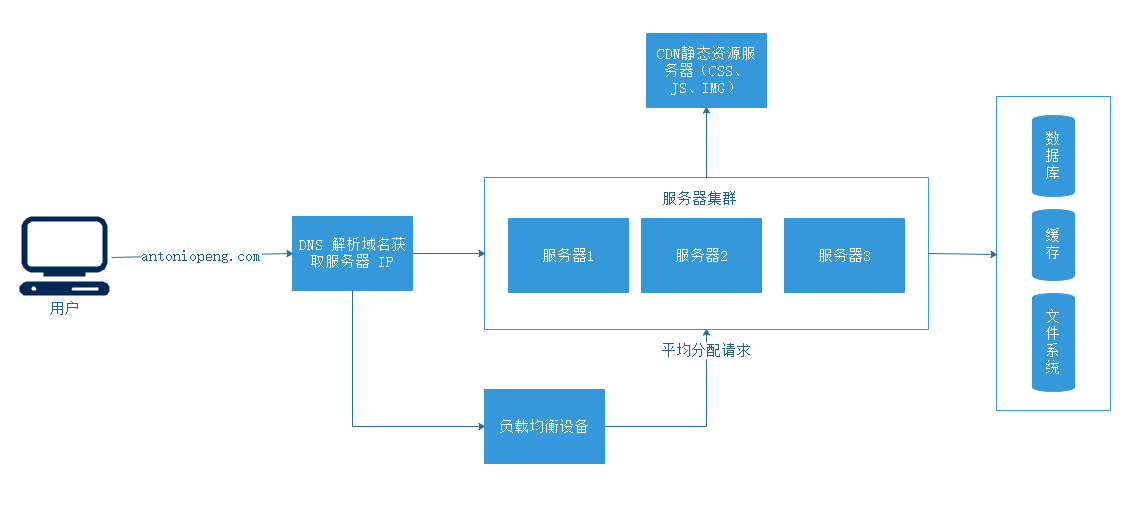
- 首先請求
DNS把這個功能變數名稱解析成對應的IP地址。 - 然後根據這個
IP地址在互聯網上找到對應的伺服器,向這個伺服器發起一個(GET/POST/...)請求。由這個伺服器返回預設的數據資源給訪問的用戶,在服務端也可能還有很複雜的業務邏輯。- 伺服器可能有很多台,由一臺負載均衡設備(如
Nginx)來平均分配所有用戶的請求。 - 還有請求的數據是存儲在緩存里還是一個靜態文件中,或是在資料庫里。
- 伺服器可能有很多台,由一臺負載均衡設備(如
- 最後當數據返回瀏覽器時,解析到發現還有一些靜態資源(如
CSS、JS、IMG)時又會發起另外的HTTP請求,而這些請求很可能會在CDN上,那麼CDN伺服器又會處理這些請求。
如何發起一個請求
這個問題簡單又複雜,簡單是指當我們在瀏覽器里數據一個 URL 時,按下回車鍵就發起了這個 HTTP 請求,很快就可以看到這個請求的返回結果。複雜是指不藉助瀏覽器也能發起請求。
而一個 HTTP 連接本質上是一個 Socket 連接,那麼我們可以完全模擬瀏覽器來發起 HTTP 請求。Apache HttpClient 就是一個開源的通過程式實現的處理 HTTP 請求的工具包。
下麵是一個基於 HttpClient 的調用示例:
引入依賴
在 pom.xml 中添加 org.apache.httpcomponents:httpclient 依賴
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.5</version>
</dependency>
創建 Http Get 請求
實現代碼如下
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class MyTest {
public static void main(String[] args) {
get();
}
private static void get() {
// 創建 HttpClient 客戶端
CloseableHttpClient httpClient = HttpClients.createDefault();
// 創建 HttpGet 請求
HttpGet httpGet = new HttpGet("http://www.baidu.com");
// 設置長連接
httpGet.setHeader("Connection", "keep-alive");
// 設置代理(模擬瀏覽器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
