
Kafka常用術語 Broker :Kafka的服務端即Kafka實例,Kafka集群由一個或多個Broker組成,主要負責接收和處理客戶端的請求 Topic :主題,Kafka承載消息的邏輯容器,每條發佈到Kafka的消息都有對應的邏輯容器,工作中多用於區分業務 Partition :分區,是物理 ...
Kafka常用術語
Broker:Kafka的服務端即Kafka實例,Kafka集群由一個或多個Broker組成,主要負責接收和處理客戶端的請求
Topic:主題,Kafka承載消息的邏輯容器,每條發佈到Kafka的消息都有對應的邏輯容器,工作中多用於區分業務
Partition:分區,是物理概念,代表有序不變的消息序列,每個Topic由一個或多個Partion組成
Replica:副本,Kafka中同一條消息拷貝到多個地方做數據冗餘,這些地方就是副本,副本分為Leader和Follower,角色不同作用不同,副本是對Partition而言的,每個分區可配置多個副本來實現高可用
Record:消息,Kafka處理的對象
Offset:消息位移,分區中每條消息的位置信息,是單調遞增且不變的值
Producer:生產者,向主題發送新消息的應用程式
Consumer:消費者,從主題訂閱新消息的應用程式
Consumer Offset:消費者位移,記錄消費者的消費進度,每個消費者都有自己的消費者位移
Consumer Group:消費者組,多個消費者組成一個消費者組,同時消費多個分區來實現高可用(組內消費者的個數不能多於分區個數以免浪費資源)
Reblance:重平衡,消費組內消費者實例數量變更後,其他消費者實例自動重新分配訂閱主題分區的過程
下麵用一張圖展示上面提到的部分概念(用PPT畫的圖,太費勁了,畫了老半天,有好用的畫圖工具歡迎推薦)
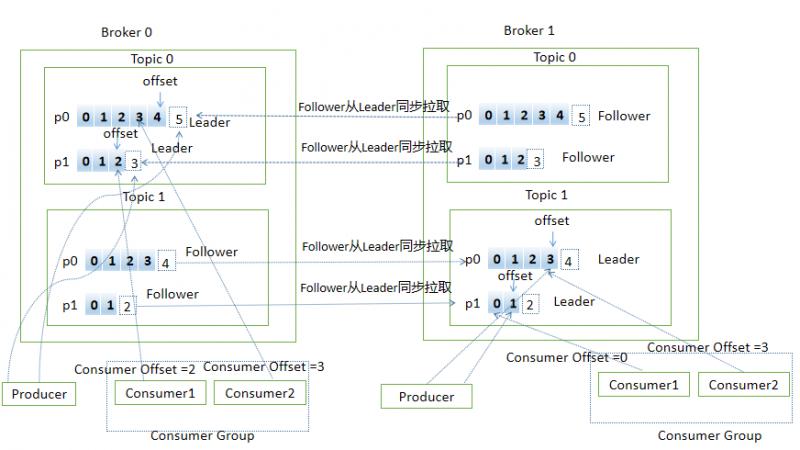
消息生產流程
先來個KafkaProducer的小demo
public static void main(String[] args) throws ExecutionException, InterruptedException {
if (args.length != 2) {
throw new IllegalArgumentException("usage: com.ding.KafkaProducerDemo bootstrap-servers topic-name");
}
Properties props = new Properties();
// kafka伺服器ip和埠,多個用逗號分割
props.put("bootstrap.servers", args[0]);
// 確認信號配置
// ack=0 代表producer端不需要等待確認信號,可用性最低
// ack=1 等待至少一個leader成功把消息寫到log中,不保證follower寫入成功,如果leader宕機同時follower沒有把數據寫入成功
// 消息丟失
// ack=all leader需要等待所有follower成功備份,可用性最高
props.put("ack", "all");
// 重試次數
props.put("retries", 0);
// 批處理消息的大小,批處理可以增加吞吐量
props.put("batch.size", 16384);
// 延遲發送消息的時間
props.put("linger.ms", 1);
// 用來換出數據的記憶體大小
props.put("buffer.memory", 33554432);
// key 序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value 序列化方式
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 創建KafkaProducer對象,創建時會啟動Sender線程
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
// 往RecordAccumulator中寫消息
Future<RecordMetadata> result = producer.send(new ProducerRecord<>(args[1], Integer.toString(i), Integer.toString(i)));
RecordMetadata rm = result.get();
System.out.println("topic: " + rm.topic() + ", partition: " + rm.partition() + ", offset: " + rm.offset());
}
producer.close();
}實例化
KafkaProducer構造方法主要是根據配置文件進行一些實例化操作
1.解析clientId,若沒有配置則由是producer-遞增的數字
2.解析並實例化分區器partitioner,可以實現自己的partitioner,比如根據key分區,可以保證相同key分到同一個分區,對保證順序很有用。若沒有指定分區規則,採用預設的規則(消息有key,對key做hash,然後對可用分區取模;若沒有key,用隨機數對可用分區取模【沒有key的時候說隨機數對可用分區取模不准確,counter值初始值是隨機的,但後面都是遞增的,所以可以算到roundrobin】)
3.解析key、value的序列化方式並實例化
4.解析並實例化攔截器
5.解析並實例化RecordAccumulator,主要用於存放消息(KafkaProducer主線程往RecordAccumulator中寫消息,Sender線程從RecordAccumulator中讀消息併發送到Kafka中)
6.解析Broker地址
7.創建一個Sender線程並啟動
...
