
一直以為很瞭解sqlserver的加鎖過程,在分析一些特殊情況下的死鎖之後,尤其是併發單表操作發生的死鎖,對於加解鎖的過程,有了一些重新的認識,之前的知識還是有一些盲區在裡面的。delete加鎖與解鎖步驟是怎麼樣的?什麼時候對那些對象,加什麼類型的瑣,加鎖與索引的關係是怎麼樣的,什麼時候釋放鎖?整個 ...
一直以為很瞭解sqlserver的加鎖過程,在分析一些特殊情況下的死鎖之後,尤其是併發單表操作發生的死鎖,對於加解鎖的過程,有了一些重新的認識,之前的知識還是有一些盲區在裡面的。
delete加鎖與解鎖步驟是怎麼樣的?什麼時候對那些對象,加什麼類型的瑣,加鎖與索引的關係是怎麼樣的,什麼時候釋放鎖?整個過程鎖是如何參與整個delete操作過程表的?
這裡通過一個非常簡單的delete語句,來分析一條delete執行過程中加解鎖的過程。
測試表創建
用一個最最簡單的例子做了跟蹤,對鎖的申請和釋放,有了更清晰的認識,這個過程非常有意思,看完之後會非常清晰地認識到delete語句執行過程中加解鎖的步驟是怎麼樣的。
如果對一個SQL加解鎖的步驟不清楚,解決死鎖,只能說經驗,或者說是靠蒙、亦或靠優化SQL地去減少死鎖的可能性(天下武功,唯快不破)。
如下腳本,創建測試表,待用。
跟蹤的測試刪除sql語句為:delete from test_require_release_lock where col2 = 'a999' and col3 = 'b999',where條件的目標數據是1行,條件是用到where的第一個篩選條件的索引。
測試數據的基本信息
先拿到一些基本的信息對象id,索引Id,key值等物理Id(RowHashId)等等,這些Id稍後會清晰地展示在profile跟蹤日誌中,能幫助我們去瞭解到底在什麼對象(數據行,索引行)加什麼類型的鎖。
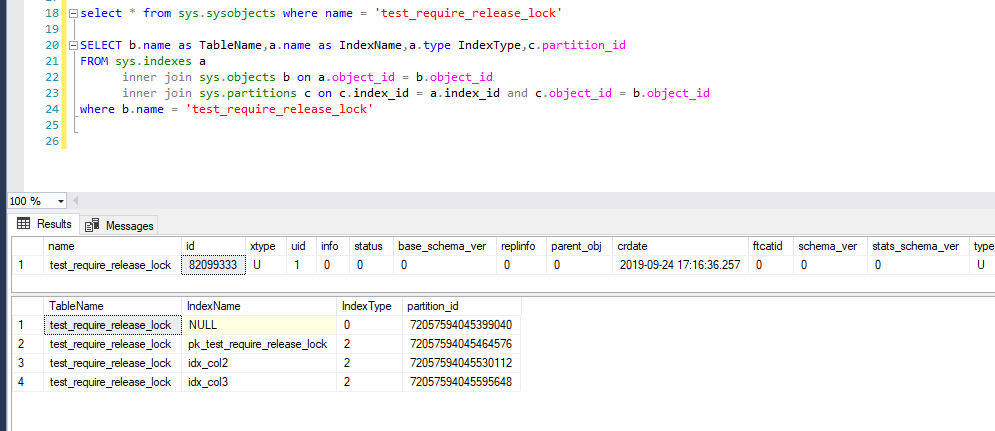
當前值得物理地址(RowHashId)
Profile跟蹤日誌
如下是profile跟蹤出來的delete from test_require_release_lock where col2 = 'a999' and col3 = 'b999'語句執行過程中表級別鎖的申請和釋放
我只能說:這個case包括數據,是反覆測試各種情況之後,最最簡單的一種情況了,稍微複雜一點的情況,對於一行數據的刪除,加解鎖的過程至少要兩屏才能顯示出來。
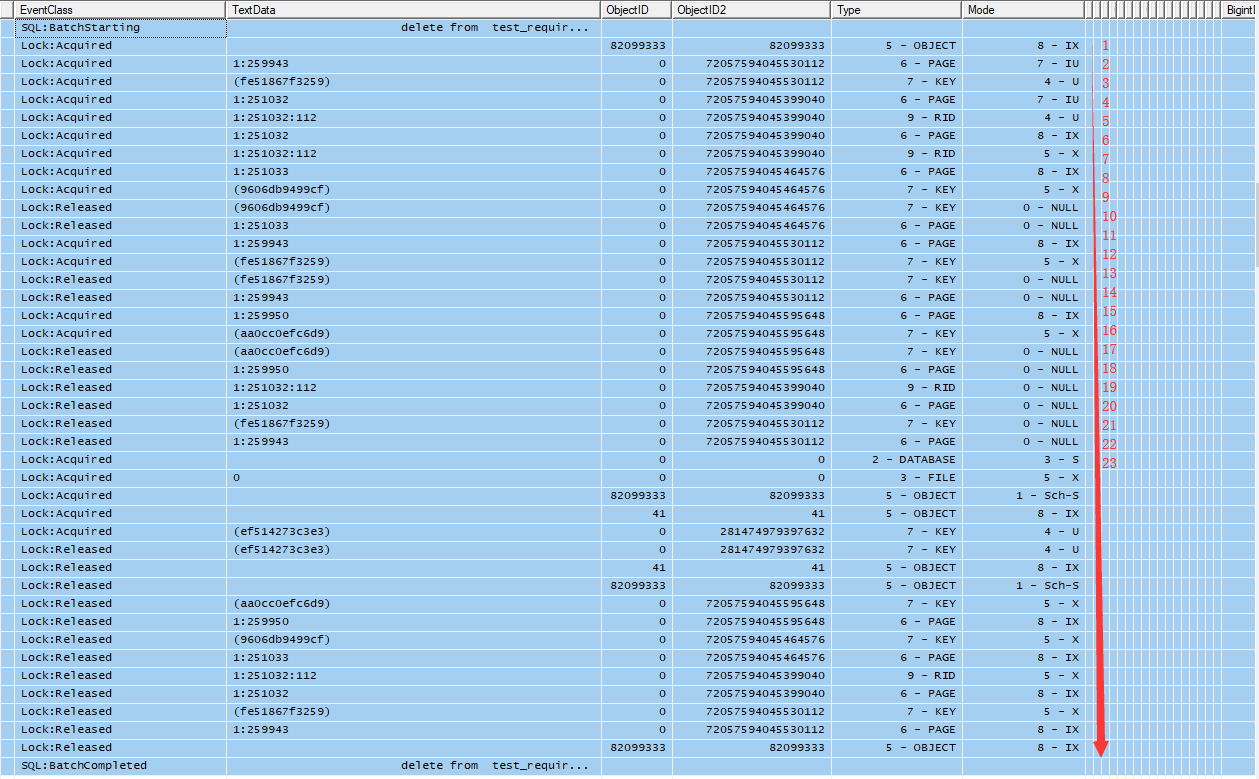
加解鎖過程分析
這個過程可以大致分為3個階段,僅僅執行一條數據刪除的delete語句,就有37步之多,為了簡化這個過程,這裡只看刪除過程中,數據/索引行上的加解鎖信息,如圖所示的前23步。
階段1:根據where條件查找數據的物理Id,也即RID,這個過程是IU/U鎖。雖然執行的是delete,此過程不刪任何數據,只是根據條件,找到數據的RID
階段2:依次刪除數據行和索引行,也即依次刪除RID,主鍵索引,多個索引鍵索引,這個過程涉及到第一步的IU/U鎖轉換IX/X以及新申請IX/X鎖
階段3:(刪除完成)依次釋放之前步驟申請尚未釋放的鎖
如下是profile中這個過程中每一步的說明
階段1:
1,申請基表82099333上意向IX鎖