// 設置 Cookie
httpGet.setHeader("Cookie", "UM_distinctid=34342706a09352-0376059833914f-3c604504-1fa400-16442706a0b345; CNZZDATA1262458286=1603637673-1530123020-%7C1530123020; JSESSIONID=805587506F1594AE02DC45845A7216A4");
CloseableHttpResponse httpResponse = null;
try {
// 請求並獲得響應結果
httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
// 輸出請求結果
System.out.println(EntityUtils.toString(httpEntity));
} catch (IOException e) {
e.printStackTrace();
}
// 無論如何必須關閉連接
finally {
if (httpResponse != null) {
try {
httpResponse.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (httpClient != null) {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
除了在 Java 中使用非常普遍的 HttpClient 工具,另外在命令行中的 curl 命令,通過 curl + URL 就可以簡單地發起一個 HTTP 請求
- 輸入命令
curl https://www.baidu.com
- 返回 HTML 數據結果
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>鐧懼害涓€涓嬶紝浣犲氨鐭ラ亾</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=鐧懼害涓€涓?class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>鏂伴椈</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>鍦板浘</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>瑙嗛</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>璐村惂</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>鐧誨綍</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">鐧誨綍</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">鏇村浜у搧</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>鍏充簬鐧懼害</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>浣跨敤鐧懼害鍓嶅繀璇?/a> <a href=http://jianyi.baidu.com/ class=cp-feedback>鎰忚鍙嶉</a> 浜琁CP璇?30173鍙?nbsp; <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
HTTP 解析
要理解 HTTP,最重要的是要熟悉 HTTP 中的 HTTP Header,它控制著數據的傳輸。最重要的是,它控制著瀏覽器的渲染行為和伺服器的執行邏輯。例如,當伺服器沒有用戶請求的數據時就會返回一個 404 狀態碼,告訴瀏覽器沒有要請求的數據,通常瀏覽器會展示一個非常不願意看到的個 “該頁面不存在” 的錯誤信息。
常見的 HTTP 請求頭
| 請求頭 | 說明 |
|---|---|
| Accept-Charset | 指定客戶端接收的字元集 |
| Accept-Encoding | 指定可接受的編碼(如 Accept-Encoding : gzip.deflate) |
| Accept-Language | 指定一種自然語言(如 Accept-Language : zh-cn) |
| Host | 指定被請求資源的主機和埠號(如 Host : www.baidu.com) |
| User-Agent | 客戶端將它的操作系統、瀏覽器和其它屬性告訴服務端 |
| Connection | 指定當前連接是否保持(如 Connection : Keep-Alive) |
常見的 HTTP 響應頭
| 響應頭 | 說明 |
|---|---|
| Server | 伺服器名稱(如 Server : nginx/1.17.6) |
| Content-Type | 發送給接收者的實體的類型(如 Content-Type : text/html;charset=GBK) |
