
騰訊搶金達人活動中使用了node同構直出渲染方案,那麼其中遇到了什麼問題,最終帶來了什麼收益呢? ...
我們的業務在展開的過程中,前端渲染的模式主要經歷了三個階段:服務端渲染、前端渲染和目前的同構直出渲染方案。
服務端渲染的主要特點是前後端沒有分離,前端寫完頁面樣式和結構後,再將頁面交給後端套數據,最後再一起聯調。同時前端的發佈也依賴於後端的同學;但是優點也很明顯:頁面渲染速度快,同時 SEO 效果好。
為瞭解決前後端沒有分離的問題,後來就出現了前端渲染的這種模式,路由選擇和頁面渲染,全部放在前端進行。前後端通過介面進行交互,各端可以更加專註自己的業務,發佈時也是獨立發佈。但缺點是頁面渲染慢,嚴重依賴 js 文件的載入速度,當 js 文件載入失敗或者 CDN 出現波動時,頁面會直接掛掉。我們之前大部分的業務都是前端渲染的模式,有部分的用戶反饋頁面 loading 時間長,頁面渲染速度慢,尤其是在老舊的 Android 機型上這個問題更加地明顯。
node同構直出渲染方案可以避免服務端渲染和前端渲染存在的缺點,同時前後端都是用 js 寫的,能夠實現數據、組件、工具方法等能實現前後端的共用。
1. 效果
首先來看下統計數據的結果,可以看到從前端渲染模式切換到 node 同構直出渲染模式後,整頁的載入耗時從 3500ms 降低到了 2100 毫秒左右,整體的載入速度提高了將近 40%。

