
程式員在轉型架構師的過程中需要建立流程化、結構化、系統化的思維方式,而性能調優是非常難得的契機,它既給了我們壓力,也給了我們動力,跨越它就是突破自己的過程。Y 維度,就是從業務 HTTP 請求的橫向處理流程來看,HTTP 請求會穿越網路、電腦、應用容器(Tomcat)、Spring、ORM(Hib... ...
性能調優系列前序文章索引:
- 程式員必須掌握的性能調優:老兵哥結合個人經歷解釋了程式員往架構師方向發展時為什麼要跨越性能調優這一關,以及介紹了從 X、Y、Z 三個維度優化性能的思路。
- 從 X 維度優化系統的性能:老兵哥分享了從 X 維度優化系統性能的思路,包括讓客戶端分計算存儲任務、優化交互設計等,主要是作為引子拓寬我們性能調優的思路。
- 應用容器 Tomcat 性能調優:老兵哥介紹了從 Y 維度通過優化應用容器 Tomcat 來優化系統性能的方法。
- 開發框架 Spring 性能調優:老兵哥介紹了從 Y 維度通過優化開發框架 Spring 來優化系統性能的方法。
今天老兵哥將介紹通過優化對象關係映射 ORM 框架(Hibernate)等來優化系統性能的方法。
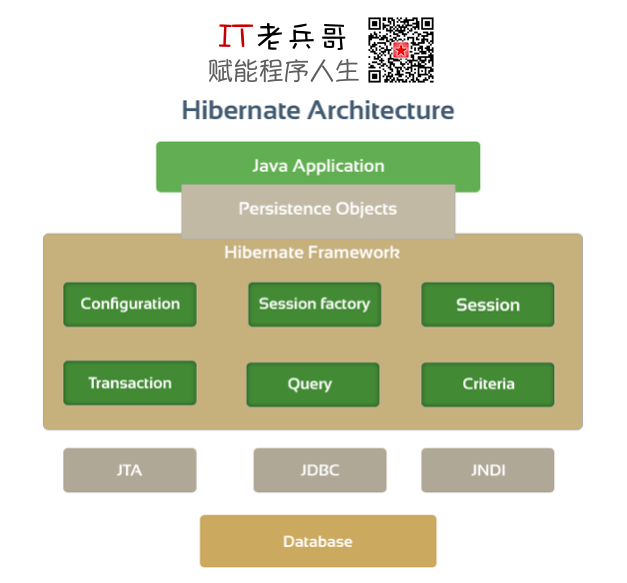
4. ORM 框架 Hibernate
對象-關係映射 ORM(Object/Relation Mapping),是伴隨著面向對象軟體開發方法的發展而產生的。面向對象的開發方法是當今企業級應用開發環境中的主流方法,關係資料庫是企業級應用環境中數據永久存儲的主流數據存儲系統。對象和關係是業務實體數據的兩種表現形式,業務實體在記憶體中表現為對象,在資料庫中表現為關係數據。記憶體中的對象之間存在關聯和繼承關係,而在資料庫中,關係數據無法直接表達多對多關聯和繼承關係。
對象-關係映射 ORM 系統通常以中間件的形式存在,藉助描述對象到關係資料庫數據的映射元數據,將記憶體中的對象自動持久化到關係資料庫中,其本質就是將數據從一種形式轉換到另外一種形式。這個轉換過程需要額外的開銷,自然也就存在許多優化的機會,接下來我們一起來看看如何提升 ORM 框架 Hibernate 的性能。
4.1 批量處理
應用或者 ORM 框架每次執行 SQL 語句都需要跟資料庫建立連接,每次建立連接都需要額外開銷。如果某個事務內部有迴圈多次操作資料庫的場景,那麼將這些操作彙集在一起批量執行,這樣就可以降低損耗,具體如下:
- 批量插入
使用這種方法時,首先在 Hibernate 的配置文件 hibernate.cfg.xml 中設置批量尺寸屬性 hibernate.jdbc.batch_size ,且最好關閉Hibernate的二級緩存以提高效率。
<hibernate-configuration> <session-factory> <property name="hibernate.jdbc.batch_size">50</property> //設置尺寸 <property name="hibernate.cache.use_second_level_cache">false</property> //關閉緩存 <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
for (int i = 0; i < 50; i++) {
User user = new User();
user.setPassword(i);
session.save(user);
if (i%50 == 0) {
// 以 50 為一個批次往資料庫提交,此值應與配置的批量尺寸一致
session.flush();
// 清空緩存區,釋放記憶體供下批數據使用
session.clear();
}
}
ts.commit();
HibernateSessionFactory.closeSession();
}
}
- 批量更新
為了使 Hibernate 的 HQL 直接支持 update 的批量更新語法,我們需要在 Hibernate 的配置文件 hibernate.cfg.xml 中設置 HQL/SQL 查詢翻譯器屬性 "hibernate.query.factory_class":
<hibernate-configuration> ...... <property name="hibernate.query.factory_class"> org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory </property> <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
Query query = session.createQuery("update User set password='123456'");
query.executeUpdate();
