
北航OO(2020)第一單元博客作業 [TOC] 基於度量的程式結構分析 Homework 1 代碼度量 | Method | CONTROL | ev\(G\) | iv\(G\) | LOC | v\(G\) | | | | | | | | | "Expression\.Expression\( ...
目錄
北航OO(2020)第一單元博客作業
基於度量的程式結構分析
Homework 1
代碼度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 1 | 1 |
| "Expression.Expression(String)" | 7 | 1 | 8 | 38 | 10 |
| "Expression.computeDerivative()" | 0 | 1 | 1 | 5 | 1 |
| "Expression.toString()" | 1 | 1 | 2 | 7 | 2 |
| "Main.main(String[])" | 0 | 1 | 1 | 5 | 1 |
| "Polynomial.Polynomial()" | 0 | 1 | 1 | 3 | 1 |
| "Polynomial.addTerm(BigInteger,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Polynomial.computeDerivative()" | 3 | 3 | 2 | 12 | 3 |
| "Polynomial.termToString(Entry<BigInteger, BigInteger>)" | 6 | 2 | 7 | 34 | 7 |
| "Polynomial.toString()" | 3 | 2 | 3 | 16 | 4 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 9 | 12 | 14 | n/a | 0 |
| "Expression" | 1 | 16 | 54 | 3.00 | 12 |
| "Main" | 0 | 13 | 7 | 1.00 | 1 |
| "Polynomial" | 1 | 17 | 79 | 3.60 | 18 |
UML類圖
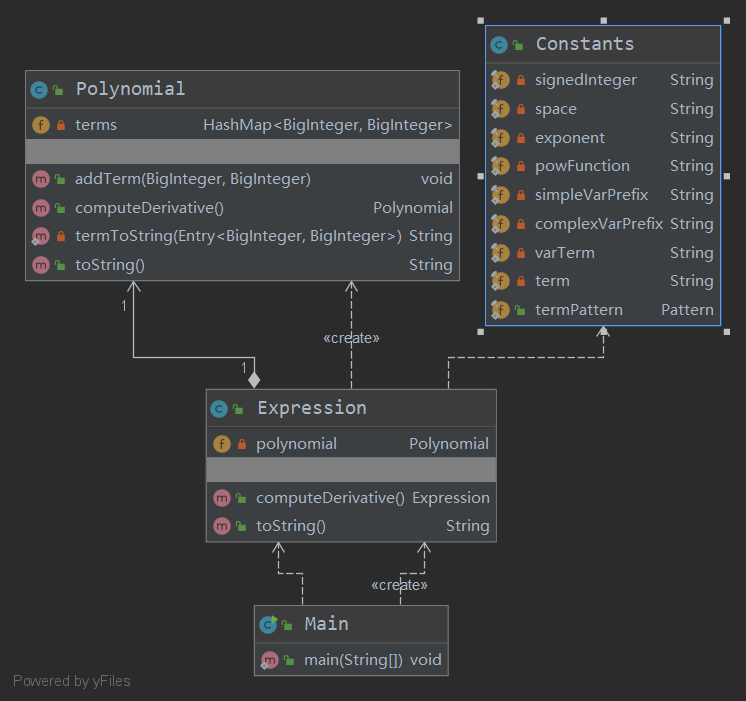
優缺點分析
本次作業要求較為簡單,因此我的架構較為清晰。方法的最大長度僅為38行,類的最大長度也只有79行,複雜度整體可控。
但是,我將解析輸入與Expression類的構造方法合併,增加了耦合度。從量化分析中也可看出,這一做法顯著增加了Expression類及其構造方法的複雜度。此外,我還錯誤地預判了未來的擴展方向,架構的可擴展性也出現了偏差。
Homework 2
代碼度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.addTerm(Term,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Expression.computeDerivative()" | 4 | 4 | 3 | 14 | 4 |
