
使用UUID或者GUID產生的ID沒有規則 Snowflake演算法是Twitter的工程師為實現遞增而不重覆的ID實現的 概述 分散式系統中,有一些需要使用全局唯一ID的場景,這種時候為了防止ID衝突可以使用36位的UUID,但是UUID有一些缺點,首先他相對比較長,另外UUID一般是無序的。有些時 ...
使用UUID或者GUID產生的ID沒有規則
Snowflake演算法是Twitter的工程師為實現遞增而不重覆的ID實現的
概述
分散式系統中,有一些需要使用全局唯一ID的場景,這種時候為了防止ID衝突可以使用36位的UUID,但是UUID有一些缺點,首先他相對比較長,另外UUID一般是無序的。有些時候我們希望能使用一種簡單一些的ID,並且希望ID能夠按照時間有序生成。而twitter的snowflake解決了這種需求,最初Twitter把存儲系統從MySQL遷移到Cassandra,因為Cassandra沒有順序ID生成機制,所以開發了這樣一套全局唯一ID生成服務。
該項目地址為:https://github.com/twitter/snowflake是用Scala實現的。
python版詳見開源項目https://github.com/erans/pysnowflake。
結構
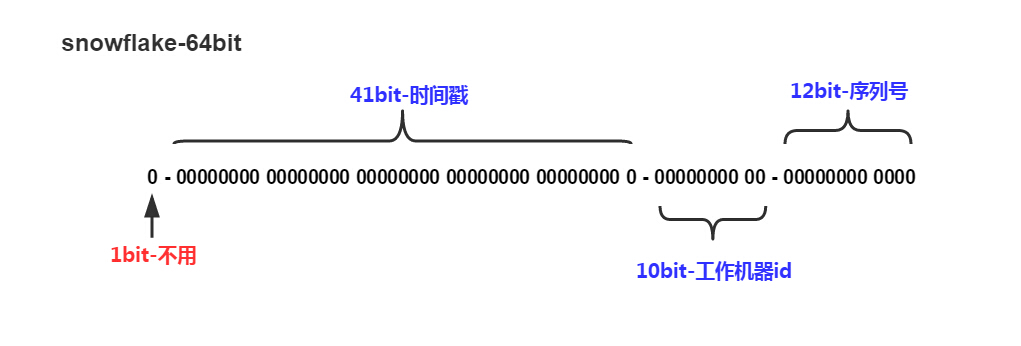
snowflake的結構如下(每部分用-分開):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位為未使用,接下來的41位為毫秒級時間(41位的長度可以使用69年),然後是5位datacenterId和5位workerId(10位的長度最多支持部署1024個節點) ,最後12位是毫秒內的計數(12位的計數順序號支持每個節點每毫秒產生4096個ID序號)
一共加起來剛好64位,為一個Long型。(轉換成字元串長度為18)
snowflake生成的ID整體上按照時間自增排序,並且整個分散式系統內不會產生ID碰撞(由datacenter和workerId作區分),並且效率較高。據說:snowflake每秒能夠產生26萬個ID。
從圖上看除了第一位不可用之外其它三組均可浮動站位,據說前41位就可以支撐到2082年,10位的可支持1023台機器,最後12位序列號可以在1毫秒內產生4095個自增的ID。
在多線程中使用要加鎖。
看懂代碼前 先來點電腦常識:<<左移 假如1<<2 :1左移2位=1*2^2=4(這裡^是多少次方的意思,和下麵的不同,哈別混淆。)
^異或 :true^true=false false^false=false true^false=true false^true=true 例子: 1001^0001=1000
負數的二進位:
第一步:絕對值化為你需要多少位表示的二進位第二步:各位取反,0變1,1變0
第三步:最後面加1 例子:-1的二進位→ 0001 取反→1110→最後面加1→1111
好了廢話不多說 直接代碼:
1 public class IdWorker 2 { 3 //機器ID 4 private static long workerId; 5 private static long twepoch = 687888001020L; //唯一時間,這是一個避免重覆的隨機量,自行設定不要大於當前時間戳 6 private static long sequence = 0L; 7 private static int workerIdBits = 4; //機器碼位元組數。4個位元組用來保存機器碼(定義為Long類型會出現,最大偏移64位,所以左移64位沒有意義) 8 public static long maxWorkerId = -1L ^ -1L << workerIdBits; //最大機器ID 9 private static int sequenceBits = 10; //計數器位元組數,10個位元組用來保存計數位 10 private static int workerIdShift = sequenceBits; //機器碼數據左移位數,就是後面計數器占用的位數 11 private static int timestampLeftShift = sequenceBits + workerIdBits; //時間戳左移動位數就是機器碼和計數器總位元組數 12 public static long sequenceMask = -1L ^ -1L << sequenceBits; //一微秒內可以產生計數,如果達到該值則等到下一微秒在進行生成 13 private long lastTimestamp = -1L; 14 15 /// <summary> 16 /// 機器碼 17 /// </summary> 18 /// <param name="workerId"></param> 19 public IdWorker(long workerId) 20 { 21 if (workerId > maxWorkerId || workerId < 0) 22 throw new Exception(string.Format("worker Id can't be greater than {0} or less than 0 ", workerId)); 23 IdWorker.workerId = workerId; 24 } 25 26 public long nextId() 27 { 28 