ts.commit();
HibernateSessionFactory.closeSession();
}
}
- 批量刪除
為了使 Hibernate 的 HQL 直接支持 delete 的批量更新語法,我們需要在 Hibernate 的配置文件 hibernate.cfg.xml 中設置 HQL/SQL 查詢翻譯器屬性 "hibernate.query.factory_class":
<hibernate-configuration> ...... <property name="hibernate.query.factory_class"> org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory </property> <mapping resource="com/itlaobingge/po/User.hbm.xml" /> </session-factory> </hibernate-configuration>
public class HibernateDemo {
public static void main(String args[]) {
Session session = HibernateSessionFactory.getSession();
Transaction ts = session.beginTransaction();
Query query=session.createQuery("delete User where id < 123");
query.executeUpdate();
ts.commit();
HibernateSessionFactory.closeSession();
}
}
4.2 抓取策略
抓取策略是指當應用程式需要在對象關聯關係間進行導航時,Hibernate 如何獲取關聯對象的策略,常見的抓取策略有如下幾種:
- 鏈接抓取(Join Fetching):通過在 select 語句中使用 out join 來獲取對象的關聯實例或者關聯集合。
- 查詢抓取(Select Fetching):發送另外一條 select 語句抓取當前對象的關聯實體或者關聯集合。除非我們顯示地指定 lazy=”false” 禁止延遲抓取,否則只有當我們真正訪問了關聯關係時才會執行第二條 select 語句。
- 子查詢抓取:另外發送一條 select 語句抓取在前面查詢到或抓取到的所有實體對象的關聯集合。除非你顯式的指定 lazy="false" 禁止延遲抓取,否則只有當你真正訪問關聯關係的時候,才會執行第二條 select 語句。
- 批量抓取(Batch fetching):對查詢抓取的優化方案,通過指定一個主鍵或外鍵列表,Hibernate 使用單條 select 語句獲取一批對象實例或集合。
Hibernate 會區分下列幾種情況:
- 立即抓取(Immediate fetching):當宿主被載入時,關聯、集合或屬性被立即抓取。
- 延遲集合抓取(Lazy collectionfetching):直到應用程式對集合進行了一次操作時,集合才被抓取。
- Extra-lazy 集合抓取(Extra-lazy collection fetching):對集合類中的每個元素而言,都是直到需要時才去訪問資料庫。除非絕對必要,Hibernate 不會試圖去把整個集合都抓取到記憶體里來。
- 代理抓取(Proxy fetching):對返回單值的關聯而言,當其某個方法被調用,而非對其關鍵字進行 get 操作時才抓取。
- 非代理抓取(No-proxy fetching):對返回單值的關聯而言,當實例變數被訪問的時候進行抓取。與上面的代理抓取相比,這種方法沒有那麼延遲得厲害,就算只訪問標識符,也會導致關聯抓取,但是更加透明,因為對應用程式來說,不再看到 proxy。這種方法需要在編譯期間進行位元組碼增強操作,因此很少需要用到。
- 屬性延遲載入(Lazy-attribute fetching):對屬性或返回單值的關聯而言,當其實例變數被訪問的時候進行抓取。需要編譯期位元組碼強化,因此這一方法很少是必要的。
定製合理的抓取策略對系統的性能提升有很大的幫助。查詢抓取在 N+1 查詢的情況下是極其脆弱的,因此我們可能會要求在映射文件中定義連接抓取(fetch=”join”),但是在映射文件中定義的抓取策略將會產生以下影響:通過 get() 或者 load() 方法獲取數據,只有在關聯之間進行導航時,才會隱式的取得數據。
條件查詢,使用了 subselect 抓取的 HQL 查詢,不管使用哪種抓取策略,定義為非延時的類圖會保證裝載入記憶體,這就意味著一條 HQL 查詢後緊跟著一系列的查詢。通常我們並不使用映射文件進行抓取策略的定製,更多是保持其預設值然後在待定事務中適用 HQL 的左連接對其進行重載。