| Content-Encoding | 與 Accept-Encoding 對應,服務端採用的編碼 |
| Content-Language | 與 Accept-Language 對應,資源所用的自然語言 |
| Content-Length | 正文的長度 |
| Keep-Alive | 保持連接的時間(如 Keep-Alive : timeout=5) |
常見的 HTTP 狀態碼
| 狀態碼 | 說明 |
|---|---|
| 200 | 請求成功 |
| 302 | 臨時跳轉 |
| 400 | 客戶端請求有語法錯誤,不能被伺服器識別 |
| 403 | 伺服器收到請求,但是拒絕提供服務,即沒有許可權 |
| 404 | 請求的資源不存在 |
| 500 | 伺服器發生不可預期的錯誤 |
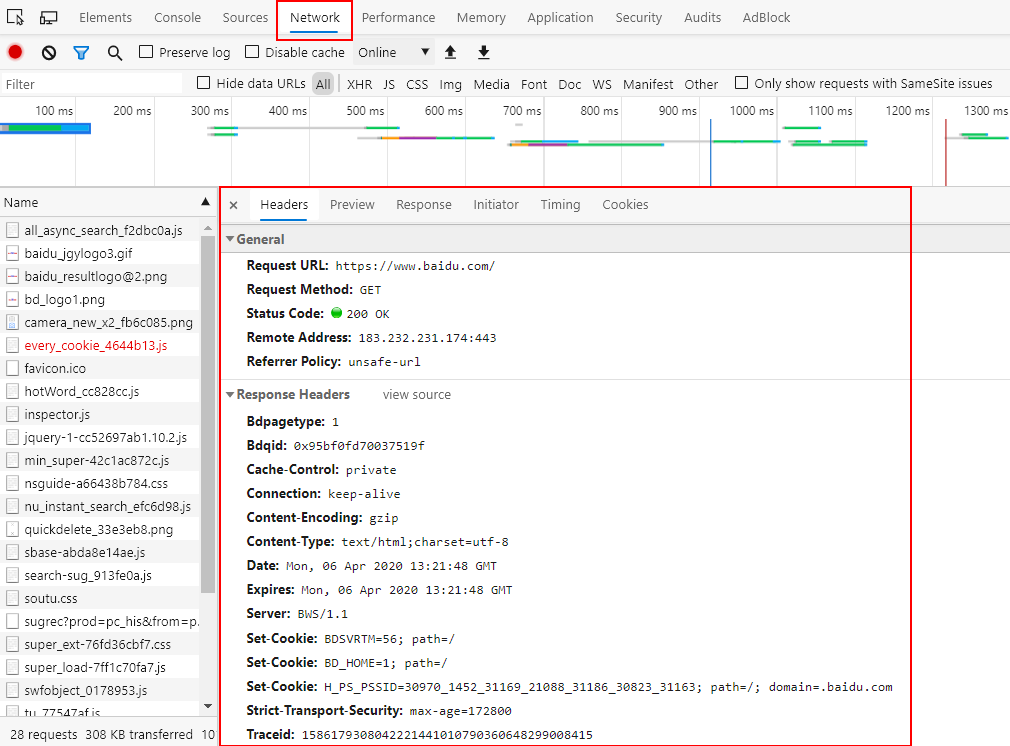
查看 HTTP 信息
要看一個 HTTP 請求的請求頭和響應頭可以通過 F12 快捷鍵打開瀏覽器的調試工具查看,例如我們正在訪問 www.baidu.com,按下 F12 並打開 Network 調試欄可以看到以下 HTTP Header 內容
瀏覽器緩存機制
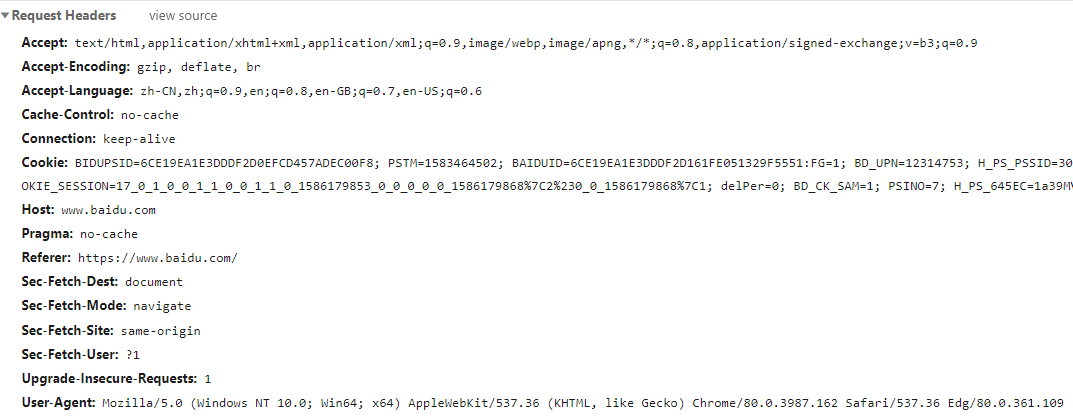
當瀏覽一個網頁發現有異常時,通常要考慮的就是是不是瀏覽器做了緩存,所以一般的做法就是按 Ctrl + F5 組合鍵重新請求一次這個頁面,這樣的話請求的肯定是最新的頁面。因為按 Ctrl + F5 組合鍵會直接向目標 URL 發送請求,而不會使用瀏覽器緩存的數據。
如圖所示,這次請求沒有到服務端,使用的是瀏覽器的緩存數據
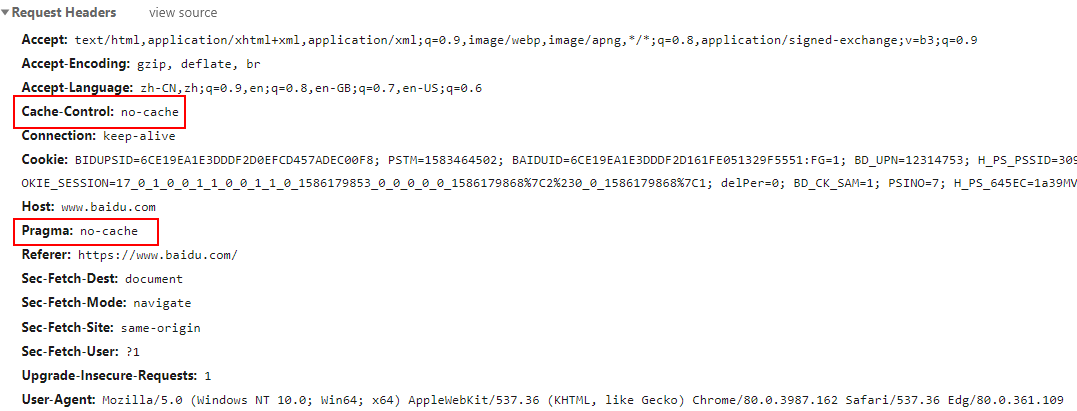
按 Ctrl + F5 組合鍵刷新頁面後,會發現在 HTTP 的請求頭中通常多了兩個參數,分別是 Cache-Control:no-cache 和 Pragma:no-cache,該參數作用就是請求內容不會被緩存
DNS 功能變數名稱解析
互聯網是通過 URL(統一資源定位符)來發佈和請求資源的,而 URL 中的功能變數名稱需要解析成 IP 地址才能與遠程主機建立連接,如何將功能變數名稱解析成 IP 地址就屬於 DNS 解析的工作範疇。
當用戶在瀏覽器里輸入 www.baidu.com 時,DNS 解析的工作步驟大體如下
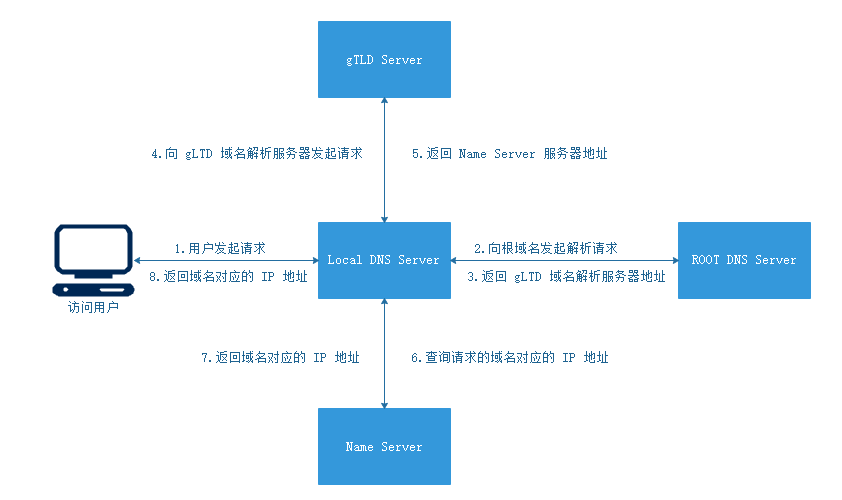
- 首先瀏覽器會先檢查緩存中有沒有這個功能變數名稱對應的解析過的 IP 地址。如果緩存中有,這個解析過程就將結束。功能變數名稱的緩存時間限制可以通過
