
微信公眾號【黃小斜】作者是螞蟻金服 JAVA 工程師,目前在螞蟻財富負責後端開發工作,專註於 JAVA 後端技術棧,同時也懂點投資理財,堅持學習和寫作,用大廠程式員的視角解讀技術與互聯網,我的世界里不只有 coding!關註公眾號後回覆”架構師“即可領取 Java基礎、進階、項目和架構師等免費學習資 ...
微信公眾號【黃小斜】作者是螞蟻金服 JAVA 工程師,目前在螞蟻財富負責後端開發工作,專註於 JAVA 後端技術棧,同時也懂點投資理財,堅持學習和寫作,用大廠程式員的視角解讀技術與互聯網,我的世界里不只有 coding!關註公眾號後回覆”架構師“即可領取 Java基礎、進階、項目和架構師等免費學習資料,更有資料庫、分散式、微服務等熱門技術學習視頻,內容豐富,兼顧原理和實踐,另外也將贈送作者原創的Java學習指南、Java程式員面試指南等乾貨資源

之前看到一篇文章說epoll中在維護epoll句柄數據結構時使用到了mmap的技術,但是後來看了其他文章以及epoll源碼後發現好像並沒有用到這個技術。
轉自知乎:
epoll_wait的實現~有關從內核態拷貝到用戶態代碼.可以看到__put_user這個函數就是內核拷貝到用戶空間.分析完整個linux 2.6版本的epoll實現沒有發現使用了mmap系統調用,根本不存在共用記憶體在epoll的實現
if (revents) {
/* 將當前的事件和用戶傳入的數據都copy給用戶空間,
* 就是epoll_wait()後應用程式能讀到的那一堆數據. */
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
/* 如果copy過程中發生錯誤, 會中斷鏈表的掃描,
* 並把當前發生錯誤的epitem重新插入到ready list.
* 剩下的沒處理的epitem也不會丟棄, 在ep_scan_ready_list()
* 中它們也會被重新插入到ready list */
list_add(&epi->rdllink, head);
return eventcnt ? eventcnt : -EFAULT;
}那麼既然提到了,就讓我們看看mmap到底是什麼吧
mmap:記憶體映射文件
轉自:https://www.cnblogs.com/huxiao-tee/p/4660352.html
mmap基礎概念
mmap是一種記憶體映射文件的方法,即將一個文件或者其它對象映射到進程的地址空間,實現文件磁碟地址和進程虛擬地址空間中一段虛擬地址的一一對映關係。實現這樣的映射關係後,進程就可以採用指針的方式讀寫操作這一段記憶體,而系統會自動回寫臟頁面到對應的文件磁碟上,即完成了對文件的操作而不必再調用read,write等系統調用函數。相反,內核空間對這段區域的修改也直接反映用戶空間,從而可以實現不同進程間的文件共用。如下圖所示:
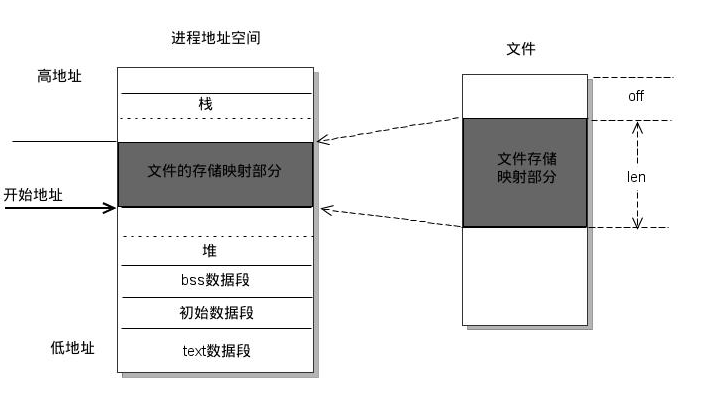
由上圖可以看出,進程的虛擬地址空間,由多個虛擬記憶體區域構成。虛擬記憶體區域是進程的虛擬地址空間中的一個同質區間,即具有同樣特性的連續地址範圍。上圖中所示的text數據段(代碼段)、初始數據段、BSS數據段、堆、棧和記憶體映射,都是一個獨立的虛擬記憶體區域。而為記憶體映射服務的地址空間處在堆棧之間的空餘部分。
linux內核使用vm_area_struct結構來表示一個獨立的虛擬記憶體區域,由於每個不同質的虛擬記憶體區域功能和內部機制都不同,因此一個進程使用多個vm_area_struct結構來分別表示不同類型的虛擬記憶體區域。各個vm_area_struct結構使用鏈表或者樹形結構鏈接,方便進程快速訪問,如下圖所示:
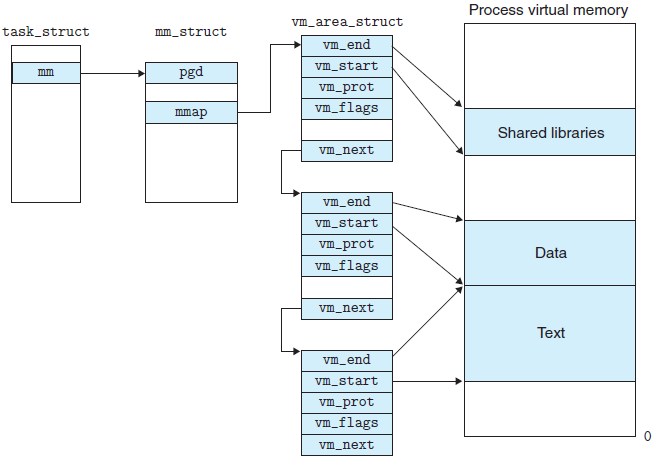
vm_area_struct結構中包含區域起始和終止地址以及其他相關信息,同時也包含一個vm_ops指針,其內部可引出所有針對這個區域可以使用的系統調用函數。這樣,進程對某一虛擬記憶體區域的任何操作需要用要的信息,都可以從vm_area_struct中獲得。mmap函數就是要創建一個新的vm_area_struct結構,並將其與文件的物理磁碟地址相連。具體步驟請看下一節。
mmap記憶體映射原理
mmap記憶體映射的實現過程,總的來說可以分為三個階段:
(一)進程啟動映射過程,併在虛擬地址空間中為映射創建虛擬映射區域
1、進程在用戶空間調用庫函數mmap,原型:void mmap(void start, size_t length, int prot, int flags, int fd, off_t offset);
2、在當前進程的虛擬地址空間中,尋找一段空閑的滿足要求的連續的虛擬地址
3、為此虛擬區分配一個vm_area_struct結構,接著對這個結構的各個域進行了初始化
4、將新建的虛擬區結構(vm_area_struct)插入進程的虛擬地址區域鏈表或樹中
(二)調用內核空間的系統調用函數mmap(不同於用戶空間函數),實現文件物理地址和進程虛擬地址的一一映射關係
5、為映射分配了新的虛擬地址區域後,通過待映射的文件指針,在文件描述符表中找到對應的文件描述符,通過文件描述符,鏈接到內核“已打開文件集”中該文件的文件結構體(struct file),每個文件結構體維護著和這個已打開文件相關各項信息。
6、通過該文件的文件結構體,鏈接到file_operations模塊,調用內核函數mmap,其原型為:int mmap(struct file filp, struct vm_area_struct vma),不同於用戶空間庫函數。
7、內核mmap函數通過虛擬文件系統inode模塊定位到文件磁碟物理地址。
8、通過remap_pfn_range函數建立頁表,即實現了文件地址和虛擬地址區域的映射關係。此時,這片虛擬地址並沒有任何數據關聯到主存中。
(三)進程發起對這片映射空間的訪問,引發缺頁異常,實現文件內容到物理記憶體(主存)的拷貝
註:前兩個階段僅在於創建虛擬區間並完成地址映射,但是並沒有將任何文件數據的拷貝至主存。真正的文件讀取是當進程發起讀或寫操作時。
9、進程的讀或寫操作訪問虛擬地址空間這一段映射地址,通過查詢頁表,發現這一段地址並不在物理頁面上。因為目前只建立了地址映射,真正的硬碟數據還沒有拷貝到記憶體中,因此引發缺頁異常。
10、缺頁異常進行一系列判斷,確定無非法操作後,內核發起請求調頁過程。
11、調頁過程先在交換緩存空間(swap cache)中尋找需要訪問的記憶體頁,如果沒有則調用nopage函數把所缺的頁從磁碟裝入到主存中。
12、之後進程即可對這片主存進行讀或者寫的操作,如果寫操作改變了其內容,一定時間後系統會自動回寫臟頁面到對應磁碟地址,也即完成了寫入到文件的過程。
註:修改過的臟頁面並不會立即更新迴文件中,而是有一段時間的延遲,可以調用msync()來強制同步, 這樣所寫的內容就能立即保存到文件里了。
mmap和常規文件操作的區別
對linux文件系統不瞭解的朋友,請參閱我之前寫的博文《從內核文件系統看文件讀寫過程》,我們首先簡單的回顧一下常規文件系統操作(調用read/fread等類函數)中,函數的調用過程:
1、進程發起讀文件請求。
2、內核通過查找進程文件符表,定位到內核已打開文件集上的文件信息,從而找到此文件的inode。
3、inode在address_space上查找要請求的文件頁是否已經緩存在頁緩存中。如果存在,則直接返回這片文件頁的內容。
4、如果不存在,則通過inode定位到文件磁碟地址,將數據從磁碟複製到頁緩存。之後再次發起讀頁面過程,進而將頁緩存中的數據發給用戶進程。
總結來說,常規文件操作為了提高讀寫效率和保護磁碟,使用了頁緩存機制。這樣造成讀文件時需要先將文件頁從磁碟拷貝到頁緩存中,由於頁緩存處在內核空間,不能被用戶進程直接定址,所以還需要將頁緩存中數據頁再次拷貝到記憶體對應的用戶空間中。這樣,通過了兩次數據拷貝過程,才能完成進程對文件內容的獲取任務。寫操作也是一樣,待寫入的buffer在內核空間不能直接訪問,必須要先拷貝至內核空間對應的主存,再寫回磁碟中(延遲寫回),也是需要兩次數據拷貝。
而使用mmap操作文件中,創建新的虛擬記憶體區域和建立文件磁碟地址和虛擬記憶體區域映射這兩步,沒有任何文件拷貝操作。而之後訪問數據時發現記憶體中並無數據而發起的缺頁異常過程,可以通過已經建立好的映射關係,只使用一次數據拷貝,就從磁碟中將數據傳入記憶體的用戶空間中,供進程使用。
總而言之,常規文件操作需要從磁碟到頁緩存再到用戶主存的兩次數據拷貝。而mmap操控文件,只需要從磁碟到用戶主存的一次數據拷貝過程。說白了,mmap的關鍵點是實現了用戶空間和內核空間的數據直接交互而省去了空間不同數據不通的繁瑣過程。因此mmap效率更高。
mmap優點總結
由上文討論可知,mmap優點共有一下幾點:
1、對文件的讀取操作跨過了頁緩存,減少了數據的拷貝次數,用記憶體讀寫取代I/O讀寫,提高了文件讀取效率。
2、實現了用戶空間和內核空間的高效交互方式。兩空間的各自修改操作可以直接反映在映射的區域內,從而被對方空間及時捕捉。
3、提供進程間共用記憶體及相互通信的方式。不管是父子進程還是無親緣關係的進程,都可以將自身用戶空間映射到同一個文件或匿名映射到同一片區域。從而通過各自對映射區域的改動,達到進程間通信和進程間共用的目的。
同時,如果進程A和進程B都映射了區域C,當A第一次讀取C時通過缺頁從磁碟複製文件頁到記憶體中;但當B再讀C的相同頁面時,雖然也會產生缺頁異常,但是不再需要從磁碟中複製文件過來,而可直接使用已經保存在記憶體中的文件數據。
4、可用於實現高效的大規模數據傳輸。記憶體空間不足,是制約大數據操作的一個方面,解決方案往往是藉助硬碟空間協助操作,補充記憶體的不足。但是進一步會造成大量的文件I/O操作,極大影響效率。這個問題可以通過mmap映射很好的解決。換句話說,但凡是需要用磁碟空間代替記憶體的時候,mmap都可以發揮其功效。
堆外記憶體之 DirectByteBuffer 詳解
原文出處: tomas家的小撥浪鼓
堆外記憶體
堆外記憶體是相對於堆內記憶體的一個概念。堆內記憶體是由JVM所管控的Java進程記憶體,我們平時在Java中創建的對象都處於堆內記憶體中,並且它們遵循JVM的記憶體管理機制,JVM會採用垃圾回收機制統一管理它們的記憶體。那麼堆外記憶體就是存在於JVM管控之外的一塊記憶體區域,因此它是不受JVM的管控。
在講解DirectByteBuffer之前,需要先簡單瞭解兩個知識點。
java引用類型,因為DirectByteBuffer是通過虛引用(Phantom Reference)來實現堆外記憶體的釋放的。
