
背景 By 魯迅 By 高爾基 說明: 1. Kernel版本:4.14 2. ARM64處理器,Contex A53,雙核 3. 使用工具:Source Insight 3.5, Visio 1. 介紹 順著之前的分析,我們來到了 函數了,本以為一篇文章能搞定,大概掃了一遍代碼之後,我默默的把它拆 ...
背景
Read the fucking source code!--By 魯迅A picture is worth a thousand words.--By 高爾基
說明:
- Kernel版本:4.14
- ARM64處理器,Contex-A53,雙核
- 使用工具:Source Insight 3.5, Visio
1. 介紹
順著之前的分析,我們來到了bootmem_init()函數了,本以為一篇文章能搞定,大概掃了一遍代碼之後,我默默的把它拆成了兩部分。
bootmem_init()函數代碼如下:
void __init bootmem_init(void)
{
unsigned long min, max;
min = PFN_UP(memblock_start_of_DRAM());
max = PFN_DOWN(memblock_end_of_DRAM());
early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT);
max_pfn = max_low_pfn = max;
arm64_numa_init();
/*
* Sparsemem tries to allocate bootmem in memory_present(), so must be
* done after the fixed reservations.
*/
arm64_memory_present();
sparse_init();
zone_sizes_init(min, max);
memblock_dump_all();
}這一部分,我們將研究一下Sparse Memory Model。
在講Linux記憶體模型之前,需要補充兩個知識點:PFN和NUMA。
1.1 physical frame number(PFN)
前面我們講述過了虛擬地址到物理地址的映射過程,而系統中對記憶體的管理是以頁為單位的:
page:線性地址被分成以固定長度為單位的組,稱為頁,比如典型的4K大小,頁內部連續的線性地址被映射到連續的物理地址中;
