
Mysql主從基本原理,主要形式以及主從同步延遲原理 (讀寫分離)導致主庫從庫數據不一致問題的及解決方案 一、主從資料庫的區別 從資料庫(Slave)是主資料庫的備份,當主資料庫(Master)變化時從資料庫要更新,這些資料庫軟體可以設計更新周期。這是提高信息安全的手段。主從資料庫伺服器不在一個地理 ...
Mysql主從基本原理,主要形式以及主從同步延遲原理 (讀寫分離)導致主庫從庫數據不一致問題的及解決方案
一、主從資料庫的區別
從資料庫(Slave)是主資料庫的備份,當主資料庫(Master)變化時從資料庫要更新,這些資料庫軟體可以設計更新周期。這是提高信息安全的手段。主從資料庫伺服器不在一個地理位置上,當發生意外時資料庫可以保存。
(1) 主從分工
其中Master負責寫操作的負載,也就是說一切寫的操作都在Master上進行,而讀的操作則分攤到Slave上進行。這樣一來的可以大大提高讀取的效率。在一般的互聯網應用中,經過一些數據調查得出結論,讀/寫的比例大概在 10:1左右 ,也就是說大量的數據操作是集中在讀的操作,這也就是為什麼我們會有多個Slave的原因。但是為什麼要分離讀和寫呢?熟悉DB的研發人員都知道,寫操作涉及到鎖的問題,不管是行鎖還是表鎖還是塊鎖,都是比較降低系統執行效率的事情。我們這樣的分離是把寫操作集中在一個節點上,而讀操作其其他的N個節點上進行,從另一個方面有效的提高了讀的效率,保證了系統的高可用性。
(2) 基本過程
1)、Mysql的主從同步就是當master(主庫)發生數據變化的時候,會實時同步到slave(從庫)。
2)、主從複製可以水平擴展資料庫的負載能力,容錯,高可用,數據備份。
3)、不管是delete、update、insert,還是創建函數、存儲過程,都是在master上,當master有操作的時候,slave會快速的接受到這些操作,從而做同步。
(3) 用途和條件
1)、mysql主從複製用途
●實時災備,用於故障切換
●讀寫分離,提供查詢服務
●備份,避免影響業務
2)、主從部署必要條件:
●主庫開啟binlog日誌(設置log-bin參數)
●主從server-id不同
●從庫伺服器能連通主庫
二、主從同步的粒度、原理和形式:
(1)、 三種主要實現粒度
詳細的主從同步主要有三種形式:statement、row、mixed
1)、statement: 會將對資料庫操作的sql語句寫道binlog中
2)、row: 會將每一條數據的變化寫道binlog中。
3)、mixed: statement與row的混合。Mysql決定何時寫statement格式的binlog, 何時寫row格式的binlog。
(2)、主要的實現原理、具體操作、示意圖
1)、在master機器上的操作:
當master上的數據發生變化時,該事件變化會按照順序寫入bin-log中。當slave鏈接到master的時候,master機器會為slave開啟binlog dump線程。當master的binlog發生變化的時候,bin-log dump線程會通知slave,並將相應的binlog內容發送給slave。
2)、在slave機器上操作:
當主從同步開啟的時候,slave上會創建兩個線程:I\O線程。該線程連接到master機器,master機器上的binlog dump 線程會將binlog的內容發送給該I\O線程。該I/O線程接收到binlog內容後,再將內容寫入到本地的relay log;sql線程。該線程讀取到I/O線程寫入的ralay log。並且根據relay log。並且根據relay log 的內容對slave資料庫做相應的操作。
3)、MySQL主從複製原理圖如下:
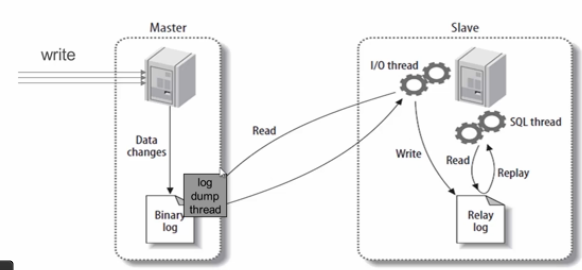
從庫生成兩個線程,一個I/O線程,一個SQL線程;
i/o線程去請求主庫 的binlog,並將得到的binlog日誌寫到relay log(中繼日誌) 文件中;
