
需求 例如一張A表(id, userid, info);其中id為自增長主鍵。存在userid重覆記錄;並一直有新數據增加,現需要根據userid去重並實時插入表B。 用SQL語法來解釋: 其中需要改寫的語句是 -- 在表B插入百萬條記錄insert into B select level, dbm ...
需求
例如一張A表(id, userid, info);其中id為自增長主鍵。存在userid重覆記錄;並一直有新數據增加,現需要根據userid去重並實時插入表B。
用SQL語法來解釋:
-- 獲取表B中記錄最大id select max(id) from B -- 根據上面獲取的id;提取最新的A表記錄;根據userid去重;並插入中間表TMP_B; INSERT INTO TMP_B SELECT id, userid, info FROM (select id, userid, info, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY id) RN FROM A WHERE id > ?) WHERE RN = 1; -- 把上面獲取的記錄;不存在則插入表B insert into B select id, userid, info from TMP_B where userid not in (select userid from B); -- 或者用not exists insert into B select id, userid, info from TMP_B tb where not exists (select 1 from B b where b.userid = tb.userid);
其中需要改寫的語句是
select id, userid, info from TMP_B where userid not in (select userid from B);
-- 插入實驗數據
-- 在表B插入百萬條記錄
insert into B select level, dbms_random.string('x',8), 'lottu'||level from dual connect by level <= 1000000;
-- 在表TMP_B插入十萬條記錄
insert into TMP_B select level, dbms_random.string('x',8), 'lottu'||level from dual connect by level <= 100000;
通過執行計劃;會發現not in/ not exists 效率相差不大。
insert into B select id, userid, info from TMP_B tb where not exists (select 1 from B b where b.userid = tb.userid); 100000 rows created. Elapsed: 00:00:00.52 Execution Plan ---------------------------------------------------------- Plan hash value: 3462170537 ------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)|Time | ------------------------------------------------------------------------------------------ | 0 | INSERT STATEMENT | | 115K| 4389K| | 2994 (1)|00:00:36 | | 1 | LOAD TABLE CONVENTIONAL | B | | | | | | |* 2 | HASH JOIN ANTI | | 115K| 4389K| 4960K| 2994 (1)|00:00:36 | | 3 | TABLE ACCESS FULL | TMP_B | 115K| 3601K| | 137 (1)|00:00:02 | | 4 | TABLE ACCESS FULL | B | 1375K| 9403K| | 1372 (1)|00:00:17 | ----------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("B"."USERID"="TB"."USERID") Note ----- - dynamic sampling used for this statement (level=2) Statistics ---------------------------------------------------------- 0 recursive calls 3221 db block gets 6320 consistent gets 35 physical reads 3649980 redo size 845 bytes sent via SQL*Net to client 866 bytes received via SQL*Net from client 3 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 100000 rows processed
替換1: 通過merge into改寫語句
merge into B b using TMP_B tb on (tb.userid = b.userid) WHEN NOT MATCHED THEN INSERT (b.id, b.userid, b.info) values (tb.id, tb.userid, tb.info);
通過執行計劃;該SQL會占用記憶體用於排序。效率會有大大的提升。 特別是在B數據量很大的情況。優勢更明顯。
Elapsed: 00:00:00.18 Execution Plan ---------------------------------------------------------- Plan hash value: 2722554344 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time| -------------------------------------------------------------------------------------- | 0 | MERGE STATEMENT | | 115K| 7203K| | 5298 (1)| 00:01:04 | | 1 | MERGE | B | | | | || | 2 | VIEW | | | | | || |* 3 | HASH JOIN OUTER | | 115K| 8553K| 4960K| 5298 (1)| 00:01:04 | | 4 | TABLE ACCESS FULL| TMP_B | 115K| 3601K| | 137 (1)| 00:00:02 | | 5 | TABLE ACCESS FULL| B | 1336K| 56M| | 1373 (1)| 00:00:17 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("TB"."USERID"="B"."USERID"(+)) Note ----- - dynamic sampling used for this statement (level=2) Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 5496 consistent gets 0 physical reads 0 redo size 844 bytes sent via SQL*Net to client 896 bytes received via SQL*Net from client 3 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 0 rows processed
替換2: 通過kettle工具,設置轉換;通過shell命令;用cron或者其他調度系統調用。該操作相對用戶是透明的;至於效率方面有待驗證。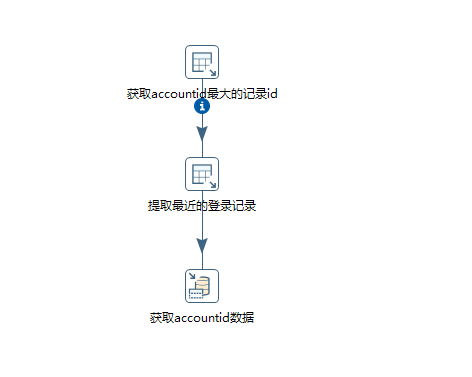
看到此處的朋友,若有更好的方法;歡迎在下評論;一起討論。
最後該需求若在PostgreSQL中;有更簡潔的的寫法.簡單粗暴。
INSERT INTO B SELECT * FROM A on conflict (userid) do nothing;

