
在JavaScript中,正則表達式由RegExp對象表示。RegExp對象呢,又可以通過直接量和構造函數RegExp兩種方式創建,分別如下: 其中,末尾的可選字元(g、i和m)分別表示: g: 模式執行一個全局匹配。簡而言之,就是找到所有匹配,而不是在找到第一個之後就停止。 i: 模式執行不區分大 ...
在JavaScript中,正則表達式由RegExp對象表示。RegExp對象呢,又可以通過直接量和構造函數RegExp兩種方式創建,分別如下:
//直接量 var re = /pattern/[g | i | m];
//構造函數 var re = new RegExp(["pattern", ["g" | "i" | "m"]]);
其中,末尾的可選字元(g、i和m)分別表示:
g: 模式執行一個全局匹配。簡而言之,就是找到所有匹配,而不是在找到第一個之後就停止。
i: 模式執行不區分大小寫的匹配。
m: 多行模式,^和$錨除了匹配字元串的開頭和結尾外,還匹配每行的開頭和結尾。例如,模式/Java$/m匹配"Java"和"Java\nScript"。
| 基礎篇 |
--特殊字元--
在正則表達式中,所有的字母字元和數字都可以按照直接量與自身匹配,如/JavaScript/匹配的就是字元串"JavaScript",但是有些特殊字元呢?如換行符。所以在JavaScript中規定以反斜杠(\)開頭的轉義序列支持這些特殊字元。常用的特殊字元如下:
|
轉義字元 |
匹配 |
|
\n |
換行符 |
|
\r |
回車 |
|
\f |
換頁符 |
|
\t |
製表符 |
|
\v |
垂直製表符 |
--字元類--
在正則表達式中,倘若將單獨的字元放入方括弧([ ])中,就可以組合成字元類。應用到匹配字元串中,我們可以將其看成一個漏斗,當字元串中的每個字元通過它時,都查找是否在這個類裡面,如若在,就匹配成功,否則out。如下:
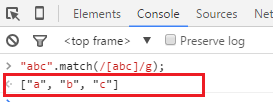
/* match為字元串的方法,它的唯一參數就是一個正則表達式, 如果該正則表達式設置了標誌g,該方法返回的數組包含的就是出現在字元串中的所有匹配。 詳細的用法將在下麵“正則表達式在String中的應用”細講 */ "abc".match(/[abc]/g);
匹配結果為:
如果我們的意願是,想匹配除字元a、b、c之外的字元呢?我們可以定義一個否定類,只需將^符號放入[ ]中作為開頭就OK啦。如下:
"abc".match(/[^abc]/g);
由於某些字元類經常用到,固JavaScript的正則表達式就用反斜杠(\)與一些特殊字元組合起來表示這些常用類,而不必再需要我們自行添加,如\d。
常用正則字元類如下:
|
字元類 |
匹配 |
例子 |
|
[ …] |
位於方括弧之中的任意字元 |
/M[onke]y/ 匹配 "Moy" |
|
[ ^…] |
除包含在方括弧之中的任意字元 |
/M[^onke]y/ 匹配 "May" |
|
. |
除換行符之外的任意字元 |
/../ 匹配 "Mo" |
|
\w |
字母、數字或下劃線 |
/1\w/ 匹配 "1A" |
|
\W |
除字母、數字和下劃線之外的字元 |
/1\W/ 匹配 "1%" |
|
\s |
單個空白字元 |
/M\sK/ 匹配 "M K" |
|
\S |
單個非空白字元 |
/M\SK/ 匹配 "M_K" |
|
\d |
0到9的數字 |
/\d/ 匹配 "1" |
|
\D |
非數字 |
/\D/ 匹配 "M" |
--重覆匹配--
當我們需要匹配三位數字時,我們可以這樣:/\d\d\d/,但是當我們需要匹配10位或者更多時呢?考慮到這一點,正則表達式為我們提供了重覆字元{ n, m },表示匹配前一項至少n次,但是不能超過m次。例如,剛纔我們所說的匹配三位數字時,我們可以利用重覆字元這樣啦:/\d{3}/。
由於某些重覆類型經常用到,so,正則規定一些特殊字元表示這些重覆類型。
正則重覆字元,詳情見下:
|
字元 |
含義 |
例子 |
|
{n, m} |
匹配前一項至少n次,但不能超過m次 |
/\d{2,3}/ 匹配"12" |
|
{n, } |
匹配前一項至少n次,或者更多 |
/\d{2, }/ 匹配"123" |
|
{n} |
匹配前一項恰好n次 |
/\d{2}/ 匹配"12" |
|
? |
匹配前一項0次或者1次,等價於{0,1} |
/\d?/ 匹配"2" |
|
+ |
匹配前一項1次或者多次,等價於{1, } |
/\d+/ 匹配"12" |
|
* |
匹配前一項0次或者多次,等價於{0, } |
/\d*/ 匹配"12" |
另,以上重覆字元重覆規則為:儘可能多的匹配,即俗稱的“貪婪匹配”,如:"aaaa".match(/a+/);匹配的就是整個字元串"aaaa",而不是匹配到第一個字元a時,就放棄匹配。
那麼,有所謂的"貪婪匹配",就有"非貪婪匹配",它的規則嘛,肯定與"貪婪匹配"相反咯,即:儘可能少的匹配。
那麼,怎麼才能觸發非貪婪模式呢?
只需要在重覆字元後加入?,就ok啦,如({1, 4}?、+?等),如"aaaa".match(/a+?/);就只會匹配首個字元a咯。
註意,是儘可能少的匹配,而不是少的匹配哦。
神馬意思?如下:
"aaab".match(/a*b/);
"aaab".match(/a*?b/);
!匹配結果都是"aaab"!