主庫會生成一個 log dump 線程,用來給從庫 i/o線程傳binlog;
SQL 線程,會讀取relay log文件中的日誌,並解析成具體操作,來實現主從的操作一致,而最終數據一致;
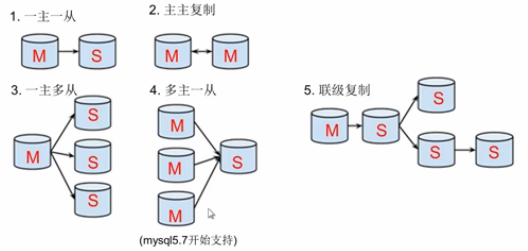
(2)、主從形式
mysql主從複製 靈活
● 一主一從
● 主主複製
● 一主多從---擴展系統讀取的性能,因為讀是在從庫讀取的;
● 多主一從---5.7開始支持
● 聯級複製---
三、主從同步的延遲等問題、原因及解決方案:
(1)、mysql資料庫從庫同步的延遲問題
1)相關參數:
首先在伺服器上執行show slave satus;可以看到很多同步的參數:
Master_Log_File: SLAVE中的I/O線程當前正在讀取的主伺服器二進位日誌文件的名稱 Read_Master_Log_Pos: 在當前的主伺服器二進位日誌中,SLAVE中的I/O線程已經讀取的位置 Relay_Log_File: SQL線程當前正在讀取和執行的中繼日誌文件的名稱 Relay_Log_Pos: 在當前的中繼日誌中,SQL線程已讀取和執行的位置 Relay_Master_Log_File: 由SQL線程執行的包含多數近期事件的主伺服器二進位日誌文件的名稱 Slave_IO_Running: I/O線程是否被啟動併成功地連接到主伺服器上 Slave_SQL_Running: SQL線程是否被啟動 Seconds_Behind_Master: 從屬伺服器SQL線程和從屬伺服器I/O線程之間的時間差距,單位以秒計。
從庫同步延遲情況出現的 ● show slave status顯示參數Seconds_Behind_Master不為0,這個數值可能會很大 ● show slave status顯示參數Relay_Master_Log_File和Master_Log_File顯示bin-log的編號相差很大,說明bin-log在從庫上沒有及時同步,所以近期執行的bin-log和當前IO線程所讀的bin-log相差很大 ● mysql的從庫數據目錄下存在大量mysql-relay-log日誌,該日誌同步完成之後就會被系統自動刪除,存在大量日誌,說明主從同步延遲很厲害
(2)、MySql資料庫從庫同步的延遲問題
1)、MySQL資料庫主從同步延遲原理mysql主從同步原理:主庫針對寫操作,順序寫binlog,從庫單線程去主庫順序讀”寫操作的binlog”,從庫取到binlog在本地原樣執行(隨機寫),來保證主從數據邏輯上一致。mysql的主從複製都是單線程的操作,主庫對所有DDL和DML產生binlog,binlog是順序寫,所以效率很高,slave的Slave_IO_Running線程到主庫取日誌,效率比較高,下一步,問題來了,slave的Slave_SQL_Running線程將主庫的DDL和DML操作在slave實施。DML和DDL的IO操作是隨即的,不是順序的,成本高很多,還可能可slave上的其他查詢產生lock爭用,由於Slave_SQL_Running也是單線程的,所以一個DDL卡主了,需要執行10分鐘,那麼所有之後的DDL會等待這個DDL執行完才會繼續執行,這就導致了延時。有朋友會問:“主庫上那個相同的DDL也需要執行10分,為什麼slave會延時?”,答案是master可以併發,Slave_SQL_Running線程卻不可以。
2)、MySQL資料庫主從同步延遲是怎麼產生的?當主庫的TPS併發較高時,產生的DDL數量超過slave一個sql線程所能承受的範圍,那麼延時就產生了,當然還有就是可能與slave的大型query語句產生了鎖等待。首要原因:資料庫在業務上讀寫壓力太大,CPU計算負荷大,網卡負荷大,硬碟隨機IO太高次要原因:讀寫binlog帶來的性能影響,網路傳輸延遲。
(3)、MySql資料庫從庫同步的延遲解決方案
1)、架構方面
