
梯度提升樹(GBDT)的全稱是Gradient Boosting Decision Tree。GBDT還有很多的簡稱,例如GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ),GBRT(Gradient Boosting Regressi ...
梯度提升樹(GBDT)的全稱是Gradient Boosting Decision Tree。GBDT還有很多的簡稱,例如GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ),GBRT(Gradient Boosting Regression Tree), MART(Multiple Additive Regression Tree)等,其實都是指的同一種演算法,本文統一簡稱GBDT。
GBDT 也是 Boosting 演算法的一種,但是和 AdaBoost 演算法不同(AdaBoost 演算法上一篇文章已經介紹);區別如下:AdaBoost 演算法是利用前一輪的弱學習器的誤差來更新樣本權重值,然後一輪一輪的迭代;GBDT 也是迭代,使用了前向分佈演算法,但是弱學習器限定了只能使用CART回歸樹模型,而且 GBDT 在模型訓練的時候,是要求模型預測的樣本損失儘可能的小。 首先,GBDT使用的決策樹是CART回歸樹,無論是處理回歸問題還是二分類以及多分類,GBDT使用的決策樹通通都是都是CART回歸樹。因為GBDT每次迭代要擬合的是梯度值,是連續值所以要用回歸樹。對於回歸樹演算法來說最重要的是尋找最佳的劃分點,那麼回歸樹中的可劃分點包含了所有特征的所有可取的值。在分類樹中最佳劃分點的判別標準是熵或者基尼繫數,都是用純度來衡量的,但是在回歸樹中的樣本標簽是連續數值,所以再使用熵之類的指標不再合適,取而代之的是平方誤差,它能很好的評判擬合程度。然後,GBDT的核心在於每一棵樹學的事之前所有樹結論的殘差,殘差其實就是真實值和預測值之間的差值,在學習的過程中,首先學習一顆回歸樹(分類樹的結果顯然是沒辦法累加的,所以GBDT中的樹都是回歸樹),然後將“真實值-預測值”得到殘差,再把殘差作為一個學習目標,學習下一棵回歸樹,依次類推,直到殘差小於某個接近0的閥值或回歸樹數目達到某一閥值。其核心思想是每輪通過擬合殘差來降低損失函數。總的來說,第一棵樹是正常的,之後所有的樹的決策全是由殘差來決定。
最後,使用梯度下降演算法減小損失函數。對於一般損失函數,為了使其取得最小值,通過梯度下降演算法,每次朝著損失函數的負梯度方向逐步移動,最終使得損失函數極小的方法(此方法要求損失函數可導)。梯度提升演算法GBDT其實是一個演算法框架,即可以將已有的分類或回歸演算法放入其中,得到一個性能很強大的演算法。GBDT總共需要進行M次迭代,每次迭代產生一個模型,我們需要讓每次迭代生成的模型對訓練集的損失函數最小,而如何讓損失函數越來越小呢?我們採用梯度下降的方法,在每次迭代時通過向損失函數的負梯度方向移動來使得損失函數越來越小,這樣我們就可以得到越來越精確的模型。
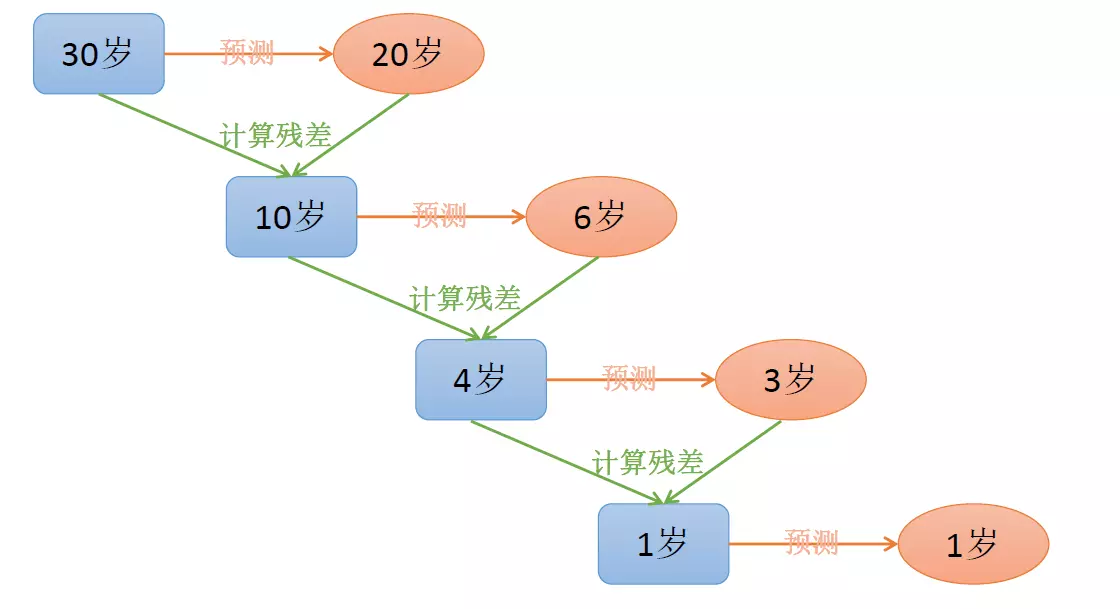
GBDT 直觀理解:每一輪預測和實際值有殘差,下一輪根據殘差再進行預測,最後將所有預測相加,就是結果(不斷去擬合殘差,使殘差不斷減少)。GBDT的思想可以用一個通俗的例子解釋,假如有個人30歲,我們首先用20歲去擬合,發現損失有10歲,這時我們用6歲去擬合剩下的損失,發現差距還有4歲,第三輪我們用3歲擬合剩下的差距,差距就只有一歲了。如果我們的迭代輪數還沒有完,可以繼續迭代下麵,每一輪迭代,擬合的歲數誤差都會減小。
1.GBDT損失函數極小化
在GBDT的迭代中,假設我們前一輪迭代得到的強學習器是$f_{t-1}(x)$, 損失函數是$L(y,f_{t-1}(x))$, 我們本輪迭代的目標是找到一個CART回歸樹模型的弱學習器$h_t(x)$,讓本輪的損失函數$L(y,f_{t}(x) =L(y,f_{t-1}(x)+ h_t(x))$最小。也就是說,本輪迭代找到決策樹,要讓樣本的損失儘量變得更小。即GBDT初始化時(估計使損失函數極小化的常數值,它是只有一個根節點的樹,一般平方損失函數為節點的均值,而絕對損失函數為節點樣本的中位數):