有沒有點詫異,為什麼"aaab".match(/a*?b/);的匹配結果會是"aaab",而不是"ab"呢?
那是因為正則匹配都是從左往右的,就"aaab".match(/a*?b/);而言,當遇到首字元a時,它會繼續往下匹配,直到能符合匹配模式/a*?b/為止,這就是為什麼說是儘可能少的匹配,前提是滿足匹配規則。
如"abbb".match(/ab*?/)的匹配結果就是"a"啦。
--字元 |、( )、(?: …)--
1.1、字元" | " 用於分隔,表示或。
什麼意思?
舉個慄子,如/ab | cd | ef/就可以匹配字元串"ab"或者"cd"或者"ef"。
是不是和字元類[ ]很像啊?
是的,如/a | b | c/和/[abc]/匹配效果是一樣的哦。
But,字元類[ ]僅針對單個字元而言,而分隔字元" | "涉及更廣,可以針對多個字元而言,如上述所說的/ab | cd | ef/,字元類就不行咯。
你可能會說,如果我想對利用" | "組裝的類進行多次匹配呢?
加個括弧就是啦。如:
/(ab | cd |ef)+/
好滴,說到括弧,我們再來看看它的作用。非常強大哦。
1.2、括弧"( )"
括弧的作用如下:
1、我們可以將一個單獨的項目組合成一個子表達式,以便我們可以用|、*等來處理它。如,上訴所示的/(ab | cd | ef)+/。
2、利用括弧括起來的部分,我們可以在正則表達式的後面引用前面用括弧括起來的子表達式的匹配結果,註意是結果,而不是括起來的正則表達式。
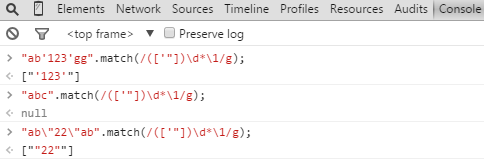
針對第二點,有什麼用呢?如我們有個需求,我想匹配在單引號或者雙引號中的數字(’12345’)時,我們就可輕而易舉利用這第二點,寫好正則表達式,如下:
/(['"])\d*\1/
測試結果如下:
好了,就第二點作用而言,結合上述demo,我們再來看看它的具體引用法則吧:
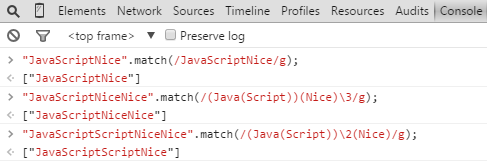
----以反斜杠\加數字的方式,引用前面帶括弧的子表達式,而這個數字呢指的就是第幾個子表達式,計算規則為從左往右,計算遇到的左括弧" ( ",到想引用的地方位置為止,無論在括弧中還嵌套不嵌套括弧。
測試Demo如下:
咦,倘若我只想讓括弧的作用為分組,而不想在後面計入引用呢?畢竟括弧多了,不好計算呢。
那麼,我們就來看看字元(?: …)咯。
1.3、(?: …)
(?: …)的作用就是,規定括弧只用於分組,而不計入後面的引用,不好理解,看個demo就明白啦。如下:
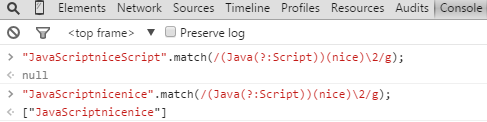
/(Java(?:Script))(nice)/
如果我想在末尾引用子表達式nice,那麼是\2,而不是\3咯,因為用(?: …)來分組滴,只管分組,而不引用,切記切記。
對(?: …)的測試demo如下:
--匹配位置--
在前面我們提到,創建正則對象時,可選字元m表示:多行模式,^和$錨除了匹配字元串的開頭和結尾外,還匹配每行的開頭和結尾。
那麼這個^和$就是正則為我們提供的匹配位置,即所謂的錨。
例如:
將/JavaScript/變為/^JavaScript/,就只匹配字元串中開頭為JavaScript的啦,如匹配"JavaScriptxxx"中的JavaScript,而不匹配"xxxJavaScript"中的JavaScript。
正則表達式中的錨字元詳情見下:
|
字元 |
含義 |
|
^ |
匹配字元串的開頭 |
|
$ |
匹配字元串的結尾 |
|
\b |
匹配一個詞語的邊界,指[a-zA-Z_0-9]之外的字元 |
|
\B |
匹配非詞語邊界位置 |
|
(? = p) |
正前向聲明,exp1(?=exp2),匹配後面是exp2的exp1 |
|
(? ! p) |
反前向聲明,exp1(?!exp2),匹配後面不是exp2的exp1 |
^和$好理解,但是\b、(?=)、(?!)可能比較陌生,結合上表,我們再來看看下麵的demo就好啦。
對於\b的Demo如下:

對於(? = p)的Demo如下:
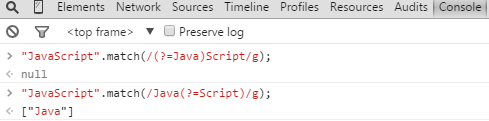
對於(? ! p)的Demo如下:
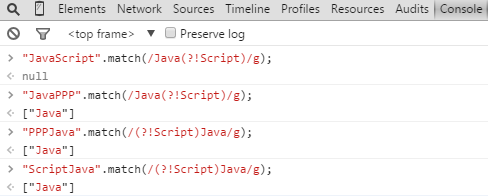
哎,本想一氣呵成,沒想到寫完基礎篇發現已經這麼晚了。。。有時間再梳理下正則表達式在JavaScript中的應用吧。
晚安,everyone~


