
Explain工具介紹 使用EXPLAIN關鍵字可以模擬優化器執行SQL語句,分析查詢語句或是結構的性能瓶頸。在select語句之前增加explaion關鍵字,MySQL會在查詢上設置一個標記,執行查詢會返回執行計劃的信息,而不是執行SQL。 Explaion分析示例 actor建表語句: CREA ...
Explain工具介紹
使用EXPLAIN關鍵字可以模擬優化器執行SQL語句,分析查詢語句或是結構的性能瓶頸。在select語句之前增加explaion關鍵字,MySQL會在查詢上設置一個標記,執行查詢會返回執行計劃的信息,而不是執行SQL。
Explaion分析示例
-- actor建表語句:
CREATE TABLE `actor` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- film建表語句:
CREATE TABLE `film` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- film_actor建表語句:
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL,
`film_id` int(11) NOT NULL,
`actor_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8執行explain:
explain select * from actor;
如果是select語句返回的是執行結果,在select語句前面加上explain返回的是這條查詢語句的執行SQL。
EXPLAIN兩個變種
explain extended
會在explain的基礎上額外提供一些查詢優化的信息。緊隨其後通過show warnings命令可以得到優化後的查詢語句,從而看出優化器優化了什麼。額外還有filtered列,是一個半分比的值,rows*filtered / 100可以估算出將要和explain中前一個表進行連接的行數(前一個表指explain中的id值比當前表id值小的表)。
explain EXTENDED select * from actor where id = 1;
explain partitions
相比explain多了個partitions欄位,如果查詢是基於分區表的話,會顯示查詢將訪問的分區。
Explain中的列
id列
id列的編號是select的序列號,有幾個select就有幾個id,並且id的順序是按select出現的順序增長的。
id越大執行優先順序越高,id相同則從上往下執行,id為NULL最後執行。
explain select (select 1 from actor where id = 1) from (select * from film
where id = 1) der;
select type列
select type表示對應行是簡單還是複雜的查詢。
simple:簡單查詢。查詢不包含子查詢和union。
explain select * from film where id=1
primary:複雜查詢中最外層的select
subquery:包含在select中的子查詢(不在from子句中)
derived:包含在from子句中的子查詢。MySQL會將結果存放在一個臨時表中,也稱為派生表。
explain select (select 1 from actor where id = 1) from (select * from film
where id = 1) der;
union:在union關鍵字隨後的selelct。
EXPLAIN select 1 union all select 1;
table列
這一列表示explain的一行正在訪問哪個表。
當from子句中有子查詢時,table列是
當有union時,UNION RESULT的table列的值為<union 1,2>,1和2表示參與union的select行id。
type列
這一列表示關聯類型或訪問類型,即MySQL決定如何查找表中的行,查找數據行對應的大概範圍。
依次從最優到最差的分別為:system>const>eq_ref>ref>range>index>All
一般來說,得保證查詢達到range級別,最好達到ref。
NULL:MySQL能夠在優化階段分解查詢語句,在執行階段用不著在訪問表或索引。例如:在索引列中選取最小值,可以單獨查找索引來完成,不需在執行時訪問表。
EXPLAIN select min(id) from film;
- const、system:mysql能對查詢的某部分進行優化並將其轉換成一個常量(可看成是show warnings的結果)。用於primay key或unique key的所有列與常數比較時,所以表最多有一個匹配行,讀取1次,速讀較快。system 是const的特例,表中只有一行元素匹配時為system。
EXPLAIN select * from (select * from film where id= 1) as tmp;
- eq_ref:primay key或 unique key索引的所有部分被連接使用,最多只會返回一條符合條件的記錄。這可能是const之外最好的聯接類型,簡單的select查詢不會出現這種type。
EXPLAIN select * from (select * from film where id= 1) as tmp;
- ref:相比eq_ref,不適用唯一索引,而是使用普通索引或者唯一索引的部分首碼,索引要和某個值相比較,可能會找到多個符合條件的行。
簡單select查詢,name是普通索引(非主鍵索引或唯一索引)
EXPLAIN select * from film where name='film1';
關聯表查詢,idx_film_actor_id是film_id和actor_id的聯合索引,這裡使用到了film_actor的左邊首碼film_id部分。
EXPLAIN select film_id from film LEFT JOIN film_actor on film.id = film_actor.film_id;