$$f_0(x) = \underset{c}{arg\; min}\sum\limits_{i=1}^{m}L(y_i, c)$$
從上面的例子看這個思想還是蠻簡單的,但是有個問題是這個損失的擬合不好度量,損失函數各種各樣,怎麼找到一種通用的擬合方法呢?
2.GBDT的負梯度擬合
當損失函數是平方損失和指數損失函數時,梯度提升樹每一步優化是很簡單的,但是對於一般損失函數而言,往往每一步優化起來不那麼容易,針對這一問題,Friedman提出了梯度提升樹演算法,這是利用最速下降的近似方法,其關鍵是利用損失函數的負梯度作為提升樹演算法中的殘差的近似值,進而擬合一個CART回歸樹。
對於提到的三種損失函數,其最小化方法各有不同。當損失函數為下麵幾種函數時,最小化損失函數的方法如下:
1. 指數函數:當損失函數為指數函數時,比如AdaBoost演算法的損失函數是指數函數,這時通過前向分步演算法來解決。前向分佈演算法在每輪迭代時,通過將上一輪所生成的模型所產生的損失函數最小化的方法來計算當前模型的參數。
2. 平方誤差損失函數:在回歸樹提升演算法中,遍歷當前輸入樣例的可能取值,將每種可能值計算一遍損失函數,最終選擇損失函數最小的值(很原始)。在計算平方損失誤差時,可能出現殘差項$y-f_{m-1}(x)$,此時可以通過如下方法來進行優化:每一輪迭代是為了減小上一步模型的殘差,為了減少殘差,每次在殘差的負梯度方向建立一個新的模型,這樣一步一步的使得殘差越來越小。
3. 一般損失函數: 對於一般損失函數,可以通過梯度下降的方法來使得損失函數逐步減小,每次向損失函數的負梯度方向移動,直到損失函數值到達谷底。
那麼負梯度長什麼樣呢?第t輪的第i個樣本的損失函數的負梯度表示為:
$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)}$$
此時不同的損失函數將會得到不同的負梯度,假設選擇平方損失:
$$L(y,f(x_i))= 1/2(y-f(x_i))^{2}$$
則負梯度為:$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)}=y-f(x_i)$$
此時發現GBDT的負梯度就是殘差,所以說對於回歸問題,我們要擬合的就是殘差。那麼對於分類問題,二分類和多分類的損失函數都是logloss。因為損失函數有很多種,所以用負梯度擬合來做通用的擬合方法。
3.GBDT中常用的損失函數
在梯度提升分類樹有兩種可選的損失函數,一種是‘exponential:指數損失’,一種是‘deviance:對數損失’;而在梯度提升回歸樹有四種可選的損失函數,分別為'ls:平方損失','lad:絕對損失','huber:huber損失','quantile:分位數損失'。
對於分類演算法,其損失函數一般有對數損失函數和指數損失函數兩種:
1) 如果是指數損失函數,則損失函數表達式為:$$L(y, f(x)) = exp(-yf(x))$$
其負梯度計算和葉子節點的最佳負梯度擬合參見Adaboost演算法原理。
2) 如果是對數損失函數,分為二元分類和多元分類兩種:
對於二元分類,用類似於邏輯回歸的對數似然損失函數:$$L(y, f(x)) = log(1+ exp(-yf(x)))$$
對於多元分類:設類別數為k:$$L(y, f(x)) = - \sum\limits_{k=1}^{K}y_klog\;p_k(x)$$
$y_k$為樣本數據估計值,當一個樣本x屬於k時,$y_k=1$,否則$y_k=0$。
對於回歸演算法,常用損失函數有如下4種:
1)均方差,這個是最常見的回歸損失函數:$$L(y, f(x)) =(y-f(x))^2$$
2)絕對損失,這個損失函數也很常見:$$L(y, f(x)) =|y-f(x)|$$
對應負梯度誤差為:$$sign(y_i-f(x_i))$$
3)Huber損失,它是均方差和絕對損失的折衷產物,對於遠離中心的異常點,採用絕對損失,而中心附近的點採用均方差。這個界限一般用分位數點度量。損失函數如下:
$$L(y, f(x))=\begin{cases}\frac{1}{2}(y-f(x))^2& {|y-f(x)| \leq \delta}\\\delta(|y-f(x)| - \frac{\delta}{2})& {|y-f(x)| > \delta}\end{cases}$$