page frame:記憶體被分成固定長度的存儲區域,稱為頁框,也叫物理頁。每一個頁框會包含一個頁,頁框的長度和一個頁的長度是一致的,在內核中使用struct page來關聯物理頁。
如下圖,PFN從圖片中就能看出來了:
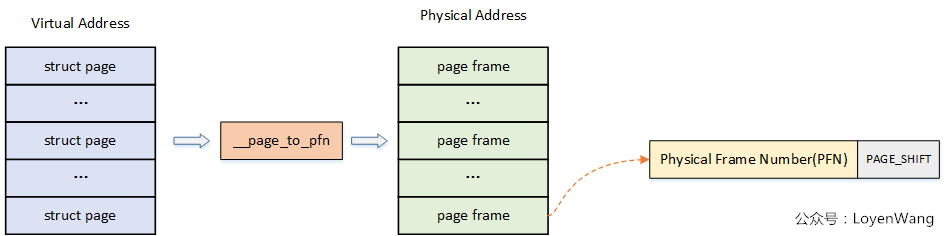
至於__page_to_pfn這個實現取決於具體的物理記憶體模型,下文將進行介紹。
1.2 NUMA
UMA: Uniform Memory Access,所有處理器對記憶體的訪問都是一致的:
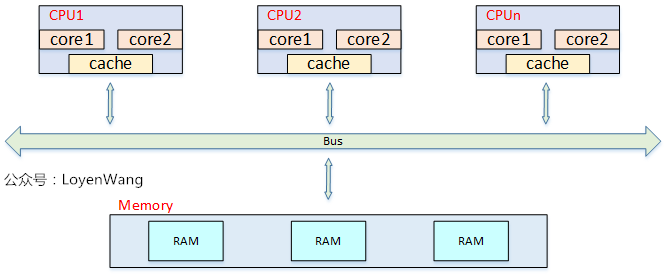
從上圖中可以看出,當處理器和Core變多的時候,記憶體帶寬將成為瓶頸問題。
NUMA: Non Uniform Memory Access,非一致性記憶體訪問:
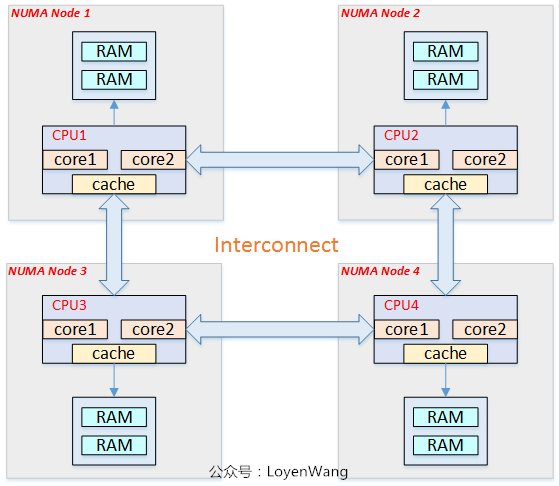
從圖中可以看出,每個CPU訪問local memory,速度更快,延遲更小。當然,整體的記憶體構成一個記憶體池,CPU也能訪問remote memory,相對來說速度更慢,延遲更大。目前對NUMA的瞭解僅限於此,在內核中會遇到相關的代碼,大概知道屬於什麼範疇就可以了。
2. Linux記憶體模型
Linux提供了三種記憶體模型(include/asm-generic/memory_model.h):
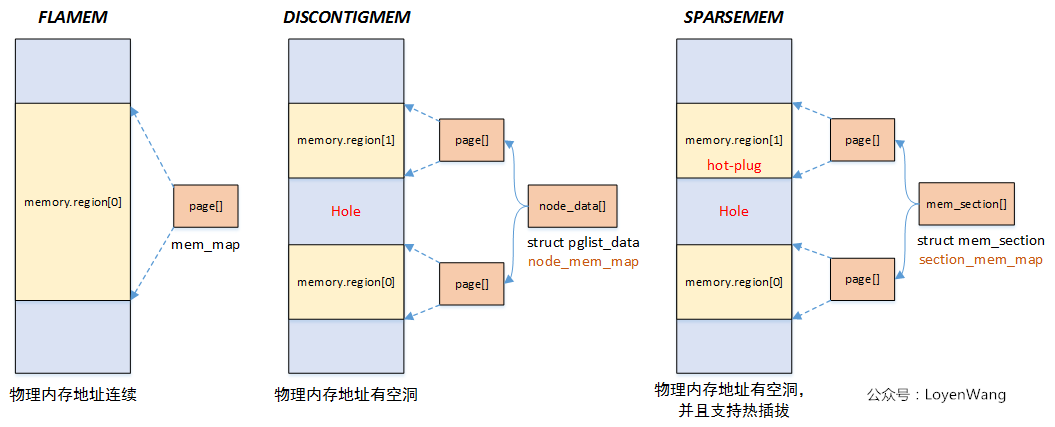
一般處理器架構支持一種或者多種記憶體模型,這個在編譯階段就已經確定,比如目前在ARM64中,使用的Sparse Memory Model。
Flat Memory
物理記憶體地址連續,這個也是Linux最初使用的記憶體模型。當記憶體有空洞的時候也是可以使用這個模型,只是struct page *mem_map數組的大小跟物理地址正相關,記憶體有空洞會造成浪費。Discontiguous Memory
物理記憶體存在空洞,隨著Sparse Memory的提出,這種記憶體模型也逐漸被棄用了。Sparse Memory
物理記憶體存在空洞,並且支持記憶體熱插拔,以section為單位進行管理,這也是下文將分析的。