| "Expression.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Expression.getRandomTerm()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.isOneTerm()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.termEntryToString(Entry<Term, BigInteger>)" | 5 | 2 | 6 | 30 | 6 |
| "Expression.toString()" | 4 | 2 | 4 | 19 | 5 |
| "FactorType.FactorType(FunctionType,Expression)" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.deriveEmbedded()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.deriveType()" | 6 | 2 | 2 | 14 | 4 |
| "FactorType.equals(Object)" | 2 | 3 | 3 | 12 | 5 |
| "FactorType.getEmbeddedExpression()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.getFunctionType()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.toString()" | 8 | 8 | 2 | 25 | 8 |
| "Main.main(String[])" | 1 | 1 | 2 | 12 | 2 |
| "Pair.Pair(T1,T2)" | 0 | 1 | 1 | 4 | 1 |
| "Pair.getFirst()" | 0 | 1 | 1 | 3 | 1 |
| "Pair.getSecond()" | 0 | 1 | 1 | 3 | 1 |
| "Parser.parseExpression(String)" | 5 | 2 | 3 | 23 | 6 |
| "Parser.parseTerm(String)" | 6 | 4 | 6 | 29 | 8 |
| "Term.Term()" | 0 | 1 | 1 | 3 | 1 |
| "Term.addFactor(FactorType,BigInteger)" | 2 | 2 | 2 | 13 | 3 |
| "Term.computeDerivative()" | 6 | 1 | 9 | 36 | 9 |
| "Term.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Term.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Term.toString()" | 3 | 2 | 3 | 17 | 4 |
| "WrongFormatException.WrongFormatException(String)" | 0 | 1 | 1 | 3 | 1 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 21 | 12 | 34 | n/a | 0 |
