
前言: 還記得那是2018年的一個夏天,天氣特別熱,我一邊擦汗一邊聽領導大刀闊斧的講述自己未來的改革藍圖。會議開完了,核心思想就是:我們要搞一個數據大池子,要把公司能灌的數據都灌入這個大池子,然後讓別人用 各種姿勢 來撈這些數據。系統從開始打造到上線差不多花了半年多不到一年的時間,線上穩定運行也有一 ...
前言:還記得那是2018年的一個夏天,天氣特別熱,我一邊擦汗一邊聽領導大刀闊斧的講述自己未來的改革藍圖。會議開完了,核心思想就是:我們要搞一個數據大池子,要把公司能灌的數據都灌入這個大池子,然後讓別人用 各種姿勢 來撈這些數據。系統從開始打造到上線差不多花了半年多不到一年的時間,線上穩定運行也有一年多的時間。今天想簡單做個總結。
一。背景介紹
公司成立差不多十五六年了,老公司了。也正是因為資格老,業務迭代太多了,各個業務線錯綜複雜,介面調用也密密麻麻。有時候A向B要數據,有時候B向C要介面,有時候C向A要服務;各個業務線各有各的財產,各自為營,像一個個小諸侯擁兵自重,跑腿費會議費都貴的很。面對這個現狀,我們急需進行一波大改造了。
而這個系統(我們暫且叫它天池吧),正是為了整合公司各個業務線的資源,改造這個錯綜複雜的蜘蛛網為簡單的直線班車。省去不必要的介面調用、業務穿插、會議溝通以及不知去哪裡拿數據、拿不到數據、拿數據慢的困擾。當然,更節省了產品、開發人員的時間,提升了各業務線整體工作效率。
幾個詞形容一下天池:穩、快、大、省、清晰。
二。業務梳理
經過對公司各線業務進行梳理,總結出以下幾大常見的數據輸出模型:
-
Key-Value快速輸出型,最簡單的kv查詢,併發量可能很高,速度要求快。比如風控。
-
Key-Map快速輸出型,定向輸出,比如常見的通過文章id獲取文章詳情數據,kv查詢升級版。
-
MultiKey-Map批量輸出型,比如常見的推薦Feed流展示,Key-Map查詢升級版。
-
C-List多維查詢輸出型,指定多個條件進行數據過濾,條件可能很靈活,分頁輸出滿足條件的數據。這應該是非常常見的,比如篩選指定標簽或打分的商品進行推薦、獲取指定用戶過去某段時間買過的商品等等。
-
G-Top統計排行輸出型,根據某些維度分組,展示排行。如獲取某論壇熱度最高Top10帖子。
-
G-Count統計分析輸出型,數倉統計分析型需求。
-
Multi-Table混合輸出型,且不同表查詢條件不同,如列表頁混排輸出內容。
-
Term分詞輸出型
或許還有更多數據模型,這裡就不再列舉了。從前端到後臺,無論再多數據模型,其實都可以轉化為索引+KV的形式進行輸出,甚至有時候,我覺得索引+KV>SQL。
基於此業務數據模型分析及公司對ElasticSearch的長期使用,我們最終選擇了HBase + ElasticSearch這樣的技術方案來實現。
三。架構設計與模塊介紹
先看一下整體架構圖,如下圖:
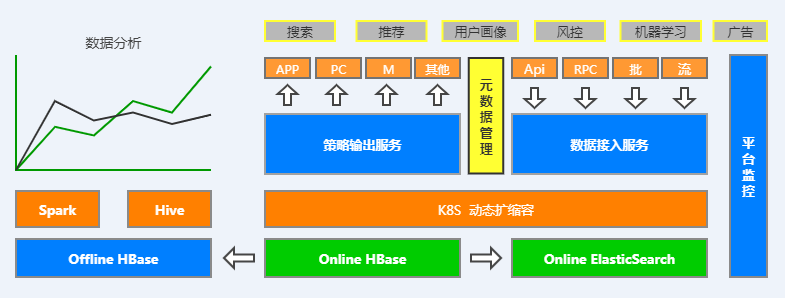
整個天池系統核心主要分為數據接入層、策略輸出層、元數據管理、索引建立、平臺監控以及離線數據分析六大子模塊,下麵將分別對其進行介紹。