但這個數據也不是最終的數據,因為當時要趕著上線的時間,很多東西還沒來及優化,在後續的優化完成後,可以看到整體的的載入耗時又下降到了 1600ms 左右,再次下降了 500ms 左右。

從 3500ms 降低到 1600ms,整整加快了 1900ms 的載入速度,整體提升了 54%。優化的手段在稍後也會講解到。
2. 遇到的挑戰
在進行同構直出渲染方案,也對目前存在的技術,並結合自身的技術棧,對整體的架構進行梳理。
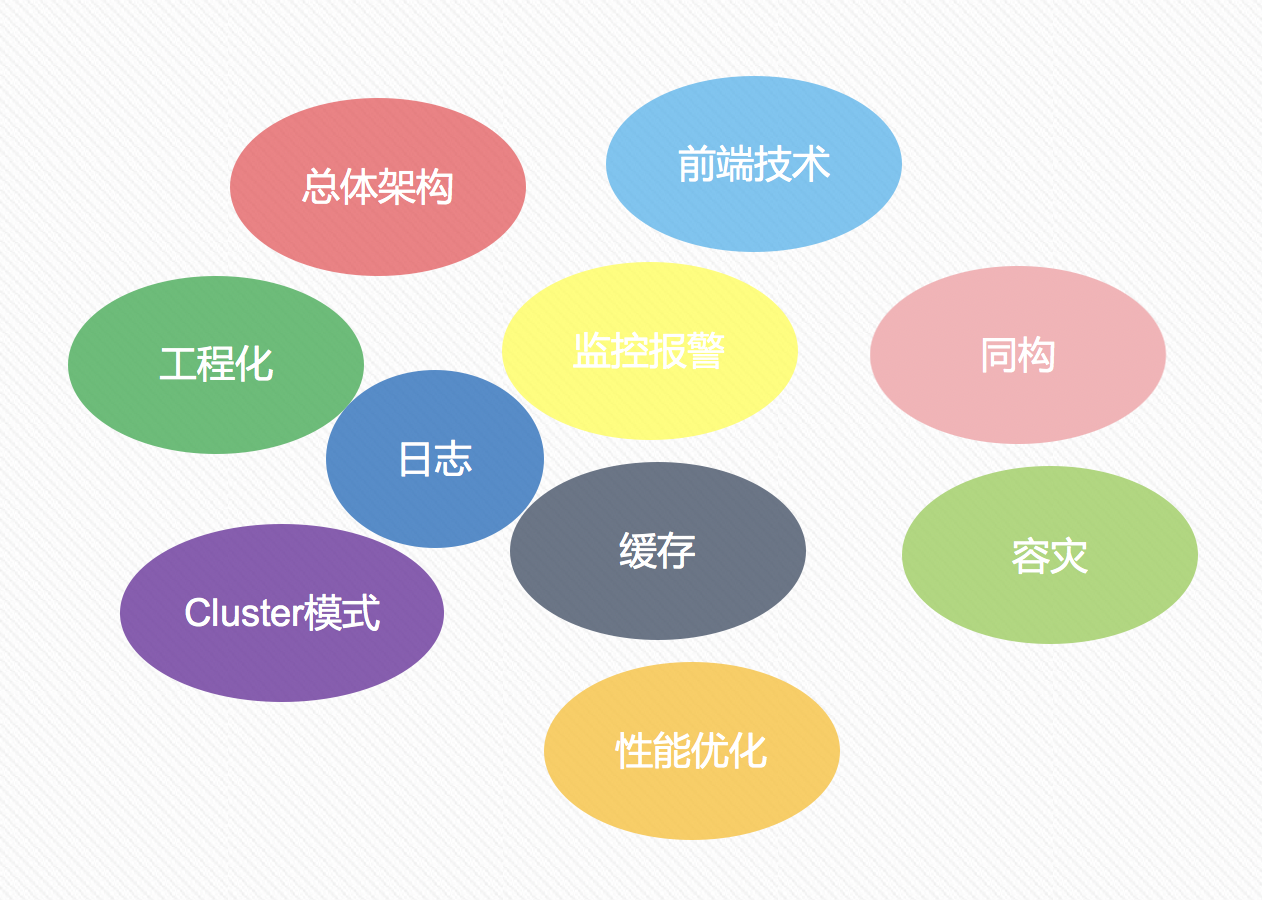
梳理出接下來存在的重點和難點:
- 如何保持數據、路由、狀態、基礎組件的同構共用?如何區分客戶端和服務端?
- 如何進行數據請求,是否存在跨域的請求?在服務端、瀏覽器端和新聞客戶端內都是怎樣進行數據請求的,各自都有什麼特點,是否可以封裝一下?
- 工程化:如何區分開發環境、測試環境、預發佈環境和正式環境?單元測試如何執行?是否可以自動化發佈?
- 項目的頁面有什麼特點,頁面、介面數據、組件等是否可以緩存?如何進行緩存?是否存在個性化的數據?
- 如何記錄日誌,上報項目的性能數據,如請求量、前端頁面載入的整頁耗時、錯誤率、後端耗時等數據?如何在 node 服務出現異常時(如負載過高、記憶體泄露)進行告警?
- 如何進行容災處理,當出現異常情況時如何降級,並告知開發者快速的修複!
- node 是單線程運行,如何充分利用多核?