| "Expression" | 1 | 21 | 123 | 2.78 | 25 |
| "FactorType" | 2 | 20 | 72 | 2.50 | 20 |
| "FunctionType" | 6 | 27 | 3 | n/a | 0 |
| "Main" | 0 | 13 | 14 | 1.00 | 1 |
| "Pair" | 2 | 15 | 14 | 1.00 | 3 |
| "Parser" | 0 | 14 | 54 | 6.50 | 13 |
| "Term" | 1 | 18 | 87 | 3.17 | 19 |
| "WrongFormatException" | 6 | 44 | 5 | 1.00 | 1 |
UML類圖
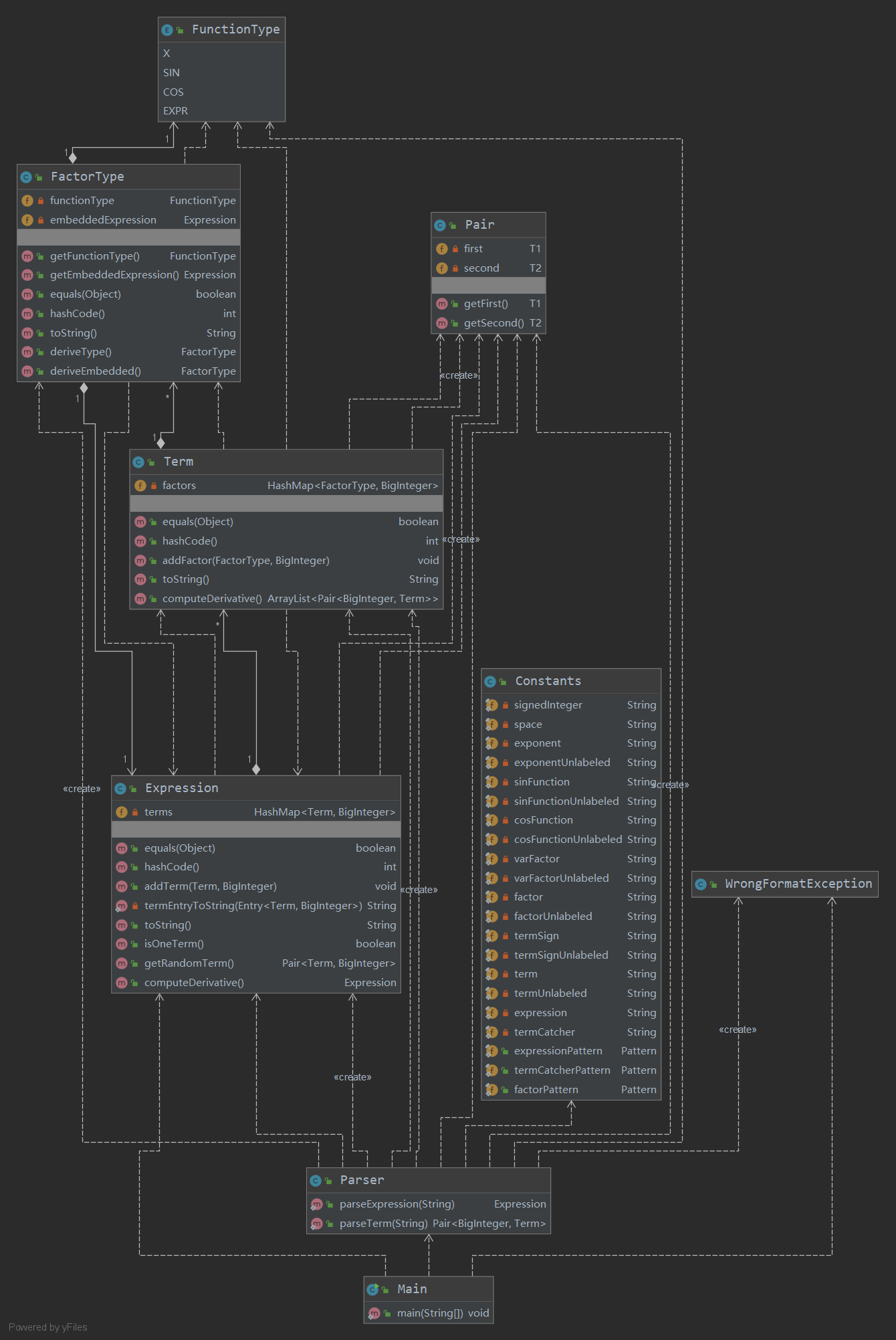
優缺點分析
在本次作業中,我按照求導規則進行建模,分加法、乘法以及將來可能出現的嵌套三級,分別由Expression、Term以及FactorType類進行管理。這些類分別實現了toString()方法以及求導方法。
本次作業複雜度依舊可控,但我對上次的架構進行了重構,併為下次作業留出了大量擴展空間,這使得程式的結構變得相對複雜很多。然而,由於我對下次作業的擴展方向有了比較正確的預判,我的第三次作業的整體架構幾乎沒有做出任何改動。這一點可以從UML類圖中看出,沒有增添新的類,各個類的屬性和方法也沒有大的變動。此外,從度量中也可以看出,方法的長度依舊可控,最大長度甚至低於第一次作業。
但一些方法,如Term.computeDerivative()方法的複雜度和耦合度都較高,它依賴於FactorType類中的每個具體類型執行不同的求導操作,這方面可以進一步改進,如讓FactorType類執行這些操作等。
Homework 3
代碼度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.addTerm(Term,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Expression.computeDerivative()" | 4 | 4 | 3 | 13 | 4 |
| "Expression.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Expression.getRandomTerm()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.isOneTerm()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.isSimpleFactor()" | 3 | 4 | 3 | 15 | 4 |
| "Expression.isZero()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.termEntryToString(Entry<Term, BigInteger>)" | 5 | 2 | 6 | 30 | 6 |
