
前言 當我們在Redis資料庫中set一個KV的時候,這個KV保存在哪裡?如果我們get的時候,又從哪裡get出來。時間複雜度,空間複雜的等等,怎麼優化等等一系列問題。 伺服器中的資料庫 Redis伺服器將所有資料庫信息都保存在redis.h##redisService結構體中。代碼如下: 列了幾個 ...
前言
當我們在Redis資料庫中set一個KV的時候,這個KV保存在哪裡?如果我們get的時候,又從哪裡get出來。時間複雜度,空間複雜的等等,怎麼優化等等一系列問題。
伺服器中的資料庫
Redis伺服器將所有資料庫信息都保存在redis.h##redisService結構體中。代碼如下:
1 struct redisServer { 2 3 // ... 4 5 /* General */ 6 7 // 配置文件的絕對路徑 8 char *configfile; /* Absolute config file path, or NULL */ 9 10 // 資料庫 11 redisDb *db; 12 13 // 是否設置了密碼 14 char *requirepass; /* Pass for AUTH command, or NULL */ 15 16 // PID 文件 17 char *pidfile; /* PID file path */ 18 19 // TCP 監聽埠 20 int port; /* TCP listening port */ 21 22 // ... 23 24 }
列了幾個,我認為比較重要的。其中最重要的,肯定是redisDb *db; 這個數據結構保存了我們所有的數據。
Redis 是一個鍵值對(key-value pair)資料庫伺服器, 伺服器中的每個資料庫都由一個 redis.h/redisDb 結構表示, 其中, redisDb 結構的 dict 字典保存了資料庫中的所有鍵值對, 我們將這個字典稱為鍵空間(key space)。代碼如下:
/* Redis database representation. There are multiple databases identified * by integers from 0 (the default database) up to the max configured * database. The database number is the 'id' field in the structure. */ typedef struct redisDb { // 資料庫鍵空間,保存著資料庫中的所有鍵值對 dict *dict; /* The keyspace for this DB */ // 鍵的過期時間,字典的鍵為鍵,字典的值為過期事件 UNIX 時間戳 dict *expires; /* Timeout of keys with a timeout set */ // 正處於阻塞狀態的鍵 dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */ // 可以解除阻塞的鍵 dict *ready_keys; /* Blocked keys that received a PUSH */ // 正在被 WATCH 命令監視的鍵 dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */ // 資料庫號碼 int id; /* Database ID */ // 資料庫的鍵的平均 TTL ,統計信息 long long avg_ttl; /* Average TTL, just for stats */ } redisDb;
其中最重要的就是 dict *dict; 他是一個字典,不太瞭解的小伙伴,可以看我前一篇的文章(https://www.cnblogs.com/wenbochang/p/11673590.html),對redis的字典有詳細的介紹。
這個dict存儲了我們真正的數據。
鍵空間和用戶所見的資料庫是直接對應的:
- 鍵空間的鍵也就是資料庫的鍵, 每個鍵都是一個字元串對象。
- 鍵空間的值也就是資料庫的值, 每個值可以是字元串對象、列表對象、哈希表對象、集合對象和有序集合對象在內的任意一種 Redis 對象。