對應的負梯度誤差為:
$$r(y_i, f(x_i))=\begin{cases}y_i-f(x_i)& {|y_i-f(x_i)| \leq \delta}\\\delta sign(y_i-f(x_i))& {|y_i-f(x_i)| > \delta}\end{cases}$$
4) 分位數損失。它對應的是分位數回歸的損失函數,表達式為:$$L(y, f(x)) =\sum\limits_{y \geq f(x)}\theta|y - f(x)| + \sum\limits_{y < f(x)}(1-\theta)|y - f(x)| $$
其中$\theta$為分位數,需要我們在回歸前指定。對應的負梯度誤差為:
$$r(y_i, f(x_i))=
\begin{cases}
\theta& { y_i \geq f(x_i)}\\
\theta - 1 & {y_i < f(x_i) }
\end{cases}$$
對於Huber損失和分位數損失,主要用於健壯回歸,也就是減少異常點對損失函數的影響。
4.GBDT演算法原理描述
因為分類演算法的輸出是不連續的類別值,需要一些處理才能使用負梯度,所以GBDT的回歸和分類演算法這裡分開介紹。
(1).GBDT回歸演算法基本模版:
輸入是訓練集樣本$T=\{(x_,y_1),(x_2,y_2), ...,(x_m,y_m)\}$, 最大迭代次數T, 損失函數L。
輸出是強學習器 f(x) ,是一顆回歸樹。
1) 初始化弱學習器(估計使損失函數極小化的常數值,它是只有一個根節點的樹,一般平方損失函數為節點的均值,而絕對損失函數為節點樣本的中位數):$$f_0(x) = \underset{c}{arg\; min}\sum\limits_{i=1}^{m}L(y_i, c)$$
2) 對迭代輪數t=1,2,...,T有(即生成的弱學習器個數):
(2.1)對樣本i=1,2,...,m,計算負梯度(損失函數的負梯度在當前模型的值將它作為殘差的估計,對於平方損失函數為,它就是通常所說的殘差;而對於一般損失函數,它就是殘差的近似值(偽殘差)):$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)}$$
(2.2)利用$(x_i,r_{ti})\;\; (i=1,2,..m)$,即$\{(x_1,r_{t1}), ...,(x_i,r_{ti})\}$,擬合一顆CART回歸樹,得到第t顆回歸樹。其對應的葉子節點區域為$R_{tj},j =1,2,...,J$。其中J為回歸樹t的葉子節點的個數。
(2.3)對葉子區域j =1,2,..J,計算最佳擬合值:$$c_{tj} = \underset{c}{arg\; min}\sum\limits_{x_i \in R_{tj}} L(y_i,f_{t-1}(x_i) +c)$$
(2.4)更新強學習器:$$f_{t}(x) = f_{t-1}(x) + \sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj}) $$
3) 得到最終的回歸樹,即強學習器f(x)的表達式:$$f(x) = f_T(x) =f_0(x) + \sum\limits_{t=1}^{T}\sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj})$$
GBDT的分類演算法:GBDT的分類演算法從思想上和GBDT的回歸演算法沒有區別,但是由於樣本輸出不是連續的值,而是離散的類別,導致我們無法直接從輸出類別去擬合類別輸出的誤差。為瞭解決這個問題,主要有兩個方法,一個是用指數損失函數,此時GBDT退化為Adaboost演算法。另一種方法是用類似於邏輯回歸的對數似然損失函數的方法。也就是說,我們用的是類別的預測概率值和真實概率值的差來擬合損失。這裡主要介紹用對數似然損失函數的GBDT分類。而對於對數似然損失函數,我們又有二元分類和多元分類的區別。
(2).二元GBDT分類演算法基本模板(log損失):