lock (this) 29 { 30 long timestamp = timeGen(); 31 if (this.lastTimestamp == timestamp) 32 { //同一微秒中生成ID 33 IdWorker.sequence = (IdWorker.sequence + 1) & IdWorker.sequenceMask; //用&運算計算該微秒內產生的計數是否已經到達上限 34 if (IdWorker.sequence == 0) 35 { 36 //一微秒內產生的ID計數已達上限,等待下一微秒 37 timestamp = tillNextMillis(this.lastTimestamp); 38 } 39 } 40 else 41 { //不同微秒生成ID 42 IdWorker.sequence = 0; //計數清0 43 } 44 if (timestamp < lastTimestamp) 45 { //如果當前時間戳比上一次生成ID時時間戳還小,拋出異常,因為不能保證現在生成的ID之前沒有生成過 46 throw new Exception(string.Format("Clock moved backwards. Refusing to generate id for {0} milliseconds", 47 this.lastTimestamp - timestamp)); 48 } 49 this.lastTimestamp = timestamp; //把當前時間戳保存為最後生成ID的時間戳 50 long nextId = (timestamp - twepoch << timestampLeftShift) | IdWorker.workerId << IdWorker.workerIdShift | IdWorker.sequence; 51 return nextId; 52 } 53 } 54 55 /// <summary> 56 /// 獲取下一微秒時間戳 57 /// </summary> 58 /// <param name="lastTimestamp"></param> 59 /// <returns></returns> 60 private long tillNextMillis(long lastTimestamp) 61 { 62 long timestamp = timeGen(); 63 while (timestamp <= lastTimestamp) 64 { 65 timestamp = timeGen(); 66 } 67 return timestamp; 68 } 69 70 /// <summary> 71 /// 生成當前時間戳 72 /// </summary> 73 /// <returns></returns> 74 private long timeGen() 75 { 76 return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; 77 } 78 79 }
調用:
1 IdWorker idworker = new IdWorker(1); 2 for (int i = 0; i < 1000; i++) 3 { 4 Console.WriteLine(idworker.nextId()); 5 }
其他演算法:
方法一:UUID
UUID是通用唯一識別碼 (Universally Unique Identifier),在其他語言中也叫GUID,可以生成一個長度32位的全局唯一識別碼。
String uuid = UUID.randomUUID().toString()
結果示例:
046b6c7f-0b8a-43b9-b35d-6489e6daee91
為什麼無序的UUID會導致入庫性能變差呢?
這就涉及到 B+樹索引的分裂:
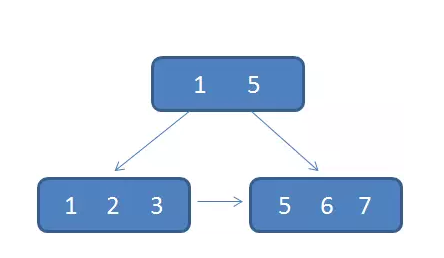
眾所周知,關係型資料庫的索引大都是B+樹的結構,拿ID欄位來舉例,索引樹的每一個節點都存儲著若幹個ID。
如果我們的ID按遞增的順序來插入,比如陸續插入8,9,10,新的ID都只會插入到最後一個節點當中。當最後一個節點滿了,會裂變出新的節點。這樣的插入是性能比較高的插入,因為這樣節點的分裂次數最少,而且充分利用了每一個節點的空間。
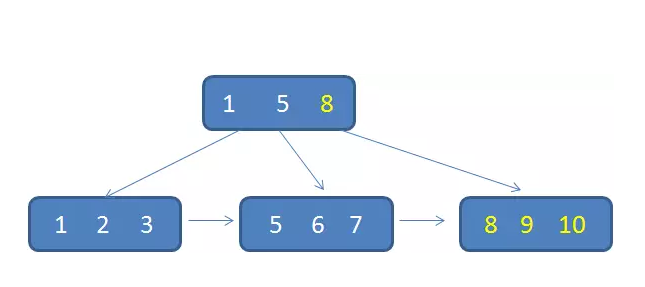
但是,如果我們的插入完全無序,不但會導致一些中間節點產生分裂,也會白白創造出很多不飽和的節點,這樣大大降低了資料庫插入的性能。
方法二:資料庫自增主鍵
假設名為table的表有如下結構:
id feild
35 a
每一次生成ID的時候,訪問資料庫,執行下麵的語句:
begin;
REPLACE INTO table ( feild ) VALUES ( 'a' );
SELECT LAST_INSERT_ID();
commit;
REPLACE INTO 的含義是插入一條記錄,如果表中唯一索引的值遇到衝突,則替換老數據。
這樣一來,每次都可以得到一個遞增的ID。
為了提高性能,在分散式系統中可以用DB proxy請求不同的分庫,每個分庫設置不同的初始值,步長和分庫數量相等:
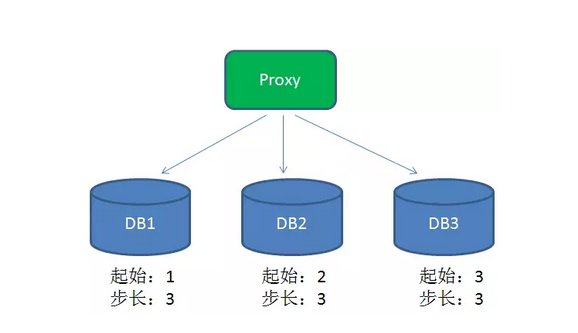
這樣一來,DB1生成的ID是1,4,7,10,13....,DB2生成的ID是2,5,8,11,14.....