2,申請目標行索引欄位col2(fe51867f3259)所在page的IU鎖
3,申請目標行索引欄位col2(fe51867f3259)Key級別的U鎖
4,申請目標所索引欄位col2(fe51867f3259)對應的RID所在page的IU鎖
5,申請目標所索引欄位col2(fe51867f3259)對應的RID行的RID的U鎖
階段2
6,升級4申請的IU鎖成IX鎖
7,升級5申請的U鎖成X鎖 ***刪除RID行,也即數據行
8,申請6(已經申請到的)RID對應的主鍵索引(9606db9499cf)所在page的IX鎖
9,申請主鍵索引的key級別的X鎖(9606db9499cf),***刪除主鍵行
10,釋放9申請的鎖
11,釋放8申請的鎖
12,申請目標行索引欄位col2 (fe51867f3259)所在page的IX鎖
13,申請目標行索引欄位col2(fe51867f3259)Key級別的X鎖,***刪除col2上的索引行
14,釋放13申請的鎖
15,釋放12申請的鎖
16,申請目標行索引欄位(fe51867f3259)對應的Col3欄位(aa0cc0efc6d9)索引所在page的IX鎖
17,申請目標行索引欄位(fe51867f3259)對應的Col3欄位(aa0cc0efc6d9)索引Key級別的X鎖,***刪除col3上的索引行
階段3
18,釋放16申請的鎖
19,釋放17申請的鎖
20,釋放6申請的鎖
21,釋放7申請的鎖
22,釋放4申請的鎖
23,釋放5申請的鎖
24~37 釋放其它鎖
從中可以看到,鎖的申請的簡化過程是,或者其規律是:
1,根據查詢條件,依次申請查詢欄位所在Page以及欄位key本身的IU/U鎖,因為這個階段是找數據(找到加IU/U),而不是直接上來就刪數據,所以是IU/U鎖
2,根據nocluster index 找到RID,從IU/U升級RID鎖稱IX/X,進行數據行的刪除
3,依次刪除主鍵索引,col2上的索引,col3上的索引,進行索引行的刪除
4,依次釋放加鎖信息,此過程於加鎖相反(先page再Key),依次釋放KEY/RID和Page上的鎖(先key再Page)
如果是聚集索引表,會用聚集索引Key提到RID,省略RID這一步的鎖操作。
從這裡可以看到,沒有聚集索引的表,主鍵索引跟普通的非聚集索引並無二致,最終還是要使用RID來定位數據。
這裡還能夠得到另外一個結論:因為這裡的主鍵索引是nonclustered的,因此該表還是數據堆表,既然是堆表,定位數據的還是RID,因此多了依次RID的鎖維護動作
以上跟蹤了一個最簡單的delete執行過程中的加鎖的步驟,其實情況可以更複雜:
1如果where條件用不到索引,
2如果where條件之一篩選出來的多行,繼續用另外的條件篩選,
3如果使用聚集索引篩選,
4如果where條件篩選後仍舊有多行數據
5如果where條件無法命中任何一行
6如果採用多個非聚集索引篩選後merge結果
稍微複雜一點的情況,涉及到的鎖都呈指數級增加,原本我以為很清楚sqlserver在執行delete操作的加鎖過程,其實還有很多細節,沒有註意到。
加解鎖是一個複雜的過程,即便是單表,也會涉及不同的索引以及數據行,為此並不難理解,為什麼對於單表,除了where條件不一致,為什麼會出現死鎖的原因。