輸入:訓練數據集$T=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$,對於二元GBDT用類似於邏輯回歸的對數似然損失函數,損失函數為:$L(y, f(x)) = log(1+ exp(-yf(x)))$。
輸出:分類樹$f(x)$
1)初始化: $$f_0(x) = \frac{1}{2}log \frac{P(y=1|x)}{P(y=-1|x)}$$
2) 對迭代輪數t=1,2,...T有:
(2.1)對樣本i=1,2,...m,計算負梯度
其中$y \in\{-1, +1\}$。則此時的負梯度誤差為:$$r_{ti} = -\bigg[\frac{\partial L(y, f(x_i)))}{\partial f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)} = \frac{y_i}{(1+exp(y_if(x_i)))}$$
(2.2)對概率殘差$\{(x_1,r_{t1}),...,(x_i,r_{ti})\}$擬合一個分類樹,得到第t棵樹的葉節點區域$R_{tj}, j =1,2,..., J$。其中J為回歸樹t的葉子節點的個數
(2.3)對葉子區域j =1,2,..J,即生成的決策樹,計算各個葉子節點的最佳負梯度擬合值為:$$c_{tj} = \underset{c}{arg\; min}\sum\limits_{x_i \in R_{tj}} log(1+exp(-y_i(f_{t-1}(x_i) +c)))$$
由於上式比較難優化,我們一般使用近似值代替:$$c_{tj} =\frac{ \sum\limits_{x_i \in R_{tj}}r_{ti}}{\sum\limits_{x_i \in R_{tj}}|r_{ti}|(1-|r_{ti}|)}$$
(2.4)更新強學習器:$$f_{t}(x) = f_{t-1}(x) + \sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj}) $$
3) 得到最終的分類樹,即強學習器f(x)的表達式:$$f(x) = f_T(x) =f_0(x) + \sum\limits_{t=1}^{T}\sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj})$$
除了負梯度計算和葉子節點的最佳負梯度擬合的線性搜索,二元GBDT分類和GBDT回歸演算法過程相同。
由於我們用的是類別的預測概率值和真實概率值的差來擬合損失,所以最後還要將概率轉換為類別,如下:
$$P(y=1|x) = \frac{1}{1+exp(-f(x))}$$
$$P(y=-1|x) = \frac{1}{1+exp(f(x))}$$
最終輸出比較類別概率大小,概率大的就預測為該類別。
3.多元GBDT分類演算法基本模型(log損失):
多元GBDT要比二元GBDT複雜一些,對應的是多元邏輯回歸和二元邏輯回歸的複雜度差別。
輸入:訓練數據集$T=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$,假設類別數為K,則對數似然損失函數為:$L(y, f(x)) = - \sum\limits_{k=1}^{K}y_klog\;p_k(x) $,={0,1}其中$y_k=\{0,1\}$表示是否屬於第k類別,1表示是,0表示否。$k=1,2,...,K$,表示共有多少分類的類別。
輸出:分類樹$f(x)$
1)初始化:$$f_{k0}(x) = 0,k=1,2,...,K$$
2) 對迭代輪數t=1,2,...,T有:
對樣本i=1,2,...,m,計算樣本點屬於每個類別的概率(其中如果樣本輸出類別為k,則$y_k=1$。第k類的概率):
$$p_k(x) = \frac{exp(f_k(x))}{\sum\limits_{l=1}^{K} exp(f_l(x))} $$
(2.1)對類別k=1,2,...,K:
集合上兩式(損失函數和第k類的概率),可以計算出第$t$輪的第$i$個樣本對應類別$l$的負梯度誤差為$$r_{til} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f_k(x) = f_{l, t-1}\;\; (x)} = y_{il} - p_{l, t-1}(x_i)$$