- 性能優化:預載入、圖片懶載入、使用 service worker、延遲載入 js、IntersectionObserver 延遲載入組件等
針對我們項目初期的規劃中,可能出現的問題一一進行解決,最終我們的項目也能夠實現的差不離了,某些比較大的模塊我可能需要單獨拿出來寫一篇文章進行總結。
3. 功能實現
3.1 前後端的同構
使用 node 服務端同構指出渲染方案,最主要的是數據等結構能夠實現前後端的同構共用。
同構方面主要是實現:數據同構、狀態同構、組件同構和路由同構等。
數據同構:對於相同的虛擬 DOM 元素,在服務端使用 renderToNodeStream 把渲染結果以“流“的形式塞給 response 對象,這樣就不用等到 html 都渲染出來才能給瀏覽器端返回結果,“流”的作用就是有多少內容給多少內容,能夠進一步改進了“第一次有意義的渲染時間”。同時,在瀏覽器端,使用 hydrate 把虛擬 dom 渲染為真實的 DOM 元素。若瀏覽器端對比服務端渲染的組件數,若發生不一致的情況時,不再直接丟掉全部的內容,而是進行局部的渲染。因此在使用服務端的渲染過程中,要保證前後端組件數據的一致性。這裡將服務端請求的數據,插入到 js 的全局變數中,隨著 html 一起渲染到瀏覽器端(脫水);這是在瀏覽器端,就可以拿到脫水的數據來初始化組件,添加交互等等(註水)。
狀態同構方面:我們這裡使用mobx為每個用戶創建一個全局的狀態管理,這樣數據可以進行統一的管理,而不用組件之間衣岑層傳遞。
組件同構:編寫的基礎組件或其他組件可以在服務端和客戶端都能使用,同時使用typeof window==='undefined'或process.browser來判斷當前是客戶端還是服務端,以此來屏蔽某端不支持的操作。
路由統一:客戶端使用BrowserRouter,服務端使用StaticRouter。
在同構的過程中,最開始時還沒太理解這個概念,在編碼階段就遇到了這樣的問題。例如我們有個小輪播,這個輪播是將數組打亂隨機展示的,我將從服務端請求到的數據打亂後渲染到頁面上,結果調試視窗中輸出一條錯誤信息(我們這裡用個樣例數據來代替):
const list = ['勛章', '答題卡', '達人榜', '紅包', '公告'];在render()中隨機輸出:
{
list.sort(() => (Math.random() < 0.5 ? 1 : -1)).map(item => (
<p key={item}>{item}</p>
));
}結果在控制台輸出了警告信息,同時最終展示出來的信息並不是打亂排序:
Warning: Text content did not match. Server: "紅包" Client: "答題卡"
輸出的警告信息是因為客戶端發現當前與服務端的數據不一致後,客戶端重新進行了渲染,並給出了警告信息。我們在渲染的時候才把數組打亂順序,服務端是按照打亂順序後的數據渲染的,但是傳遞給客戶端的數據還是原始數據,造成了前後端數據不一致的問題。
如果真的想要隨機排序,可以在獲取服務端的數據後,直接先排好序,然後再渲染,這樣服務端和客戶端的數據就會保持一致。在 nextjs 中就是getInitialProps中操作。
3.2 如何進行數據請求
基於我們項目主要是在新聞客戶端內運行的特點,我們要考慮多種數據請求的方式:服務端、瀏覽器端、新聞客戶端內,是否跨域等特點,然後形成一個完整的統一的多終端數據請求體系。
- 服務端:使用 http 模塊或者 axios 等第三方組件發起 http 請求,並透傳 ua 和 cookie 給介面;
- 新聞客戶端:使用新聞客戶端提供的 jsapi 發起介面請求,註意 iOS 和 Android 不同 APP 中請求方式的差異;
- 瀏覽器端跨域請求:創建一個 script 標簽發起介面請求,並設置超時時間;
- 瀏覽器端同域請求:優先使用
fetch,然後使用XMLHttpRequest發起介面請求。