因為資料庫的鍵空間是一個字典, 所以所有針對資料庫的操作 —— 比如添加一個鍵值對到資料庫, 或者從資料庫中刪除一個鍵值對, 又或者在資料庫中獲取某個鍵值對, 等等, 實際上都是通過對鍵空間字典進行操作來實現的。那麼複雜度顯而易見基本就是O(1)級別了,這也是redis為什麼能這麼快的一個重要原因。
對鍵取值
對一個資料庫鍵進行取值, 實際上就是在鍵空間中取出鍵所對應的值對象。代碼如下:
1 /* 2 * 返回字典中包含鍵 key 的節點 3 * 4 * 找到返回節點,找不到返回 NULL 5 * 6 * T = O(1) 7 */ 8 dictEntry *dictFind(dict *d, const void *key) 9 { 10 dictEntry *he; 11 unsigned int h, idx, table; 12 13 // 字典(的哈希表)為空 14 if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */ 15 16 // 如果條件允許的話,進行單步 rehash 17 if (dictIsRehashing(d)) _dictRehashStep(d); 18 19 // 計算鍵的哈希值 20 h = dictHashKey(d, key); 21 // 在字典的哈希表中查找這個鍵 22 // T = O(1) 23 for (table = 0; table <= 1; table++) { 24 25 // 計算索引值 26 idx = h & d->ht[table].sizemask; 27 28 // 遍歷給定索引上的鏈表的所有節點,查找 key 29 he = d->ht[table].table[idx]; 30 // T = O(1) 31 while(he) { 32 33 if (dictCompareKeys(d, key, he->key)) 34 return he; 35 36 he = he->next; 37 } 38 39 // 如果程式遍歷完 0 號哈希表,仍然沒找到指定的鍵的節點 40 // 那麼程式會檢查字典是否在進行 rehash , 41 // 然後才決定是直接返回 NULL ,還是繼續查找 1 號哈希表 42 if (!dictIsRehashing(d)) return NULL; 43 } 44 45 // 進行到這裡時,說明兩個哈希表都沒找到 46 return NULL; 47 }
看代碼其實是很簡單的。
- 首先判斷字典是否為空,如果為空,沒有繼續下去的必要了,直接return null
- 第二步,如果在進行rehash,則先進行漸進式rehash。(不懂的,翻我上一篇博文)
- 第三步,計算key的hash值。
- 第四步,查找ht[0],ht[1]兩張table表。其中如果是鏈表,則while迴圈查找即可。
- 找到返回,沒找到返回null。非常的簡單清晰的邏輯。
- 大致如下圖:
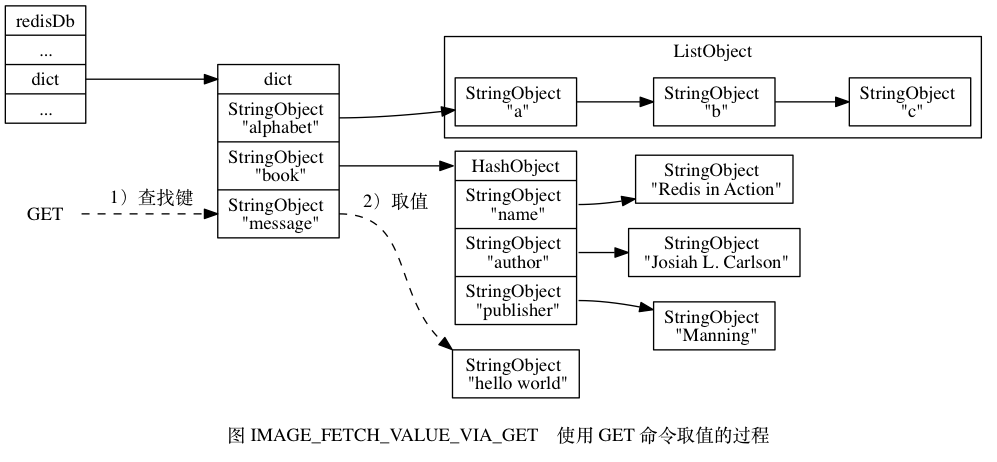
對鍵增加,刪除,更新類似於查找。我就不一一列出源碼了。
後言
當使用 Redis 命令對資料庫進行讀寫時, 伺服器不僅會對鍵空間執行指定的讀寫操作, 還會執行一些額外的維護操作, 其中包括:
- 在讀取一個鍵之後(讀操作和寫操作都要對鍵進行讀取), 伺服器會根據鍵是否存在, 以此來更新伺服器的鍵空間命中(hit)次數或鍵空間不命中(miss)次數, 這兩個值可以在 INFO stats 命令的
keyspace_hits屬性和keyspace_misses屬性中查看。
- 在讀取一個鍵之後, 伺服器會更新鍵的 LRU (最後一次使用)時間, 這個值可以用於計算鍵的閑置時間, 使用命令 OBJECT idletime <key> 命令可以查看鍵
key的閑置時間。
- 如果伺服器在讀取一個鍵時, 發現該鍵已經過期, 那麼伺服器會先刪除這個過期鍵, 然後才執行餘下的其他操作。
- 如果有客戶端使用 WATCH 命令監視了某個鍵, 那麼伺服器在對被監視的鍵進行修改之後, 會將這個鍵標記為臟(dirty), 從而讓事務程式註意到這個鍵已經被修改過。
- 伺服器每次修改一個鍵之後, 都會對臟(dirty)鍵計數器的值增一, 這個計數器會觸發伺服器的持久化以及複製操作執行。