1. 數據接入模塊介紹
數據接入模塊我們主要對HBase-Client API進行了二次輕封裝,支持線上RESTFUL服務介面和離線SDK包兩種主要方式對外提供服務,同時相容HBase原生API和HBase BulkLoad大批量數據寫入。
其中,線上RESTFUL服務以HBase Connection長連接的方式對外提供服務,好處是:在性能影響不大的情況下方便跨語言操作,更主要的一點是便於管理。在這一層,可以做很多工作,比如許可權管理、負載均衡、失敗恢復、動態擴縮容、數據介面監控等等,當然這一切都要感謝K8S的強大能力。
2. 策略輸出模塊介紹
該模塊主要就是對接我們上文業務梳理模塊歸納的各種業務需求,都由此模塊提供服務。顧名思義,策略模塊主要用於為用戶配置策略,或用戶自己配置策略,最終基於策略生成策略ID。
這一層我們主要是對ElasticSearch和HBase的一些封裝,通過動態模板將用戶請求轉化為ElasticSearch DSL語句,而後對ES進行查詢,直接返回數據或是獲取到rowkey進而查詢HBase進行結果返回。
通過元數據管理中心,我們可以判斷出用戶所需欄位是否被索引欄位覆蓋,是否有必要二次查詢HBase返回結果。而這整個查詢過程,用戶並不會感知,他們只需要一個PolicyID即可。
當然,我們也在不斷普及用戶如何通過後臺自己配置生成策略。合作較多的業務方,甚至可以自己在測試環境配置好一切,完成數據的自助獲取工作。而我們需要做的,只是一鍵同步測試環境的策略到線上環境,並通知他們線上已可用。整個過程5~10分鐘,一個新的介面就誕生了。
其次,由於ES抗壓能力畢竟不如HBase猛,我們的策略介面也會根據業務需求決定是否開啟緩存。事實上,大部分介面是可以接受短時間內數據緩存的。當然像簡單KV、K-Map、Mk-Map這種是直接走HBase的,需求量也挺大。
到目前為止,上述業務輸出模型基本都已支持動態策略配置。這真的要感謝ElasticSearch強大的語法和業務場景覆蓋能力,畢竟在我看來,ElasticSearch更像是一個為業務而生的產品。深入瞭解ES後,你會發現在有些方面它真的比SQL更強大;現在我們的策略平臺甚至支持分詞查詢、分桶查詢、多表聯合查詢、TopN、聚合查詢等多種複合查詢,這都要感謝ElasticSearch強大的功能。
3. 元數據管理模塊介紹
大家都知道HBase是No-Schema模型,元數據管理層我們也就是為其和ES做一個虛擬的Schema管理,同時去動態控制哪些欄位要建索引。在數據接入的時候,我們會通過元數據中心判斷數據是否符合規則(我們自己定的一些規則);在數據輸出的時候,我們控制哪些策略需要走緩存,哪些策略不需要走HBase等等。其次,維護一套元數據方便我們做一些簡單的頁面指標監控,並對ES和HBase有一個匯流排控制(如建表刪表等),該模塊就不多說了。
4. 索引建立模塊介紹
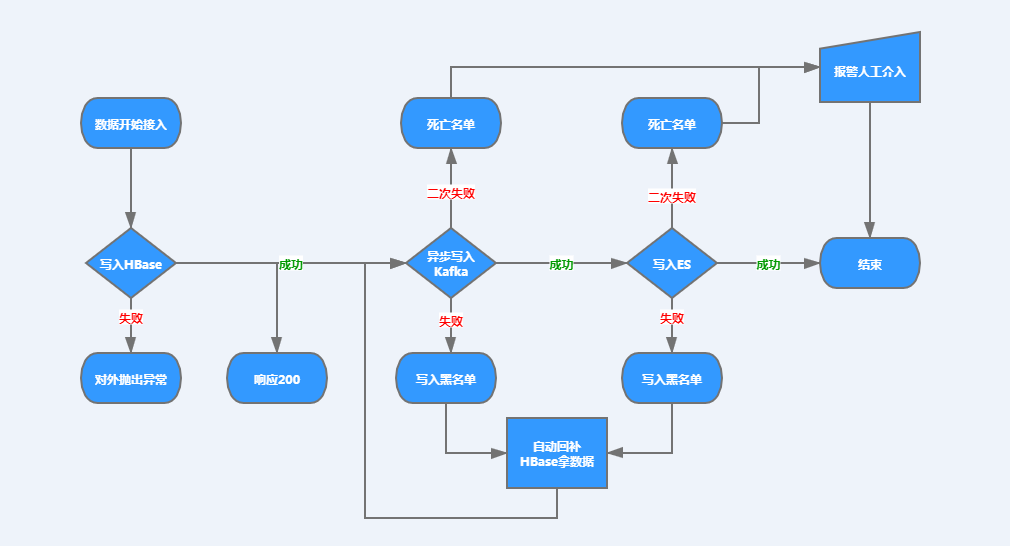