Linux三種記憶體模型下,struct page到物理page frame的映射方式也不一樣,具體可以查看include/asm-generic/memory_model.h文件中的__pfn_to_page/__page_to_pfn定義。
關於記憶體模型,可以參考Memory: the flat, the discontiguous, and the sparse
3. Sparse Memory
本節分析的是ARM64, UMA(linux4.14中不支持ARM NUMA)下的Sparse Memory模型。
3.1 mem_section
在Sparse Memory模型中,section是管理記憶體online/offline的最小記憶體單元,在ARM64中,section的大小為1G,而在Linux內核中,通過一個全局的二維數組struct mem_section **mem_section來維護映射關係。
函數的調用過程如下所示,主要在arm64_memory_present中來完成初始化及映射關係的建立:

函數調用結束之後的映射關係如下圖所示:
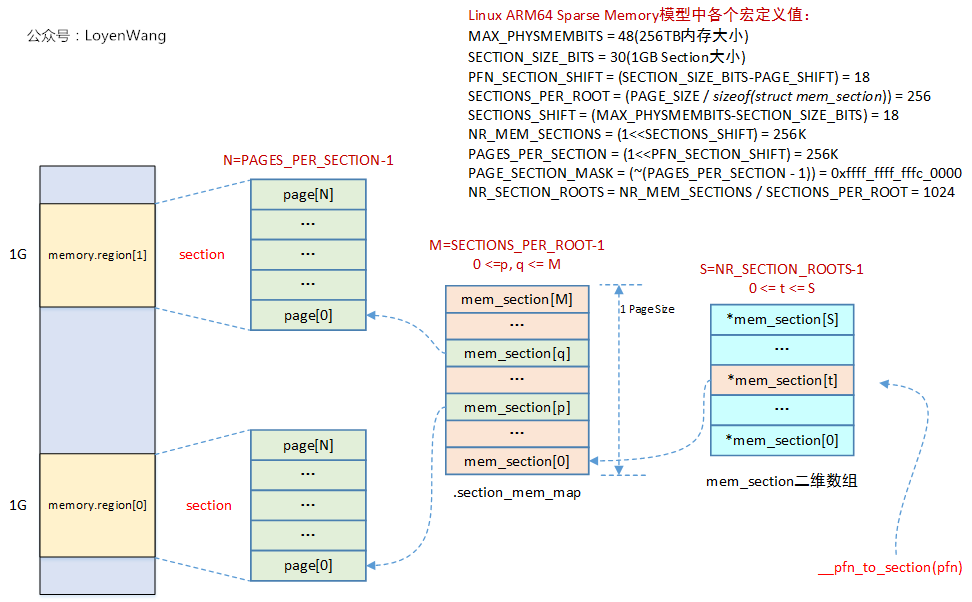
已知一個pfn時,可以通過__pfn_to_section(pfn)來最終找到對應的struct page結構。
3.2 sparse_init
看看sparse_init函數的調用關係圖:

在該函數中,首先分配了usermap,這個usermap與記憶體的回收機制相關,用4bit的bitmap來描述page block(一個pageblock大小通常為2的次冪,比如MAX_ORDER-1)的遷移類型:
/* Bit indices that affect a whole block of pages */
enum pageblock_bits {
PB_migrate,
PB_migrate_end = PB_migrate + 3 - 1,
/* 3 bits required for migrate types */
PB_migrate_skip,/* If set the block is skipped by compaction */
/*
* Assume the bits will always align on a word. If this assumption
* changes then get/set pageblock needs updating.