| "Expression.toString()" | 4 | 2 | 4 | 22 | 5 |
| "FactorType.FactorType(FunctionType,Expression)" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.deriveEmbedded()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.deriveType()" | 6 | 2 | 2 | 14 | 4 |
| "FactorType.equals(Object)" | 2 | 3 | 3 | 12 | 5 |
| "FactorType.getEmbeddedExpression()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.getFunctionType()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.toString()" | 9 | 9 | 5 | 30 | 10 |
| "Main.main(String[])" | 1 | 1 | 2 | 12 | 2 |
| "Pair.Pair(T1,T2)" | 0 | 1 | 1 | 4 | 1 |
| "Pair.getFirst()" | 0 | 1 | 1 | 3 | 1 |
| "Pair.getSecond()" | 0 | 1 | 1 | 3 | 1 |
| "Parser.parseExpression(String)" | 9 | 6 | 6 | 41 | 11 |
| "Parser.parseTerm(String)" | 13 | 8 | 10 | 56 | 14 |
| "Parser.preProcess(String)" | 7 | 4 | 7 | 25 | 9 |
| "Term.Term()" | 0 | 1 | 1 | 3 | 1 |
| "Term.addFactor(FactorType,BigInteger)" | 2 | 2 | 2 | 13 | 3 |
| "Term.computeDerivative()" | 7 | 1 | 9 | 38 | 9 |
| "Term.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Term.getFactors()" | 0 | 1 | 1 | 3 | 1 |
| "Term.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Term.isEmpty()" | 0 | 1 | 1 | 3 | 1 |
| "Term.isSimpleFactor()" | 4 | 5 | 2 | 14 | 5 |
| "Term.toString()" | 5 | 2 | 5 | 25 | 6 |
| "WrongFormatException.WrongFormatException(String)" | 0 | 1 | 1 | 3 | 1 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 22 | 12 | 36 | n/a | 0 |