1.業務的持久化層的實現採用分庫架構,mysql服務可平行擴展,分散壓力。
2.單個庫讀寫分離,一主多從,主寫從讀,分散壓力。這樣從庫壓力比主庫高,保護主庫。
3.服務的基礎架構在業務和mysql之間加入memcache或者redis的cache層。降低mysql的讀壓力。
4.不同業務的mysql物理上放在不同機器,分散壓力。
5.使用比主庫更好的硬體設備作為slave總結,mysql壓力小,延遲自然會變小。
2)、硬體方面
1.採用好伺服器,比如4u比2u性能明顯好,2u比1u性能明顯好。
2.存儲用ssd或者盤陣或者san,提升隨機寫的性能。
3.主從間保證處在同一個交換機下麵,並且是萬兆環境。
總結,硬體強勁,延遲自然會變小。一句話,縮小延遲的解決方案就是花錢和花時間。
3)、mysql主從同步加速
1、sync_binlog在slave端設置為0
2、–logs-slave-updates 從伺服器從主伺服器接收到的更新不記入它的二進位日誌。
3、直接禁用slave端的binlog
4、slave端,如果使用的存儲引擎是innodb,innodb_flush_log_at_trx_commit =2
4)、從文件系統本身屬性角度優化
master端修改linux、Unix文件系統中文件的etime屬性, 由於每當讀文件時OS都會將讀取操作發生的時間回寫到磁碟上,對於讀操作頻繁的資料庫文件來說這是沒必要的,只會增加磁碟系統的負擔影響I/O性能。可以通過設置文件系統的mount屬性,組織操作系統寫atime信息,在linux上的操作為:打開/etc/fstab,加上noatime參數/dev/sdb1 /data reiserfs noatime 1 2然後重新mount文件系統#mount -oremount /data
5)、同步參數調整主庫是寫,對數據安全性較高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之類的設置是需要的而slave則不需要這麼高的數據安全,完全可以講sync_binlog設置為0或者關閉binlog,innodb_flushlog也可以設置為0來提高sql的執行效率
1、sync_binlog=1 oMySQL提供一個sync_binlog參數來控制資料庫的binlog刷到磁碟上去。預設,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系統自己控制它的緩存的刷新。這時候的性能是最好的,但是風險也是最大的。一旦系統Crash,在binlog_cache中的所有binlog信息都會被丟失。
如果sync_binlog>0,表示每sync_binlog次事務提交,MySQL調用文件系統的刷新操作將緩存刷下去。最安全的就是sync_binlog=1了,表示每次事務提交,MySQL都會把binlog刷下去,是最安全但是性能損耗最大的設置。這樣的話,在資料庫所在的主機操作系統損壞或者突然掉電的情況下,系統才有可能丟失1個事務的數據。但是binlog雖然是順序IO,但是設置sync_binlog=1,多個事務同時提交,同樣很大的影響MySQL和IO性能。雖然可以通過group commit的補丁緩解,但是刷新的頻率過高對IO的影響也非常大。
對於高併發事務的系統來說,“sync_binlog”設置為0和設置為1的系統寫入性能差距可能高達5倍甚至更多。所以很多MySQL DBA設置的sync_binlog並不是最安全的1,而是2或者是0。這樣犧牲一定的一致性,可以獲得更高的併發和性能。預設情況下,並不是每次寫入時都將binlog與硬碟同步。因此如果操作系統或機器(不僅僅是MySQL伺服器)崩潰,有可能binlog中最後的語句丟失了。要想防止這種情況,你可以使用sync_binlog全局變數(1是最安全的值,但也是最慢的),使binlog在每N次binlog寫入後與硬碟同步。即使sync_binlog設置為1,出現崩潰時,也有可能表內容和binlog內容之間存在不一致性。
