
為了瞭解,上來先看幾篇中文博客進行簡單瞭解: 如何理解Nvidia英偉達的Multi-GPU多卡通信框架NCCL? 使用NCCL進行NVIDIA GPU卡之間的通信 nvidia-nccl 學習筆記 https://developer.nvidia.com/nccl (官方網站) https://g ...
為了瞭解,上來先看幾篇中文博客進行簡單瞭解:
- 如何理解Nvidia英偉達的Multi-GPU多卡通信框架NCCL?(較為優秀的文章)
- 使用NCCL進行NVIDIA GPU卡之間的通信 (GPU卡通信模式測試)
- nvidia-nccl 學習筆記 (主要是一些介面介紹)
- https://developer.nvidia.com/nccl (官方網站)
- https://github.com/NVIDIA/nccl (官方倉庫)
- https://www.cnblogs.com/xuyaowen/p/heterogeneous-system-architecture.html GPU 相關架構
- https://www.nvidia.cn/data-center/nvlink/ (NVLink)
內容摘錄:
- 通信性能(應該主要側重延遲)是pcie switch > 同 root complex (一個cpu接幾個卡) > 不同root complex(跨cpu 走qpi)。ib的gpu direct rdma比跨cpu要快,所以甚至單機八卡要按cpu分成兩組,每組一個switch,下麵四個卡,一個ib,不通過cpu的qpi通信,而是通過ib通信。- 摘自評論
- 對於多個GPU卡之間相互通信,硬體層面上的實現有Nvlink、PCIe switch(不經過CPU)、Infiniband、以及PCIe Host Bridge(通常就是藉助CPU進行交換)這4種方式。而NCCL是Nvidia在軟體層面對這些通信方式的封裝。
保持更新,更多內容,請參考cnblogs.com/xuyaowen;
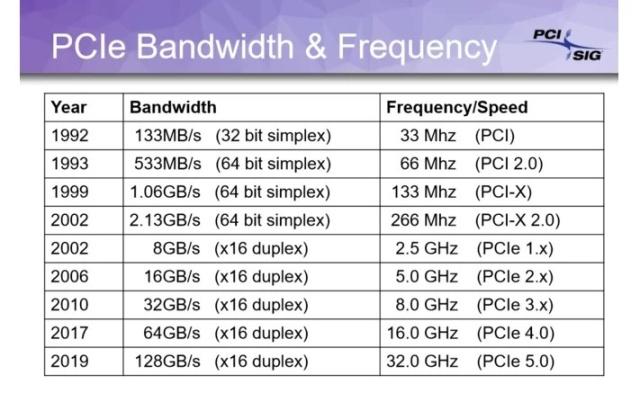
z390 晶元組資料:
https://ark.intel.com/content/www/cn/zh/ark/products/133293/intel-z390-chipset.html
P2P 顯卡通信性能測試:
cuda/samples/1_Utilities/p2pBandwidthLatencyTest