this.sender = newSender(logContext, kafkaClient, this.metadata);
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
...消息發送流程
消息的發送入口是KafkaProducer.send方法,主要過程如下
KafkaProducer.send
KafkaProducer.doSend
// 獲取集群信息
KafkaProducer.waitOnMetadata
// key/value序列化
key\value serialize
// 分區
KafkaProducer.partion
// 創建TopciPartion對象,記錄消息的topic和partion信息
TopicPartition
// 寫入消息
RecordAccumulator.applend
// 喚醒Sender線程
Sender.wakeupRecordAccumulator
RecordAccumulator是消息隊列用於緩存消息,根據TopicPartition對消息分組
重點看下RecordAccumulator.applend追加消息的流程
// 記錄進行applend的線程數
appendsInProgress.incrementAndGet();// 根據TopicPartition獲取或新建Deque雙端隊列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
...
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
Deque<ProducerBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}// 嘗試將消息加入到緩衝區中
// 加鎖保證同一個TopicPartition寫入有序
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 嘗試寫入
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, Deque<ProducerBatch> deque) {
// 從雙端隊列的尾部取出ProducerBatch
ProducerBatch last = deque.peekLast();
if (last != null) {
// 取到了,嘗試添加消息
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
// 空間不夠,返回null
if (future == null)
last.closeForRecordAppends();
else
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
// 取不到返回null
return null;
}public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
// 空間不夠,返回null
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null;
} else {
// 真正添加消息
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
...
FutureRecordMetadata future = ...
// future和回調callback進行關聯
thunks.add(new Thunk(callback, future));
...
return future;
}
}// 嘗試applend失敗(返回null),會走到這裡。如果tryApplend成功直接返回了
// 從BufferPool中申請記憶體空間,用於創建新的ProducerBatch
buffer = free.allocate(size, maxTimeToBlock);synchronized (dq) {
// 註意這裡,前面已經嘗試添加失敗了,且已經分配了記憶體,為何還要嘗試添加?
// 因為可能已經有其他線程創建了ProducerBatch或者之前的ProducerBatch已經被Sender線程釋放了一些空間,所以在嘗試添加一次。這裡如果添加成功,後面會在finally中釋放申請的空間
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 嘗試添加失敗了,新建ProducerBatch
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// 將buffer置為null,避免在finally彙總釋放空間
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}finally {
// 最後如果再次嘗試添加成功,會釋放之前申請的記憶體(為了新建ProducerBatch)
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}// 將消息寫入緩衝區
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
// 緩衝區滿了或者新創建的ProducerBatch,喚起Sender線程
this.sender.wakeup();
}
return result.future;Sender發送消息線程
主要流程如下
Sender.run
Sender.runOnce
Sender.sendProducerData
// 獲取集群信息
Metadata.fetch
// 獲取可以發送消息的分區且已經獲取到了leader分區的節點
RecordAccumulator.ready
// 根據準備好的節點信息從緩衝區中獲取topicPartion對應的Deque隊列中取出ProducerBatch信息
RecordAccumulator.drain
// 將消息轉移到每個節點的生產請求隊列中
Sender.sendProduceRequests
// 為消息創建生產請求隊列
Sender.sendProducerRequest
KafkaClient.newClientRequest
// 下麵是發送消息
KafkaClient.sent
NetWorkClient.doSent
Selector.send
// 其實上面並不是真正執行I/O,只是寫入到KafkaChannel中
// poll 真正執行I/O
KafkaClient.poll通過源碼分析下Sender線程的主要流程
KafkaProducer的構造方法在實例化時啟動一個KafkaThread線程來執行Sender
// KafkaProducer構造方法啟動Sender
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();// Sender->run()->runOnce()
long currentTimeMs = time.milliseconds();
// 發送生產的消息
long pollTimeout = sendProducerData(currentTimeMs);
// 真正執行I/O操作
client.poll(pollTimeout, currentTimeMs);// 獲取集群信息
Cluster cluster = metadata.fetch();// 獲取準備好可以發送消息的分區且已經獲取到leader分區的節點
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// ReadyCheckResult 包含可以發送消息且獲取到leader分區的節點集合、未獲取到leader分區節點的topic集合
public final Set<Node> 的節點;
public final long nextReadyCheckDelayMs;
public final Set<String> unknownLeaderTopics;ready方法主要是遍歷在上面介紹RecordAccumulator添加消息的容器,Map<TopicPartition, Deque
// 遍歷batches
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<ProducerBatch> deque = entry.getValue();
// 根據TopicPartition從集群信息獲取leader分區所在節點
Node leader = cluster.leaderFor(part);
synchronized (deque) {
if (leader == null && !deque.isEmpty()) {
// 添加未找到對應leader分區所在節點但有要發送的消息的topic
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part, nowMs)) {
....
if (sendable && !backingOff) {
// 添加準備好的節點
readyNodes.add(leader);
} else {
...
