
線程池原理和使用在面試中被高頻問到,比如阿裡的面試題。下麵我們針對問題來進行回答。 為什麼要使用線程池? 線程池的使用場景有2: 1, 高併發場景:比如tomcat的處理機制,內置了線程池處理http請求; 2,非同步任務處理:比如spring的非同步方法改造,增加@Asyn註解對應了一個線程池; 使用 ...

線程池原理和使用在面試中被高頻問到,比如阿裡的面試題。下麵我們針對問題來進行回答。
為什麼要使用線程池?
線程池的使用場景有2:
1, 高併發場景:比如tomcat的處理機制,內置了線程池處理http請求;
2,非同步任務處理:比如spring的非同步方法改造,增加@Asyn註解對應了一個線程池;
使用線程池帶來的好處有4:
1, 降低系統的消耗:線程池復用了內部的線程對比處理任務的時候創建線程處理完畢銷毀線程降低了線程資源消耗
2,提高系統的響應速度:任務不必等待新線程創建,直接復用線程池的線程執行
3,提高系統的穩定性:線程是重要的系統資源,無限制創建系統會奔潰,線程池復用了線程,系統會更穩定
4,提供了線程的可管理功能:暴露了方法,可以對線程進行調配,優化和監控
線程池的實現原理
線程池處理任務流程
當向線程池中提交一個任務,線程池內部是如何處理任務的?
先來個流程圖,標識一下核心處理步驟:
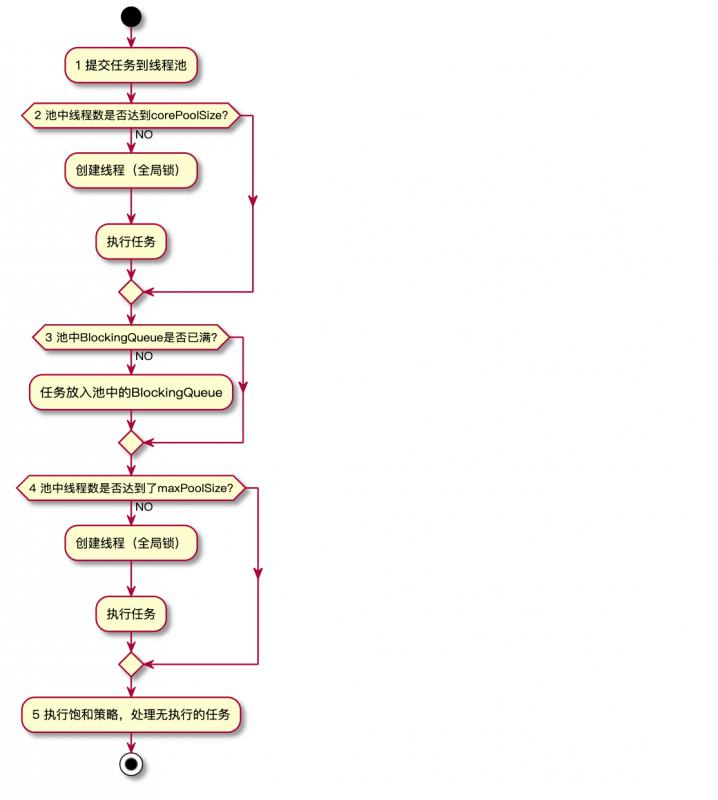
1,線程池內部會獲取activeCount, 判斷活躍線程的數量是否大於等於corePoolSize(核心線程數量),如果沒有,會使用全局鎖鎖定線程池,創建工作線程,處理任務,然後釋放全局鎖;
2,判斷線程池內部的阻塞隊列是否已經滿了,如果沒有,直接把任務放入阻塞隊列;
3,判斷線程池的活躍線程數量是否大於等於maxPoolSize,如果沒有,會使用全局鎖鎖定線程池,創建工作線程,處理任務,然後釋放全局鎖;
4,如果以上條件都滿足,採用飽和處理策略處理任務。
說明:使用全局鎖是一個嚴重的可升縮瓶頸,線上程池預熱之後(即內部線程數量大於等於corePoolSize),任務的處理是直接放入阻塞隊列,這一步是不需要獲得全局鎖的,效率比較高。
源碼如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
註釋沒保留,註釋的內容就是上面畫的流程圖;
代碼的邏輯就是流程圖中的邏輯。
線程池中的線程執行任務
執行任務模型如下:
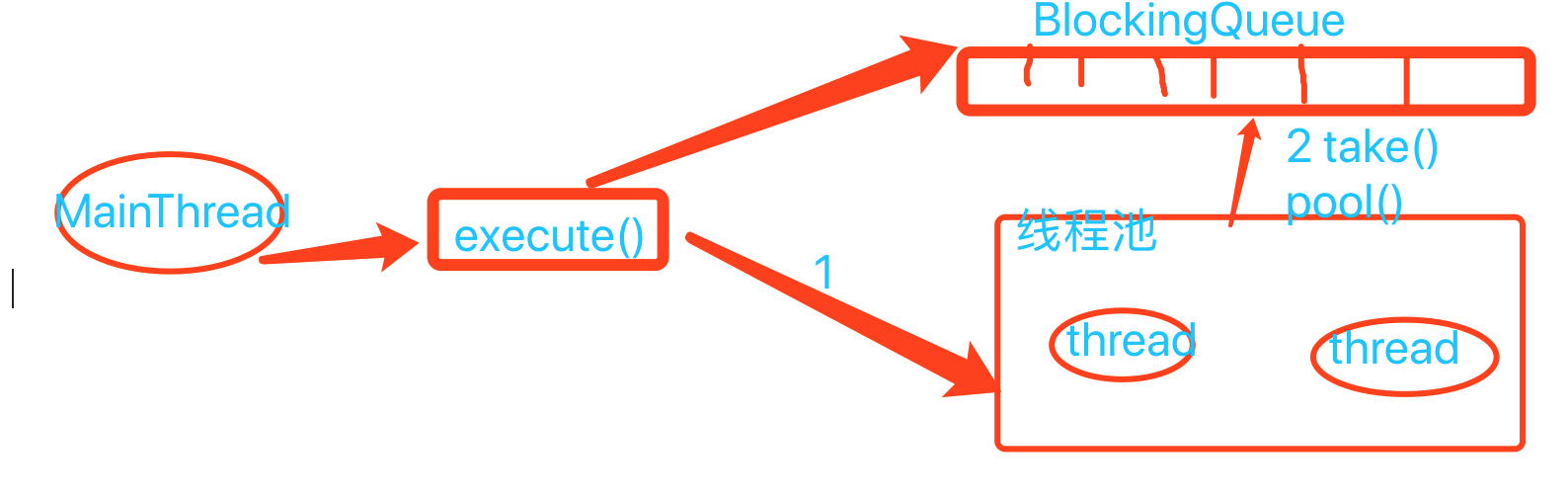
線程池中的線程執行任務分為以下兩種情況:
1, 創建一個線程,會在這個線程中執行當前任務;
2,工作線程完成當前任務之後,會死迴圈從BlockingQueue中獲取任務來執行;
代碼如下:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
//釋放鎖
mainLock.unlock();
}
if (workerAdded) {
//執行提交的任務,然後設置工作線程為啟動狀態
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
從代碼中可以看到:把工作線程增加到線程池,然後釋放鎖,執行完提交進來的任務之後,新建的工作線程狀態為啟動狀態;
線程池的使用
創建線程池
創建線程池使用線程池的構造函數來創建。
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
參數簡單翻譯過來,然後做一下備註:

RejectedExecutionHandler分為4種:
Abort:直接拋出異常
Discard:靜默丟棄最後的任務
DiscardOldest:靜默丟棄最先入隊的任務,並處理當前任務
CallerRuns:調用者線程來執行任務
也可以自定義飽和策略。實現RejectedExecutionHandler即可。
線程池中提交任務
線程池中提交任務的方法有2:
1,void execute(Runable) ,沒有返回值,無法判斷任務的執行狀態。
2,Future
代碼如下:
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
<T> Future<T> submit(Callable<T> task);
關閉線程池
關閉線程池方法有2:
1,shutdown();
2,shutdownNow();
兩種關閉的方法區別如下表:

關閉原理都是調用線程的interrupt()方法來中斷所有的工作線程,所以無法中斷的線程的任務可能永遠沒法終止。
只要調用了以上兩個方法,isShutdown=true;只有所有的工作線程都關閉,isTerminaed=true;
如何合理的配置線程池參數?
分如下場景,參考選擇依據如下:
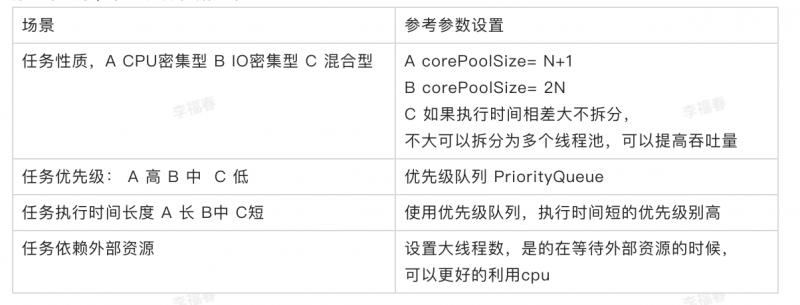
隊列的使用推薦使用有界隊列,提高系統的穩定性和預警能力。
監控線程池
場景:當線程池出現問題,可以根據監控數據快速定位和解決問題。
線程池提供的主要監控參數:
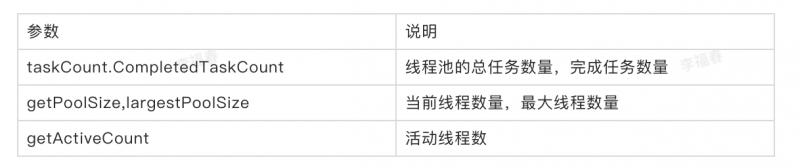
也可以自定義監控,通過自定義線程池,實現beforeExecute,afterExecute,terminated方法,可以在任務執行前,任務執行後,線程池關閉前記錄監控數據。
小結
本篇先從使用場景和優點出發分析了為什麼要使用線程池。
然後介紹了線程池中任務的執行過程,以及工作線程處理任務的兩種方式。
最後介紹瞭如何使用線程池,創建,銷毀,提交任務,監控,設置合理的參數調優等方面。
原創不易,點贊關註支持一下吧!轉載請註明出處,讓我們互通有無,共同進步,歡迎溝通交流。
我會持續分享Java軟體編程知識和程式員發展職業之路,歡迎關註,我整理了這些年編程學習的各種資源,關註公眾號‘李福春持續輸出’,發送'學習資料'分享給你!