*/
NR_PAGEBLOCK_BITS
};sparse memory模型會為每一個section都分配一個usermap,最終的物理頁面的壓縮,遷移等操作,都跟這些位相關,如下圖所示:
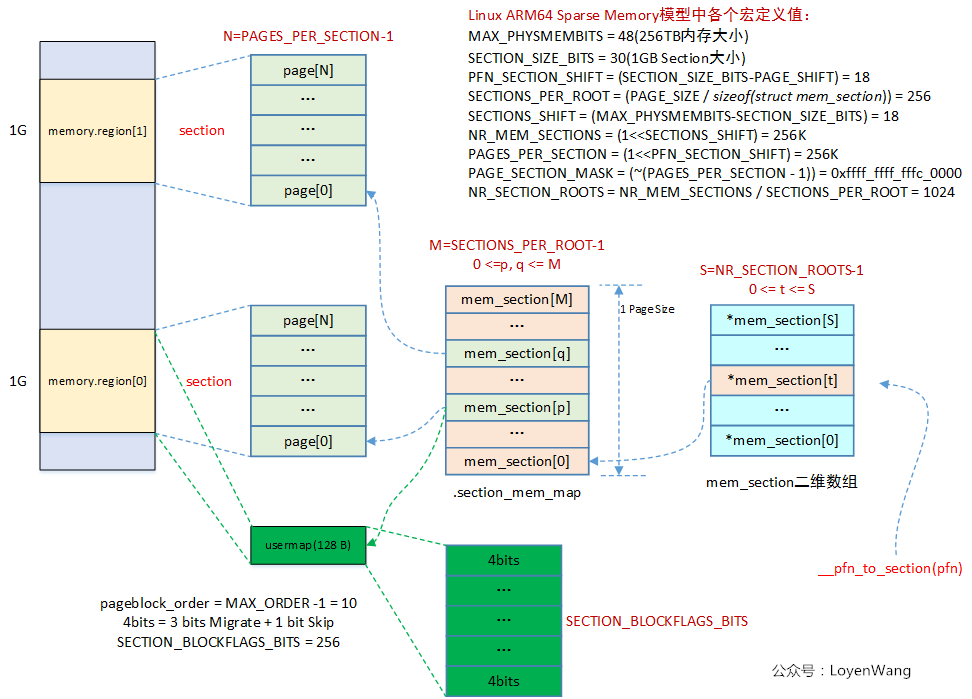
sparse_init函數中,另一部分的作用是遍歷所有present section,然後將其映射到vmemmap區域空間。vmemmap區域空間,在之前的文章中也提到過。執行完後,整體的效果如下圖所示:
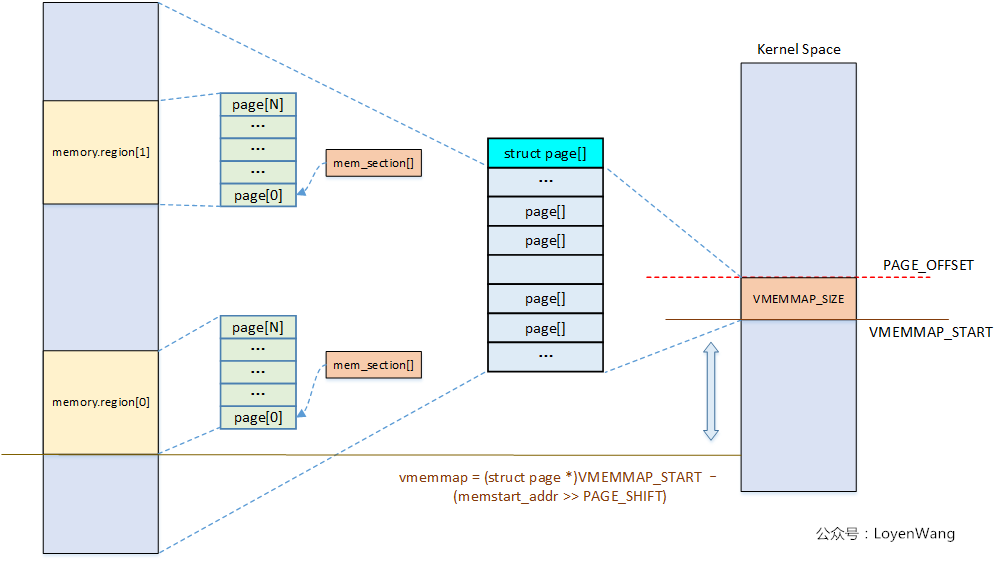
關於Sparse Memory Model就先分析這麼多,只有結合使用sparse memory的具體模塊時,理解才會更順暢。
一不小心就容易扣細節,而一旦陷入細節,內核就容易變成魔鬼,太難了。