這裡將多終端的數據進行封裝,對外提供統一而穩定的調用方式,業務層無需關心當前的請求從哪個終端發起。
// 發起介面請求
// @params {string} url 請求的地址
// @params {object} opts 請求的參數
const request = (url: string, opts: any): Promise<any> => {};同時,我們也在請求介面的方法中添加上監控處理,如監控介面的請求量、耗時、失敗率等信息,做到詳細的信息記錄,快速地進行定位和相應。
3.3 工程化
工程化是一個很大的概念,我們這裡僅僅從幾個小點上進行說明。
我們的項目目前都是部署在 skte 上,通過設置不同的環境變數來區分當前是測試環境、預發佈環境和正式環境。
同時,因為我們的業務主要是在新聞客戶端內訪問的特點,很多的單元測試無法完全覆蓋,只能進行部分的單元測試,確保基礎功能的正常運作。
現在接入了完全自動化的 CI(持續集成)/CD(持續部署),基於 git 分支的方式進行發佈構建,當開發者完成編碼工作後,推送到 test/pre/master 分支後,進行單元測試的校驗,通過後就會自動集成和部署。
3.4 緩存
緩存的優點自不必多說:
- 加快了瀏覽器載入網頁的速度;
- 減少了冗餘的數據傳輸,節省網路流量和帶寬;
- 減少伺服器的負擔,大大提高了網站的性能。
但同時增加緩存,整體項目的複雜度也會增加,我們需要評估下項目是否適合緩存、適用於哪種緩存機制、緩存失效時如何處理。
緩存的機制主要有:
- 瀏覽器強緩存或 nginx 緩存:緩存固定的時長,例如 30ms 的時間,在這 30ms 的時間內讀取緩存中的數據,這種緩存的缺點是數據無法及時更新,必須等到緩存時間到後才能更新;
- 狀態緩存或全局緩存:這適用於路由之間多次切換或者緩存用戶個性化的數據,只在單次訪問的過程中有效;
- 記憶體緩存:將緩存存儲於記憶體中,無需額外的 I/O 開銷,讀寫速度快;但缺點是數據容易失效,一旦程式出現異常時緩存直接丟失,同時記憶體緩存無法達到進程之間的共用。這裡當我們使用瀏覽器的協商緩存時,即根據生成的內容產生
ETag值,若 etag 值相同則使用緩存,否則請求伺服器的數據,這就會造成不同進程之間緩存的數據可能不一樣,etag 多次失效的問題。記憶體緩存尤其要註意記憶體泄露的問題 - 分散式緩存:使用獨立的第三方緩存,如 Redis 或 Memcached,好處時多個進程之間可以共用,同時減少項目本身對緩存淘汰演算法的處理
不同的項目或者不同的頁面採用不同的緩存策略。
- 不常更新數據的頁面如首頁、排行榜頁面等,可以使用瀏覽器強緩存或者介面緩存;
- 用戶頭像、昵稱、個性化等數據使用狀態管理;
- 介面數據可以使用第三方緩存
在對介面的數據緩存時,尤其要註意的是介面正常返回時,才緩存數據,否則交給業務層處理。
同時,在使用緩存的過程中,還註意緩存失效的問題。
| 緩存失效 | 含義 | 解決方案 |
|---|---|---|
| 緩存雪崩 | 所有的緩存同一時間失效 | 設置隨機的緩存時間 |
| 緩存穿透 | 緩存中不存在,資料庫中也不存在 | 緩存中設置一個空值,且緩存時間較短 |
| 隨機 key 請求 | 惡意地使用隨機 key 請求,導致無法命中緩存 | 布隆過濾器,未在過濾器中的數據直接攔截 |
| 為緩存的 key | 緩存中沒有但資料庫中有 | 請求成功後,緩存數據,並將數據返回 |
3.5 日誌記錄
詳細的日誌記錄能夠讓我們很方便地瞭解項目效果和排查問題。前後端的表現形式不一樣,我們也區分前後端進行日誌的上報。
前端主要上報頁面的性能信息,服務端主要上報程式的異常、CPU 和記憶體的使用狀況等。
在前端方面,我們可以使用window.performance經過簡單的計算得到一些網頁的性能數據:
- 首次載入耗時: domLoading - fetchStart;
- 整頁耗時: loadEventEnd - fetchStart;
- 錯誤率: 錯誤日誌量/請求量;