}然後對返回的unknownLeaderTopics進行遍歷,將topic加入到metadata信息中,調用metadata.requestUpdate方法請求更新metadata信息
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
result.unknownLeaderTopics);
this.metadata.requestUpdate();對已經準備好的節點進行最後的檢查,移除那些節點連接沒有就緒的節點,主要根據KafkaClient.ready方法進行判斷
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
// 調用KafkaClient.ready方法驗證節點連接是否就緒
if (!this.client.ready(node, now)) {
// 移除沒有就緒的節點
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}下麵開始創建生產消息的請求
// 從RecordAccumulator中取出TopicPartition對應的Deque雙端隊列,然後從雙端隊列頭部取出ProducerBatch,作為要發送的信息
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);把消息封裝成ClientRequest
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);調用KafkaClient發送消息(並非真正執行I/O),涉及到KafkaChannel。Kafka的通信採用的是NIO方式
// NetworkClient.doSent方法
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
...
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);
this.inFlightRequests.add(inFlightRequest);
selector.send(send);
...
// Selector.send方法
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
this.failedSends.add(connectionId);
} else {
try {
channel.setSend(send);
...到這裡,發送消息的工作准備的差不多了,調用KafkaClient.poll方法,真正執行I/O操作
client.poll(pollTimeout, currentTimeMs);用一張圖總結Sender線程的流程
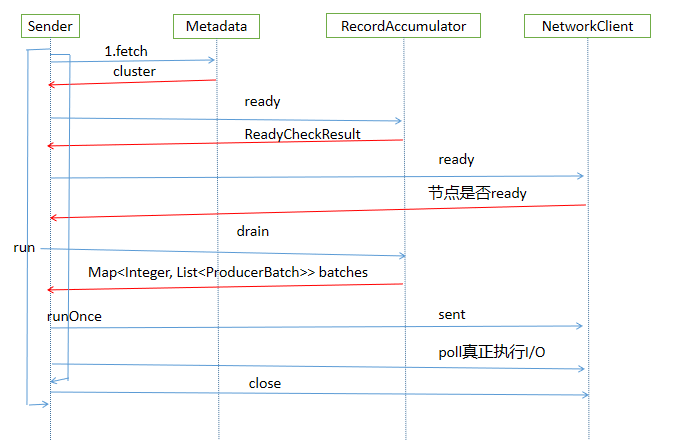
通過上面的介紹,我們梳理出了Kafka生產消息的主要流程,涉及到主線程往RecordAccumulator中寫入消息,同時後臺的Sender線程從RecordAccumulator中獲取消息,使用NIO的方式把消息發送給Kafka,用一張圖總結
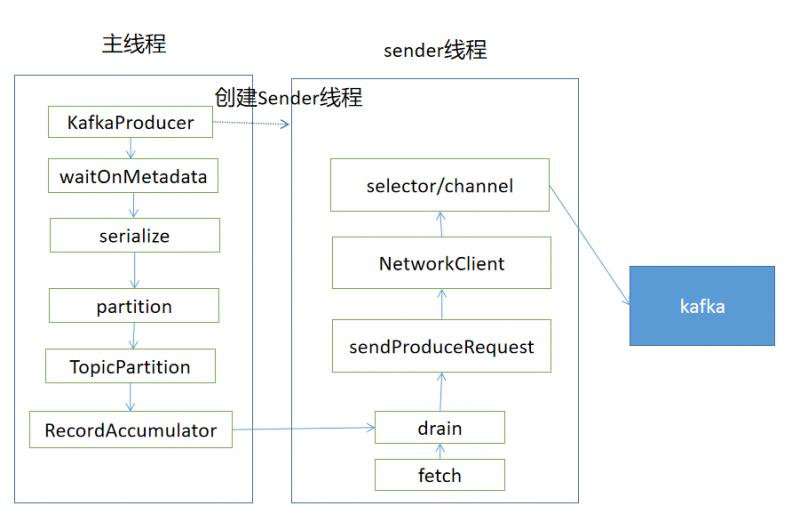
後記
這是本公眾號第一次嘗試寫源碼相關的文章,說實話真不知道該如何下筆,代碼截圖、貼整體代碼等感覺都被我否定了,最後採用了這種方式,介紹主要流程,把無關代碼省略,配合流程圖。
上周參加了華為雲kafka實戰課程,簡單看了下kafka的生產和消費代碼,想簡單梳理下,然後在周日中午即8.17開始閱讀源碼,梳理流程,一直寫到了晚上12點多,還剩一點沒有完成,周一早晨早起完成了這篇文章。當然這篇文章忽略了很多更細節的東西,後面會繼續深入,勇於嘗試,不斷精進,加油!
參考資料
華為雲實戰
極客時間kafka專欄