Hibernate 推薦的做法也是最佳實踐:把所有對象關聯的抓取都設為 lazy,然後在特定事務中進行重載。這種考慮是基於對象之間的關聯關係錯綜複雜,有時候哪怕我們只是一個簡單的查詢,也會導致很多關聯對象被裝載出來,所以在 Hibernate 中,所有對象關聯都是 lazy 的。
在 Hibernate 中實施關聯抓取,我們可以定義每次抓取數據的數量,批量地將數據載入記憶體,減少與資料庫交互的次數,在應用程式中可以定義預設的關聯抓取數量。Hibernate 提供了兩種批量抓取方案:
- 類級別的批量查詢,如果一個 Session 中需要載入 30 個 User 實例,在 User 中擁有一個類 Class 成員變數 class。如果 lazy=“true”,我們需要遍歷整個 user 集合,每一個 user 都需要 getClass(),在預設情況下要執行 30 次查詢得到 Class 對象。因此,可以通過在映射文件的 Class 屬性設置 batch-size,這樣Hibernate 只需要執行兩次查詢即可:
<class name=”Class” batch-size=”15”>...</class>
- 集合級別的批量查詢,如果我們需要遍歷 30 個 Class 對象下所擁有 User 對象列表,在 Session 中需要載入 30 個 Class 對象,遍歷 Class 集合將會引起 30 次查詢,每次查詢都會調用 getUsers()。如果在 Class 的映射定義中,允許對 User 進行批量抓取,則 Hibernate 就會預先載入整個集合。
<set name=”users” batch-size=”15”>...</set>
4.3 二級緩存
緩存可以降低應用程式對物理數據源訪問的頻次,從而提高應用程式的運行性能。緩存對 Hibernate 來說也是很重要的,它使用瞭如下圖所示的多級緩存方案:
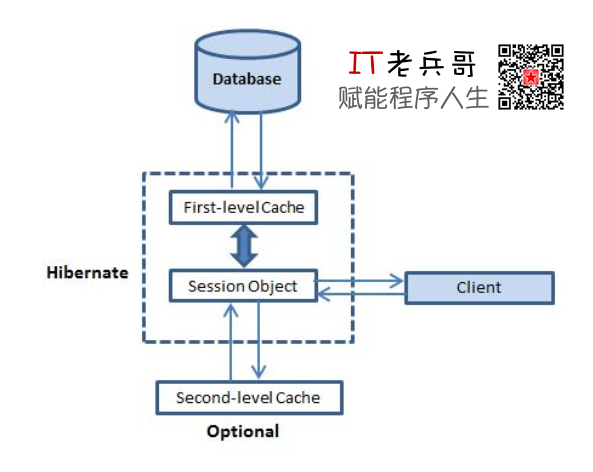
- 一級緩存,第一級緩存是 Session 緩存,屬於強制性緩存,所有請求都必須通過它。Session 對象在它自己的權利之下,在將它提交給資料庫之前保存一個對象。如果你對一個對象發出多個更新,Hibernate 會嘗試儘可能長地延遲更新來減少發出的 SQL 更新語句的數目。如果你關閉 Session,所有緩存的對象丟失,或是存留,或是在資料庫中被更新。
- 二級緩存,第二級緩存是可選擇的,第一級緩存在任何想要在第二級緩存中找到一個對象前被詢問。第二級緩存可以在每一個類和每一個集合的基礎上被安裝,並且它主要負責跨會話緩存對象。任何第三方緩存都可以和 Hibernate 合作,只要它實現 org.hibernate.cache.CacheProvider 介面。
Hibernate 的二級緩存通過兩個步驟設置:
- 第一,你必須決定好使用哪個併發策略(Transactional、Read-write、Nonstrict-read-write、Read-only);
- 第二,你使用第三方緩存提供者來配置緩存到期時間和物理緩存屬性。併發策略,負責保存緩存中的數據項和從緩存中檢索它們,如何選擇併發策略及配置可以查資料。
4.4 查詢緩存
查詢結果集也可以被緩存,只有在經常使用同樣的參數進行查詢時,查詢緩存才會有些用處。如果要使用查詢緩存,你必須打開它:hibernate.cache.use_query_cache,該設置將會創建兩個緩存區域:一個用於保存查詢結果集(org.hibernate.cache.StandardQueryCache);另一個則用於保存最近查詢的一系列表的時間戳(org.hibernate.cache.UpdateTimestampsCache)。
在查詢緩存中,它並不緩存結果集中所包含的實體的確切狀態,它只緩存這些實體的標識符屬性的值、以及各值類型的結果,所以查詢緩存通常會和二級緩存一起使用。絕大多數的查詢並不能從查詢緩存中受益,所以 Hibernate 預設是不進行查詢緩存的。如若需要進行緩存,請調用 Query.setCacheable(true) 方法。這個調用會讓查詢在執行過程中時先從緩存中查找結果,並將自己的結果集放到緩存中去。
關註「 IT老兵哥 」,賦能程式人生!堅持原創不易,請小伙伴們不吝點個「 贊 」哦!推薦軟技能文章,請點擊鏈接:程式員,怎樣打造個人影響力?

近期熱評系列《 程式員必須懂的架構師入門課 》:
- 架構到底是什麼,你知道嗎? (閱讀人數:1218)
- 架構都有哪些,我該怎麼選? (閱讀人數:891)
- 架構師都乾什麼,你知道嗎? (閱讀人數:1192)
- 練就哪些技能才勝任架構師? (閱讀人數:1157)
- 怎樣才能搞定上下游的客戶? (閱讀人數:495)
- 如何從開發崗轉型做架構師? (閱讀人數:1309)
- 程式員必須懂的架構入門課 (閱讀人數:611)