- DNS 耗時: domainLookupEnd - domainLookupStart;
- TCP 耗時: connectEnd - connectStart;
- 後端耗時: responseStart - requestStart;
- html 耗時: responseEnd - responseStart;
- DOM 耗時: domContentLoadedEventEnd - responseEnd;
同時我們也需要捕獲前端代碼中的一些報錯:
- 全局捕獲,error:
window.addEventListener(
'error',
(message, filename, lineNo, colNo, stackError) => {
console.log(message); // 錯誤信息的描述
console.log(filename); // 錯誤所在的文件
console.log(lineNo); // 錯誤所在的行號
console.log(colNo); // 錯誤所在的列號
console.log(stackError); // 錯誤的堆棧信息
}
);- 全局捕獲,unhandledrejection:
當 Promise 被 reject 且沒有 reject 處理器的時候,會觸發 unhandledrejection 事件;這可能發生在 window 下,但也可能發生在 Worker 中。 這對於調試回退錯誤處理非常有用。
window.addEventListener('unhandledrejection', event => {
console.log(event);
});- 介面非同步請求時
這裡可以對fetch和XMLHttpRequest進行重新的封裝,既不影響正常的業務邏輯,也可以進行錯誤上報。
XMLHttpRequest 的封裝:
const xmlhttp = window.XMLHttpRequest;
const _oldSend = xmlhttp.prototype.send;
xmlhttp.prototype.send = function() {
if (this['addEventListener']) {
this['addEventListener']('error', _handleEvent);
this['addEventListener']('load', _handleEvent);
this['addEventListener']('abort', _handleEvent);
} else {
var _oldStateChange = this['onreadystatechange'];
this['onreadystatechange'] = function(event) {
if (this.readyState === 4) {
_handleEvent(event);
}
_oldStateChange && _oldStateChange.apply(this, arguments);
};
}
return _oldSend.apply(this, arguments);
};fetch 的封裝:
const oldFetch = window.fetch;
window.fetch = function() {
return _oldFetch
.apply(this, arguments)
.then(res => {
if (!res.ok) {
// True if status is HTTP 2xx
// 上報錯誤
}
return res;
})
.catch(error => {
// 上報錯誤
throw error;
});
};服務端的日誌根據嚴重程度,主要可以分為以下的幾個類別:
- error: 錯誤,未預料到的問題;
- warning: 警告,出現了在預期內的異常,但是項目可以正常運行,整體可控;