| "Expression" | 1 | 23 | 122 | 2.73 | 30 |
| "FactorType" | 2 | 20 | 77 | 2.62 | 21 |
| "FunctionType" | 6 | 27 | 3 | n/a | 0 |
| "Main" | 0 | 13 | 14 | 1.00 | 1 |
| "Pair" | 2 | 15 | 14 | 1.00 | 3 |
| "Parser" | 0 | 15 | 124 | 10.67 | 32 |
| "Term" | 1 | 21 | 117 | 3.22 | 29 |
| "WrongFormatException" | 6 | 44 | 5 | 1.00 | 1 |
UML類圖
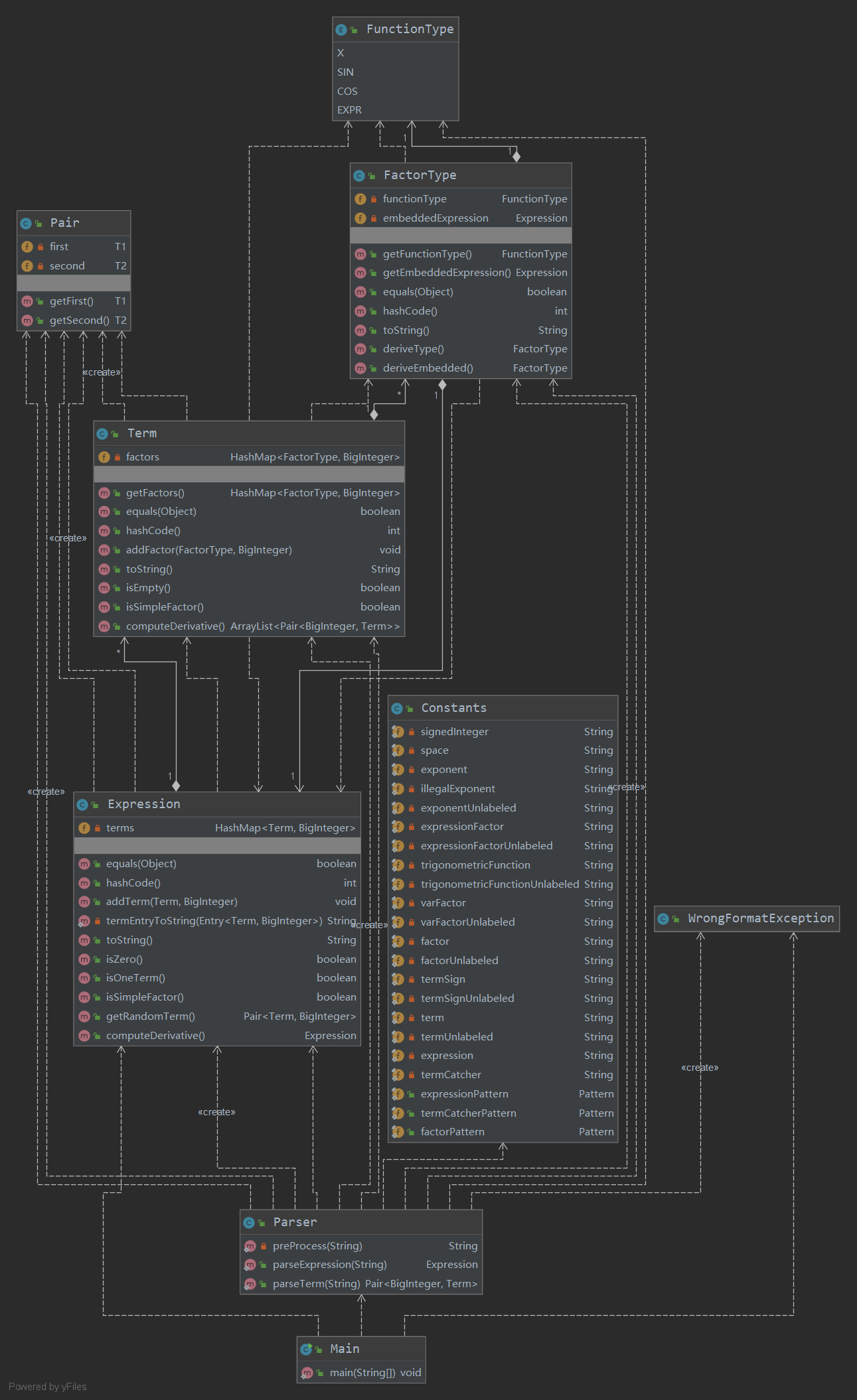
複雜度分析
本次作業的複雜度較前兩次有了躍升,主要是因為嵌套規則的出現,使得表達式出現了遞歸組合的可能。然而,得益於上次良好的架構設計,本次我只對Parser和Constants類做出了比較大的修改。
但是,從度量中可以看出,Parser.parseExpression(String)方法和Parser.parseTerm(String)方法已經變得十分複雜,還可進一步解耦,例如將針對不同因數的判斷從中移出,採用其他方法或機制完成。
Bug分析
本單元作業中,我由於對Wrong Format判斷不全,在Homework 3的強測中痛失兩點。不過,由於程式整體架構尚可,在互測中無任何bug被髮現。
Homework 3中的bug發生在Parser類中的parseExpression(String)方法中,由於我對於正則表達式的匹配機制理解不深,忽視了括弧中的通配符會將潛在的Wrong Format匹配其中導致整個表達式匹配成功的問題,最終導致了bug的出現。例如sin(x)+++x+cos(x),就會按照sin(.*)進行匹配,而不會失敗。
Hack策略分析
由於時間、精力和能力所限,本次的Hack策略僅僅局限在提交手動構造的測試用例以及提交曾經在自己的程式上測出問題的測試用例上,也並未仔細閱讀他人代碼。當然,效果也十分一般,每次平均只能Hack成功一兩個人。
對象創建模式應用分析
在進行表達式的解析時,可以利用工廠模式構建不同的因數。可以為X、SIN、COS、EXPR分別建立因數類,並用統一的因數介面進行管理,用統一的因數工廠進行構造。這樣將可以大大簡化Parser.parseTerm(String)等方法。
設計問題分析與心得體會
本次作業的設計中存在的問題主要有:
- 對於抽象層次與設計模式的運用不夠,主要依賴類的組合和條件判斷來解決問題;
- 一些類與方法之間的耦合度較高,修改困難;
- 一些方法過於冗長且內聚性不夠。
通過本單元的學習和作業練習,我初步瞭解了面向對象程式設計的一些基本的思想和方法,並迭代開發了一個最終代碼在500行量級的Java面向對象程式。通過3次的迭代開發,我充分認識到了良好的架構和可擴展性的重要性。在龐大的工程面前,規範化以及高內聚低耦合的設計對於迭代開發的順利進行至關重要。
此外,同學之間的討論與交流也對於我的開發有著極大的啟發和引領作用。尤其是討論區的一些帖子,能夠幫助我迅速找到架構設計的方向、明確處理的細節問題。


