
學習任何一門語言的第一步,首先要寫個'hello world',這算是程式員的一個傳統。但在寫之前,還有註意幾個問題。 首先,python是一門腳本語言,而腳本語言的特點就是:我們寫的代碼會先由解釋器進行編譯以後,再去執行。但是當我們的程式運行在操作系統之上時,系統並沒有那麼智能,能夠自動識別出我們 ...
學習任何一門語言的第一步,首先要寫個'hello world',這算是程式員的一個傳統。但在寫之前,還有註意幾個問題。
首先,python是一門腳本語言,而腳本語言的特點就是:我們寫的代碼會先由解釋器進行編譯以後,再去執行。但是當我們的程式運行在操作系統之上時,系統並沒有那麼智能,能夠自動識別出我們要用哪個解釋器去解釋我們的代碼(windows則通過尾碼名關聯執行程式,所以不用聲明也可以,但是我們的代碼更多在linux上運行,所以解釋器的聲明算是必須的),所以,我們必須要聲明我們的解釋器是什麼。
#! /usr/bin/python
在文件的第一行寫上這段代碼,當文件被執行的時候,系統會去 /usr/bin/python 中找到解釋器,然後用它來解釋我們的代碼。但是,正如我在第一篇介紹python安裝中提到的,系統自帶的python和我們源碼安裝的python的路徑是不同的,而我們並不能保證我們程式運行的系統中,python就裝在這裡。
所以,用下麵這種方法相容性更好:
#! /usr/bin/env python
如果有linux基礎的同學會知道 env 是linux中調用環境變數的,這段代碼的意思是去系統的環境變數中尋找python,找到了就用它來解釋代碼。這樣做能獲得更高的相容性,無論是什麼方法安裝的,只有在系統環境變數中,就都能找到。
這時,有些人就有疑問了,不是說#後面的都是註釋嗎,註釋是不被執行的,為什麼這句代碼有效果?
其實解釋器的聲明也算是註釋的一種,只不過它比較特殊,記住能這樣用就好,也不用太去深究,下麵的字元集聲明也是一樣的,反正特殊的就這兩個,也沒什麼記不住的。
有了以上基礎,就可以開始寫'hello world'了,但作為一名中國的程式員,我還想寫‘你好,世界’怎麼辦?
如果是在3.x中,那就可以直接開始了。但如果是2.x的話,那還需要進行字元集的聲明。
關於字元集的概念可以是查看一下其他相關文章,作為一名以懶惰催生生產力的程式員,還是不造重覆的輪子的好。下麵是一些總結:
1.python2.x預設使用的是acsii碼,這個編碼是不支持中文的
2.為了支持世界上的所有文字,而誕生了Unicode,而為了壓縮Unicode在顯示英文時占用的空間,又誕生了utf-8,這也是我們常用的字元集。
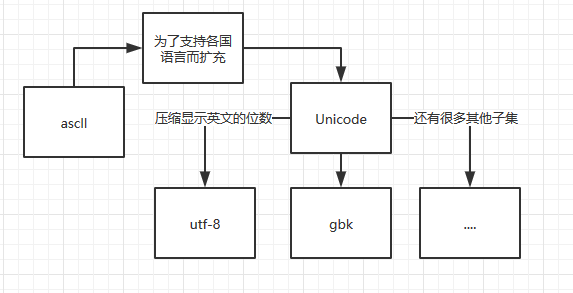
其實使用utf-8就已經總夠了,我這裡單獨列出gbk是因為很多人在windows的cmd裡面使用中文時,就算聲明瞭字元集,但還是顯示亂碼。
此時,要註意一個問題,雖然你是用了utf-8,但cmd的交互視窗卻不是以utf-8去顯示,詳情看圖:
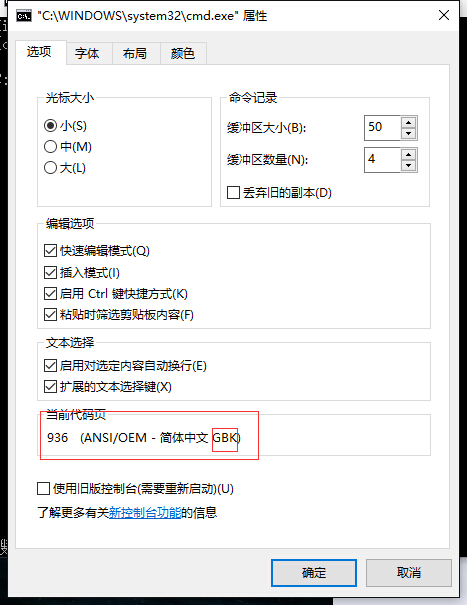
其使用的是gbk,而你輸出的字元卻用的是utf-8,用gbk去解讀utf-8當然會出現亂碼。所以很多時候要註意一下顯示終端用的是什麼編碼。
這個時候要顯示中文,修改一下顯示的字元就好,如果修改不了,那就下載個IDE就好,同樣也有註意IDE的顯示編碼問題,用什麼IDE看個人習慣,逐個嘗試就好,我用的是pycharm,具體不再多說。
講完為何要聲明字元集,接下來講如何聲明,其實和聲明解釋器類似,可以在文件的第二行寫:
#-*- coding: UTF-8 -*-
下麵這種寫法也行:
# coding: UTF-8
小寫的utf也行,還有一些其他寫法,例如把:換成=號的,個人習慣用第一種寫法。
講完瞭解釋器聲明和字元集聲明以後,我們得出了python的同樣起手式:
#! /usr/bin/env pyhton # -*- coding:utf-8 -*-
好,學會了起手式後,就可以開始寫‘hello world’了。
#! /usr/bin/env pyhton # -*- coding:utf-8 -*- print "hello world"
print "你好,世界"
解釋:print是python的一個關鍵字,其作用是將其後面的東西顯示到終端,專業術語稱為“列印”,可以列印各種數據類型,例如字元串,數字,元祖,字典等,具體這些是什麼以後會講。
而我們在第一篇中的3.x新特性中提到,print這個關鍵字,被print()方法取代了,所以3.x中要這樣寫:
#! /usr/bin/env pyhton # -*- coding:utf-8 -*- print ("hello world")
print ("你好,世界")
而在2.7中,上面兩種方法都是支持的,這也是2.7被稱為過度版本的原因之一。
好了,第一個python程式就寫完了,就是這麼簡單!嗯……好吧,還算簡單吧。