- range:範圍掃描通常出現在in(), between,>,<,>=等操作中。使用一個索引來檢索給定範圍的行。
EXPLAIN select * from actor WHERE id >1;
- index:掃描全表索引,通常比All快一些
EXPLAIN select * from film;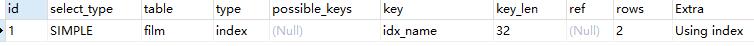
- all:即全表掃描,意味著MySQL需要從頭到尾去查找所需要的行。這種情況下需要增加索引來進行優化。
EXPLAIN SELECT * from actor;
possible_keys列
這一列顯示select可能會使用哪些查詢來查找。
explain時可能會出現possible_keys有列,而key顯示為NULL的情況,這種情況是因為表中的數據不多,MySQL認為索引對此查詢幫助不大,選擇了全表掃描。
如果該列為NULL,則沒有相關的索引。這種情況下,可以通過檢查where子句看是否可以創造一個適當的索引來提高查詢性能,然後用explain查看效果。
EXPLAIN SELECT * from film_actor where film_id =1;
key列
這一列顯示MySQL實際採用哪個索引對該表的訪問。
如果沒有使用索引,則改列為NULL。如果想強制MySQL使用或忽視possible_keys列中的索引,在查詢中使用force index、 ignore index。
key_len列
這一列顯示了mysql在索引里使用的位元組數,通過這個值可以估算出具體使用了索引中的哪些列。
EXPLAIN SELECT * from film_actor where film_id =1;
film_actor的聯合索引idx_film_actor_id由film_id和actor_id兩個id列組成,並且每個int是4位元組。通過結果中的key_len=4可推斷出查詢使用了第一個列:film_id列來執行索引查找。
ken_len計算規則如下:
字元串
char(n):n位元組長度
varchar(n):n位元組存儲字元串長度,如果是utf-8, 則長度是3n+2數值類型
tinyint:1位元組
smallint:2位元組
int:4位元組
bigint:8位元組時間類型
date:3位元組
timestamp:4位元組
datetime:8位元組
如果欄位允許為NULL,需要1位元組記錄是否為NULL
索引最大長度是768位元組,當字元串過長時,MySQL會做一個類似做首碼索引的處理,將前半部分的字元串提取出來做索引。
ref列
這一列顯示了在key列記錄的索引中,表查找值所用到的列或常量,常見的有: const(常量),欄位名等。一般是查詢條件或關聯條件中等號右邊的值,如果是常量那麼ref列是const,非常量的話ref列就是欄位名。
EXPLAIN SELECT * from film_actor where film_id =1;
row列
這一列是mysql估計要讀取並檢測的行數,註意這個不是結果集的行數。
Extra列
這一列是額外信息。
- Using index:使用覆蓋索引(結果集的欄位是索引,即select後的film_id)
explain select film_id from film_actor where film_id=1;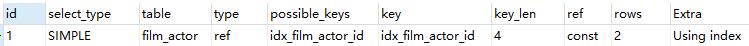
- Using index condition:查詢的列不完全被索引覆蓋,where條件中是一個前導的範圍
explain select * from film_actor where film_id > 1;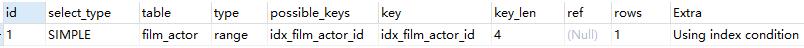
- Using where:使用where語句來處理結果,查詢的列未被索引覆蓋
explain select * from actor where name ='a'
- Using temporary:mysql需要創建一張臨時表來處理查詢。出現這種情況一般要進行優化,首先要想到是索引優化。
explain select DISTINCT name from actor;
actor.name沒有索引,此時創建了臨時表來處理distinct。
explain select DISTINCT name from film;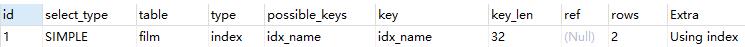
file.name建立了普通索引,此時查詢時Extra是Using index,沒有用到臨時表。
- Using filesort:將用外部排序而不是索引排序,數據較小時從記憶體排序,否則需要在磁碟完成排序。這種情況下一般也是要考慮使用索引來優化的。
explain select * from actor order by name;
actor.name未創建索引,會瀏覽acotr整個表,保存排序關鍵字name和對應id,然後排序name並檢索行記錄。
explain select * from film order by name;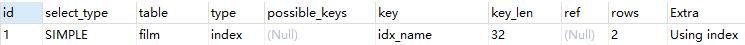
film.name建立了idx_name索引,此時查詢時extra是Using index。
- select tables optimized away:使用某些聚合函數(比如:max、min)來訪問存在索引的某個欄位
explain select min(id) from film ;
還沒關註我的公眾號?
- 掃文末二維碼關註公眾號【小強的進階之路】可領取如下:
- 學習資料: 1T視頻教程:涵蓋Javaweb前後端教學視頻、機器學習/人工智慧教學視頻、Linux系統教程視頻、雅思考試視頻教程;
- 100多本書:包含C/C++、Java、Python三門編程語言的經典必看圖書、LeetCode題解大全;
- 軟體工具:幾乎包括你在編程道路上的可能會用到的大部分軟體;
- 項目源碼:20個JavaWeb項目源碼。