觀察上式可以看出,其實這裡的誤差就是樣本$i$對應類別$l$的真實概率和$t-1$輪預測概率的差值。
(2.2)對概率偽殘差$\{(x_1,r_{t1l}),...,(x_i,r_{til})\}$擬合一個分類樹。
(2.3)對於生成的決策樹,我們各個葉子節點的最佳負梯度擬合值為$$c_{tjl} = \underset{c_{jl}}{arg\; min}\sum\limits_{i=0}^{m}\sum\limits_{k=1}^{K} L(y_k, f_{t-1, l}(x) + \sum\limits_{j=0}^{J}c_{jl} I(x_i \in R_{tjl}))$$
由於上式比較難優化,我們一般使用近似值代替$$c_{tjl} = \frac{K-1}{K} \; \frac{\sum\limits_{x_i \in R_{tjl}}r_{til}}{\sum\limits_{x_i \in R_{til}}|r_{til}|(1-|r_{til}|)}$$
(2.4)更新強學習器:
$$f_{tk}(x) = f_{t-1,k}(x) + \sum\limits_{j=1}^{J}c_{tkj}I(x \in R_{tkj}) $$
3)得到最終的分類樹,即強學習器f(x)的表達式:$$f(x) = f_{Tk}(x) =f_0(x) + \sum\limits_{t=1}^{T}\sum\limits_{j=1}^{J}c_{tkj}I(x \in R_{tkj})$$
除了負梯度計算和葉子節點的最佳負梯度擬合的線性搜索,多元GBDT分類和二元GBDT分類以及GBDT回歸演算法過程相同。
5.GBDT的正則化
和Adaboost一樣,我們也需要對GBDT進行正則化,防止過擬合。GBDT的正則化主要有三種方式:
(1). Adaboost類似的正則化項,即步長(learning rate)。定義為$\nu$,對於前面的弱學習器的迭代:$f_{k}(x) = f_{k-1}(x) + h_k(x) $
如果我們加上了正則化項,則有:$f_{k}(x) = f_{k-1}(x) + \nu h_k(x) $
$\nu$的取值範圍為$0 < \nu \leq 1 $。對於同樣的訓練集學習效果,較小的$\nu$意味著我們需要更多的弱學習器的迭代次數。通常我們用步長和迭代最大次數一起來決定演算法的擬合效果。
(2). 通過子採樣比例(subsample)。取值為(0,1]。註意這裡的子採樣和隨機森林不一樣,隨機森林使用的是放回抽樣,而這裡是不放回抽樣。如果取值為1,則全部樣本都使用,等於沒有使用子採樣。如果取值小於1,則只有一部分樣本會去做GBDT的決策樹擬合。選擇小於1的比例可以減少方差,即防止過擬合,但是會增加樣本擬合的偏差,因此取值不能太低。推薦在[0.5, 0.8]之間。使用了子採樣的GBDT有時也稱作隨機梯度提升樹(Stochastic Gradient Boosting Tree, SGBT)。由於使用了子採樣,程式可以通過採樣分發到不同的任務去做boosting的迭代過程,最後形成新樹,從而減少弱學習器難以並行學習的弱點。
(3). 對於弱學習器即CART回歸樹進行正則化剪枝。具體可參看決策樹演算法原理。
6.GBDT優缺點
優點:
1.可以靈活處理各種類型的數據,包括連續值和離散值;
2.相對於SVM來說,較少的調參可以達到較好的預測效果;
3.使用健壯的損失函數時,模型魯棒性非常強,受異常值影響小。
缺點:
1. 由於弱學習器之間存在依賴關係,難以並行訓練數據。不過可以通過自採樣的SGBT來達到部分並行。
參考文章:
https://blog.csdn.net/qq_24519677/article/details/82020863
https://blog.csdn.net/zpalyq110/article/details/79527653
https://www.cnblogs.com/pinard/p/6140514.html
https://zhuanlan.zhihu.com/p/51912576
https://www.jianshu.com/p/b954476a00d9