這個模塊呢,其實算是相對比較複雜的一個模塊。我們沒有採用HBase + WAL + ES的方式而是HBase + Kafka + ES 的方式去同步索引數據。一是因為WAL層不太好控制和監控,二是ES消費WAL的效率問題,三是WAL層數據一致性不好維護。
所以我們把一部分的工作放到了數據接入層,在數據寫完HBase之後,即對外響應Success並非同步將數據推至Kafak隊列中等待ES去二次消費;寫入失敗則對外拋出異常,我們首先要保證的是,寫入HBase要麼成功,要麼失敗。
在ES消費層,我們是可以動態指定消費線程數量的。當Kafka Lag堆積超過一定閾值(閾值可進行Group級調節和監控),會進行警報,並動態調整消費線程數。
在數據一致性方面,我們也做了大量工作,且我們只保證數據最終一致性。當數據寫入HBase成功之後,我們會對寫Kafka和寫ES進行鏈路追蹤,任何一個環節一旦寫入失敗,即將Failed Key寫入黑名單(Redis存儲)。
對於進入黑名單的數據,我們會起定時調度線程去掃描這些Key併進行自動回補索引。回補方式是:到HBase中拿最新的數據再次寫入隊列中去。如果此時又失敗,我們會把這些Key放入終極死亡名單(Redis存儲),並通過定時調度線程去掃描這個死亡名單,如果有屍體,則報警,此時人力介入。
這種分層處理方式,也是借鑒了些許HBase LSM的思想,勿噴勿噴~
我簡單畫了一下這個流程,方便大家理解,見下圖:
5. 平臺監控模塊介紹
該模塊不再細說了,主要是Hadoop集群、HBase集群的監控,外加K8S平臺監控。K8S監控平臺主要基於Prometheus+Grafana+Fluent實現。
6. 離線數據分析模塊介紹
該模塊依賴於HBase Replication集群間複製功能實現。數據在同步至離線HBase集群之後,主要用於對接數據倉庫、Spark讀寫分析、大範圍掃描操作等等。主要是減小面向分析型作業對線上實時平臺的影響。
六大模塊就簡單介紹到這裡。
四。心得
總的感受:使用ES賦能HBase感覺很融洽,ES很棒,ES+HBase真的可以媲美SQL了。
好像ES天生跟HBase是一家人,HBase支持動態列,ES也支持動態列,這使得兩者結合在一起很融洽。而ES強大的索引功能正好是HBase所不具備的,如果只是將業務索引欄位存入ES中,體量其實並不大;甚至很多情況下,業務索引欄位60%以上都是Term類型,根本不需要分詞。雖然我們還是支持了分詞,比如多標簽索引就會用到。
很多設計者可能會覺得HBase + Kafka + ES三者結合在一起有點太重了,運維成本很高,有點望而卻步。但轉換角度想一下,我們不就是搞技術的嘛,這下子可以三個成熟產品一起學了!現在看來,收穫還是大於付出的。
至於ES和Solr選擇誰去做二級索引的問題,我覺得差別不大,根據自家公司的現狀做選擇就好了。
最後,還是要為ElasticSearch點個贊!不錯的產品!
五。未來要做的事
- 多租戶全鏈路打通
- 策略層SQL支持
- 系統不斷優化、產品化

轉載請註明出處!歡迎關註本人微信公眾號【HBase工作筆記】