TTL屬性來設置。 - 如果瀏覽器緩存中沒有,會檢查操作系統中是否有這個功能變數名稱對應的
DNS解析結果,在 Windows 中可以通過C:\Windows\System32\drivers\etc\hosts文件來設置,在 Linux 中這個配置文件是/etc/hosts,修改這個文件同樣可以配置功能變數名稱解析的 IP 結果。 - 如果以上步驟無法完成功能變數名稱的解析,就會真正請求功能變數名稱伺服器來解析這個功能變數名稱了。操作系統會先把功能變數名稱發送給
Local DNS Server,也就是本地區的功能變數名稱伺服器。例如你在學校接入校園網,那麼本地功能變數名稱伺服器肯定在你的學校,如果你是在一個小區接入互聯網,那這個Local DNS Server就是提供給你接入互聯網的應用提供商(電信、移動或聯通),通常會在城市裡的某個角落,不會很遠。 - 如果
Local DNS Server仍然沒有命中,就直接到ROOT DNS Server(根功能變數名稱伺服器)請求解析。 - 根功能變數名稱伺服器會返回給本地功能變數名稱伺服器一個所查詢功能變數名稱的
gLTD Server(主功能變數名稱伺服器)地址,gLTD是國際頂級功能變數名稱伺服器,如.com、.cn等。 Local DNS Server(本地功能變數名稱伺服器)會再向剛纔返回的gTLD Server發送請求。- 接受請求的
gTLD Server查找並返回此功能變數名稱對應的Name Server功能變數名稱伺服器的地址,這個Name Server通常就是你註冊的功能變數名稱服務提供商(例如阿裡雲-萬網)。 Name Server再查詢存儲的功能變數名稱和 IP 的映射關係表,正常情況下,功能變數名稱得到 IP 記錄,連同一個TTL值返回給Local DNS Server(本地功能變數名稱伺服器)。Local DNS Server會緩存這個功能變數名稱和 IP 的對應關係,緩存時間由TTL值控制,最後把解析的結果返回給用戶。
功能變數名稱解析方式
功能變數名稱解析記錄主要分為 A 記錄、MX 記錄、CNAME 記錄、NS 記錄和 TXT 記錄。
- A 記錄:指定功能變數名稱對應的 IP 地址(多個功能變數名稱可以解析到同一個 IP,而一個 IP 只能指向一個功能變數名稱)。
- MX 記錄:將其它某功能變數名稱下的郵件伺服器指向自己的郵件伺服器。
- CNAME 記錄:將一個功能變數名稱指向另一個功能變數名稱。
- NS 記錄:指定 DNS 解析伺服器。
- TXT 記錄:為某個主機名或功能變數名稱設置說明。