- info: 常規,正常的信息記錄;
- silly: 不明原因造成的;
我們針對可能出現的異常程度進行不同類別(level)的上報,這裡我們採用了兩種記錄策略,分別使用網路日誌boss和本地日誌winston分別進行記錄。boss 日誌里記錄較為簡單的信息,方便通過瀏覽器進行快速地排查;winston 記錄詳細的本地日誌,當通過簡單的日誌信息無法定位時,則使用更為詳細的本地日誌進行排查。
使用winston進行服務端日誌的上報,按照日期進行分類,上報的主要信息有:當前時間、伺服器、進程 ID、消息、堆棧追蹤等:
// https://github.com/winstonjs/winston
logger = createLogger({
level: 'info',
format: combine(label({ label: 'right meow!' }), timestamp(), myFormat), // winston.format.json(),
defaultMeta: { service: 'user-service' },
transports: [
new transports.File({
filename: `/data/log/question/answer.error.${date.getFullYear()}-${date.getMonth() +
1}-${date.getDate()}.log`,
level: 'error'
})
]
});同時 nodejs 服務本身的監控機制也充分利用上,例如包括 http 狀態碼,記憶體占用(process.memoryUsage)等。
在日誌的統計過程中,加入告警機制,當告警數量或者數值超過一定的範圍,則向開發者的微信和郵箱發出告警信息和設備。例如其中的一條告警規則是:當頁面的載入時間小於 10ms 或者超過 6000ms 則發出告警信息,小於 10ms 時說明頁面掛掉了,大於 6000ms 說明伺服器可能出現異常,導致資源載入時間過長。
同時也要及時地關註用戶反饋平臺,若產生了一個用戶的反饋,必然是有更多的用戶存在這樣的問題。
3.6 容災處理
日誌記錄和告警等都是事故發生後才產生的行為,我們應當如何保證在我們看到日誌信息並修複問題之前的這段時間里,服務至少能夠還是是正常運行的,而不是白屏或者 5xx 等信息。這裡我們要做的就是線上服務的容災處理。
| 可能存在的問題 | 容災措施 |
|---|---|
| 後端介面異常 | 使用預設數據,並及時告知介面方 |
| 瞬時流量高、CPU 負載率過高 | 自動擴容,並告警 |
| node 服務異常,如 4xx,5xx 等 | nginx 自動將服務轉向靜態頁面,並告警轉發的次數 |
| 靜態資源導致的樣式異常 | 將首屏或者首頁的樣式嵌入到頁面中 |
容災處理與日誌信息的記錄,保障我們項目能夠正常地線上上運行。
3.7 cluster 模塊
nodejs 作為一種單線程、單進程運行的程式,如果只是簡單的使用的話(node app.js),存在著如下一些問題:
- 無法充分利用多核 cpu 機器的性能,
- 服務不穩定,一個未處理的異常都會導致整個程式退出
- 沒有成熟的日誌管理方案、
- 沒有服務/進程監控機制
所幸,nodejs 為我們提供了cluster模塊,什麼是cluster:
簡單的說,
- 在伺服器上同時啟動多個進程。
- 每個進程里都跑的是同一份源代碼(好比把以前一個進程的工作分給多個進程去做)。
- 更神奇的是,這些進程可以同時監聽一個埠(Cluster 實現原理)。
其中:
- 負責啟動其他進程的叫做 Master 進程,他好比是個『包工頭』,不做具體的工作,只負責啟動其他進程。
- 其他被啟動的叫 Worker 進程,顧名思義就是幹活的『工人』。它們接收請求,對外提供服務。
- Worker 進程的數量一般根據伺服器的 CPU 核數來定,這樣就可以完美利用多核資源。
cluster 模塊可以創建共用伺服器埠的子進程。這裡舉一個著名的官方案例:
const cluster = require('cluster');
const http = require('http');
const os = require('os');
if (cluster.isMaster) {
// 當前為主進程
console.log(`主進程 ${process.pid} 正在運行`);
// 啟動子進程
for (let i = 0, len = os.cpus().length; i < len; i++) {
cluster.fork();
}
cluster.on('exit', worker => {
console.log(`子進程 ${worker.process.pid} 已退出`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`子進程 ${process.pid} 已啟動`);
}當有進程退出時,則會觸發exit事件,例如我們 kill 掉 69030 的進程時:
> kill -9 69030
子進程 69030 已退出我們嘗試 kill 掉某個進程,發現子進程是不會自動重新創建的,這裡我可以修改下exit事件,當觸發這個事件後重新創建一個子進程:
cluster.on('exit', worker => {
console.log(`子進程 ${worker.process.pid} 已退出`);
// log日誌記錄
cluster.fork();
});主進程與子進程之間的通信:每個進程之間是相互獨立的,可是每個進程都可以與主進程進行通信。這樣就能把很多需要每個子進程都需要處理的問題,放到主進程里處理,例如日誌記錄、緩存等。我們在 3.4 緩存小節中也有講“記憶體緩存無法達到進程之間的共用”,可是我們可以把緩存提高到主進程中進行緩存。
if (cluster.isMaster) {
Object.values(cluster.workers).forEach(worker => {
// 向所有的進程都發佈一條消息
worker.send({ timestamp: Date.now() });
// 接收當前worker發送的消息
worker.on('message', msg => {
console.log(
`主進程接收到 ${worker.process.pid} 的消息:` +
JSON.stringify(msg)
);
});
});
} else {
process.on('message', msg => {
console.log(`子進程 ${process.pid} 獲取信息:${JSON.stringify(msg)}`);
process.send({
timestamp: msg.timestamp,
random: Math.random()
});
});
}不過若線上生產環境使用的話,我們需要給這套代碼添加很多的邏輯。這裡可以使用pm2來維護我們的 node 項目,同時 pm2 也能啟用 cluster 模式。
pm2 的官網是http://pm2.keymetrics.io,github 是https://github.com/Unitech/pm2。主要特點有:
- 原生的集群化支持(使用 Node cluster 集群模塊)
- 記錄應用重啟的次數和時間
- 後臺 daemon 模式運行
- 0 秒停機重載,非常適合程式升級
- 停止不穩定的進程(避免無限迴圈)
- 控制台監控
- 實時集中 log 處理
- 強健的 API,包含遠程式控制制和實時的介面 API ( Nodejs 模塊,允許和 PM2 進程管理器交互 )
- 退出時自動殺死進程
- 內置支持開機啟動(支持眾多 linux 發行版和 macos)
nodejs 服務的工作都可以托管給 pm2 處理。
pm2 以當前最大的 CPU 數量啟動 cluster 模式:
pm2 start server.js -i max不過我們的項目使用配置文件來啟動的,ecosystem.config.js:
module.exports = {
apps: [
{
name: 'question',
script: 'server.js',
instances: 'max',
exec_mode: 'cluster',
autorestart: true,
watch: false,
max_memory_restart: '1G',
env_test: {
NEXT_APP_ENV: 'testing'
},
env_pre: {
NEXT_APP_ENV: 'pre'
},
env: {
NEXT_APP_ENV: 'production'
}
}
]
};然後啟動即可:
pm2 start ecosystem.config.js關於使用 node 來編寫 cluster 模式,還是用 pm2 來啟動 cluster 模式,還是要看項目的需要。使用 node 編寫時,自己可以控制各個進程之間的通信,讓每個進程做自己的事情;而 pm2 來啟動的話,在整體健壯性上更好一些。
3.8 性能優化
我們應當首先保證首頁和首屏的載入,一個是首屏需要的樣式直接嵌入到頁面中載入,再一個是首屏和次屏的數據分開載入。我們在首頁的數據主要是瀑布流的方式載入,而瀑布流是需要 js 計算的,因此這裡我們先載入幾條數據,保證首屏是有數據的,然後接下來的數據使用 js 計算應當放在哪個位置。
再一個是使用 service worker 來本地緩存 css 和 js 資源,更具體的使用,可以訪問service worker 在新聞紅包活動中的應用。
這裡我們使用 IntersectionObserver 封裝了通用的組件懶載入方案,因為在使用 scroll 事件中,我們可能還需要手動節流和防抖動,同時,因為圖片載入的快慢,導致需要多次獲取元素的 offsetTop 值。而 IntersectionObserver 就能完美地避免這些問題,同時,我們也能看到,這一屬性在高版本瀏覽器中也得到了支持,在低版本瀏覽器中,我可以使用 polyfill 的方式進行相容處理處理;
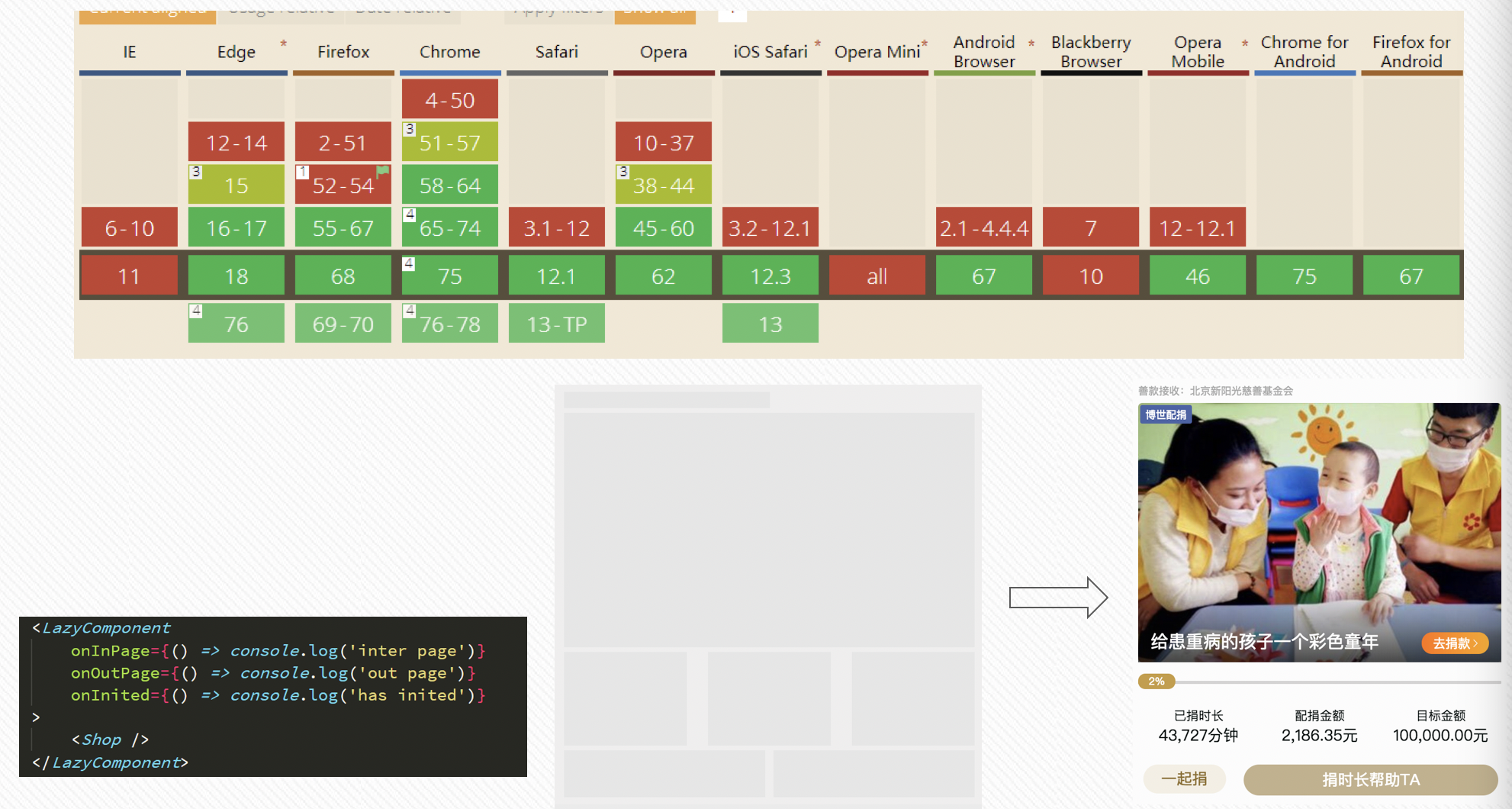
我將這個功能封裝為一個組件,對外提供幾個監聽方法,將需要懶載入的組件或者資源作為子組件,進行包裹,同時,我們這裡也建議建議使用者,使用預設的骨架屏撐起元素未渲染時的頁面。因為在直接使用懶載入渲染時,假如不使用骨架屏的話,用戶是先看到白屏,然後突然渲染內容,頁面給用戶一種強烈抖動的感覺。真實組件在最後真正展示出來時,需要一定的時間和空間,時間是從資源載入到渲染完畢需要時間;而空間指的是頁面佈局中需要給真實組件留出一定的問題,一個是為了避免頁面,再一個使用骨架屏後:
- 提升用戶的感知體驗
- 保證切換的一致性
- 提供可見性觀察的目標對象,為執行懶載入的組件保證可見性的區域
這裡實現的通用懶載入組件,對外提供了幾個回調方法:onInPage, onOutPage, onInited 等。
這個通用的組件懶載入方案可以使用在如下的場景下:
- 懶載入的粒度可大可小,大到 1 個組件或者幾個組件,小到一個圖片即可;
- 頁面模塊曝光率的數據上報,這樣可以計算模塊從曝光到參與的一個漏斗數據;
- 長列表中的無限滾動:我們可以監聽頁面底部的一個透明元素,當這個透明元素即將可見時,載入並渲染下一頁的數據。
當然,長列表無限滾動的優先,不僅限於使用可見性代替滾動事件,也還有其他的優化手段。
4. 總結
雖然啰里啰嗦了一大堆,但也這是我們同構直出渲染方案的開始,我們還有很長的路要走。應用型技術的難點不是在剋服技術問題,而是在於能夠不斷的結合自身的產品體驗,發現其中存在的體驗問題,不斷使用更好的技術方案去優化用戶的體驗,為整個產品發展添磚加瓦。

蚊子的前端博客鏈接: https://www.xiabingbao.com 。
歡迎關註我的微信公眾號: wenzichel