2、innodb_flush_log_at_trx_commit (這個很管用)抱怨Innodb比MyISAM慢 100倍?那麼你大概是忘了調整這個值。預設值1的意思是每一次事務提交或事務外的指令都需要把日誌寫入(flush)硬碟,這是很費時的。特別是使用電池供電緩存(Battery backed up cache)時。設成2對於很多運用,特別是從MyISAM表轉過來的是可以的,它的意思是不寫入硬碟而是寫入系統緩存。日誌仍然會每秒flush到硬 盤,所以你一般不會丟失超過1-2秒的更新。設成0會更快一點,但安全方面比較差,即使MySQL掛了也可能會丟失事務的數據。而值2只會在整個操作系統 掛了時才可能丟數據。
3、ls(1) 命令可用來列出文件的 atime、ctime 和 mtime。
atime 文件的access time 在讀取文件或者執行文件時更改的ctime 文件的create time 在寫入文件,更改所有者,許可權或鏈接設置時隨inode的內容更改而更改mtime 文件的modified time 在寫入文件時隨文件內容的更改而更改ls -lc filename 列出文件的 ctimels -lu filename 列出文件的 atimels -l filename 列出文件的 mtimestat filename 列出atime,mtime,ctimeatime不一定在訪問文件之後被修改因為:使用ext3文件系統的時候,如果在mount的時候使用了noatime參數那麼就不會更新atime信息。這三個time stamp都放在 inode 中.如果mtime,atime 修改,inode 就一定會改, 既然 inode 改了,那ctime也就跟著改了.之所以在 mount option 中使用 noatime, 就是不想file system 做太多的修改, 而改善讀取效能
(4)、MySql資料庫從庫同步其他問題及解決方案
1)、mysql主從複製存在的問題: ● 主庫宕機後,數據可能丟失 ● 從庫只有一個sql Thread,主庫寫壓力大,複製很可能延時2)、解決方法: ● 半同步複製---解決數據丟失的問題 ● 並行複製----解決從庫複製延遲的問題
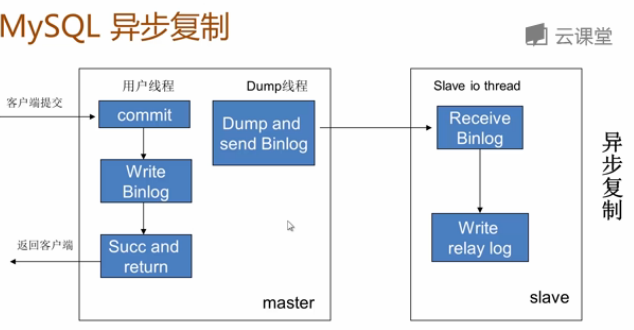
3)、半同步複製mysql semi-sync(半同步複製)半同步複製: ● 5.5集成到mysql,以插件的形式存在,需要單獨安裝 ● 確保事務提交後binlog至少傳輸到一個從庫 ● 不保證從庫應用完這個事務的binlog ● 性能有一定的降低,響應時間會更長 ● 網路異常或從庫宕機,卡主主庫,直到超時或從庫恢復4)、主從複製--非同步複製原理、半同步複製和並行複製原理比較
a、非同步複製原理:
b、半同步複製原理:
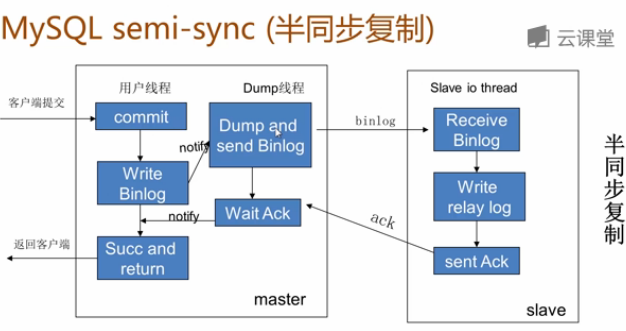
事務在主庫寫完binlog後需要從庫返回一個已接受,才放回給客戶端;5.5集成到mysql,以插件的形式存在,需要單獨安裝確保事務提交後binlog至少傳輸到一個從庫不保證從庫應用完成這個事務的binlog性能有一定的降低網路異常或從庫宕機,卡主庫,直到超時或從庫恢復
c、並行複製mysql並行複製 ● 社區版5.6中新增 ● 並行是指從庫多線程apply binlog ● 庫級別並行應用binlog,同一個庫數據更改還是串列的(5.7版並行複製基於事務組)設置set global slave_parallel_workers=10;設置sql線程數為10
原理:從庫多線程apply binlog在社區5.6中新增庫級別並行應用binlog,同一個庫數據更改還是串列的5.7版本並行複製基於事務組
參考:https://blog.csdn.net/hao_yunfeng/article/details/82392261