CDN 工作機制
CDN 也就是內容分佈網路,以緩存網站中的靜態數據為主,如 CSS、JS、IMG 等數據。用戶先從主站伺服器請求到動態內容後,再從 CDN 上下載這些靜態數據,從而加速網頁數據內容的下載速度。
通常來說 CDN 要達到可擴展性、安全性、可靠性幾個目標。工作步驟如下:
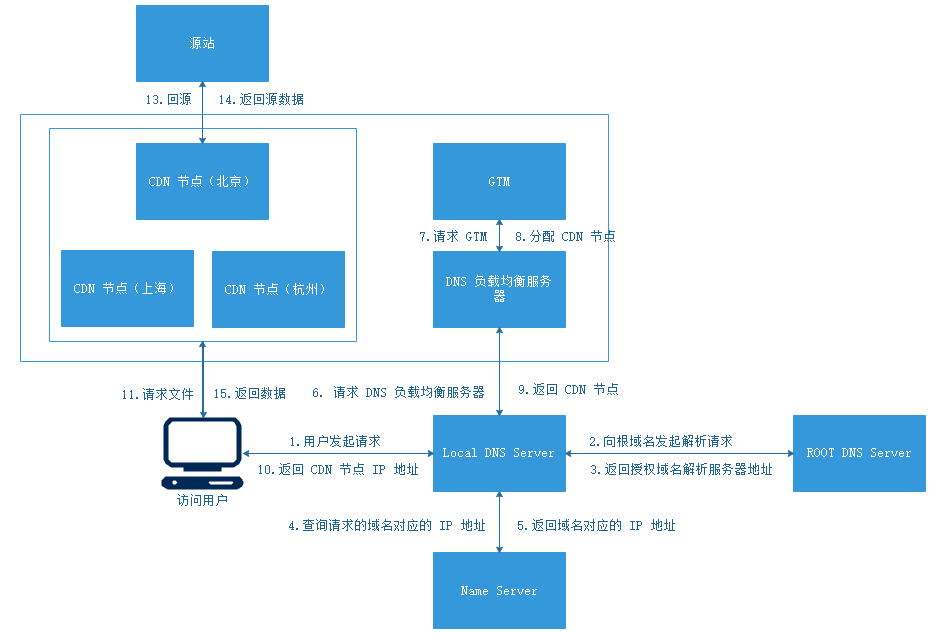
- 首先向
Local DNS Server本地功能變數名稱解析伺服器發起請求,一般經過迭代解析後回到這個功能變數名稱的註冊服務商去解析。 - 通常會有一臺
DNS解析伺服器會把這個功能變數名稱重新CNAME解析到另外一個功能變數名稱,而這個功能變數名稱最終會被指向CDN全局中的DNS負載均衡伺服器,再由GTM根據訪問用戶的地址,返回給離這個訪問用戶最近的CDN節點。 - 拿到
CDN解析結果後,用戶就直接去這個CDN節點訪問這個靜態文件了,如果這個節點中所請求的文件不存在,就會再回到源站去獲取這個文件,然後再返回給用戶。
負載均衡
負載均衡(Load Balance)是對工作任務進行平衡、分攤到多個操作單元上執行,共同完成任務。
它可以提高伺服器響應速度及利用效率,避免軟體出現單點失效,解決網路排塞問題。
通常有三種負載均衡架構:
- 鏈路負載均衡:優點是:不需要經過其它代理伺服器,通常訪問速度會很快,缺點是有緩存,難以及時更新功能變數名稱解析結構。
- 集群負載均衡
- 硬體負載均衡:優點是性能非常好,缺點是非常貴,不能進行動態擴容。
- 軟體負載均衡:優點是成本非常低,缺點是一般一次訪問請求要經過多次代理伺服器,增加網路延時。
- 操作系統負載均衡:利用操作系統級別的軟中斷或者硬中斷來達到負載均衡,如設置多列網卡等來實現。
CDN 動態加速
技術原理:在 CDN 的 DNS 解析中通過動態的鏈路探測來尋找回源最好的一條路徑,然後通過 DNS 的調度將所有請求調度到選定的這條路徑上回源,從而加速用戶訪問的效率。
鏈路探測:在每個 CDN 節點上從源站下載一個一定大小的文件,看哪個鏈路的總耗時最短,這樣就可以構成一個鏈路列表,然後綁定到 DNS 解析上,更新到 Local DNS Server。
- 文章作者:彭超
- 本文首發於個人博客:https://antoniopeng.com/2020/04/07/java/%E6%B7%B1%E5%85%A5Web%E8%AF%B7%E6%B1%82%E8%BF%87%E7%A8%8B/
- 版權聲明:本博客所有文章除特別聲明外,均採用 CC BY-NC-SA 4.0 許可協議。轉載請註明來自 彭超 | Blog!