PhantomReference 是所有“弱引用”中最弱的引用類型。不同於軟引用和弱引用,虛引用無法通過 get() 方法來取得目標對象的強引用從而使用目標對象,觀察源碼可以發現 get() 被重寫為永遠返回 null。
那虛引用到底有什麼作用?其實虛引用主要被用來 跟蹤對象被垃圾回收的狀態,通過查看引用隊列中是否包含對象所對應的虛引用來判斷它是否 即將被垃圾回收,從而採取行動。它並不被期待用來取得目標對象的引用,而目標對象被回收前,它的引用會被放入一個 ReferenceQueue 對象中,從而達到跟蹤對象垃圾回收的作用。
關於java引用類型的實現和原理可以閱讀之前的文章Reference 、ReferenceQueue 詳解 和 Java 引用類型簡述。
關於linux的內核態和用戶態

- 內核態:控制電腦的硬體資源,並提供上層應用程式運行的環境。比如socket I/0操作或者文件的讀寫操作等
- 用戶態:上層應用程式的活動空間,應用程式的執行必須依托於內核提供的資源。
- 系統調用:為了使上層應用能夠訪問到這些資源,內核為上層應用提供訪問的介面。

因此我們可以得知當我們通過JNI調用的native方法實際上就是從用戶態切換到了內核態的一種方式。並且通過該系統調用使用操作系統所提供的功能。
Q:為什麼需要用戶進程(位於用戶態中)要通過系統調用(Java中即使JNI)來調用內核態中的資源,或者說調用操作系統的服務了?
A:intel cpu提供Ring0-Ring3四種級別的運行模式,Ring0級別最高,Ring3最低。Linux使用了Ring3級別運行用戶態,Ring0作為內核態。Ring3狀態不能訪問Ring0的地址空間,包括代碼和數據。因此用戶態是沒有許可權去操作內核態的資源的,它只能通過系統調用外完成用戶態到內核態的切換,然後在完成相關操作後再有內核態切換回用戶態。
DirectByteBuffer ———— 直接緩衝
DirectByteBuffer是Java用於實現堆外記憶體的一個重要類,我們可以通過該類實現堆外記憶體的創建、使用和銷毀。

DirectByteBuffer該類本身還是位於Java記憶體模型的堆中。堆內記憶體是JVM可以直接管控、操縱。
而DirectByteBuffer中的unsafe.allocateMemory(size);是個一個native方法,這個方法分配的是堆外記憶體,通過C的malloc來進行分配的。分配的記憶體是系統本地的記憶體,並不在Java的記憶體中,也不屬於JVM管控範圍,所以在DirectByteBuffer一定會存在某種方式來操縱堆外記憶體。
在DirectByteBuffer的父類Buffer中有個address屬性:
| 123 | // Used only by direct buffers``// NOTE: hoisted here for speed in JNI GetDirectBufferAddress``long address; |
|---|
address只會被直接緩存給使用到。之所以將address屬性升級放在Buffer中,是為了在JNI調用GetDirectBufferAddress時提升它調用的速率。
address表示分配的堆外記憶體的地址。

unsafe.allocateMemory(size);分配完堆外記憶體後就會返回分配的堆外記憶體基地址,並將這個地址賦值給了address屬性。這樣我們後面通過JNI對這個堆外記憶體操作時都是通過這個address來實現的了。
在前面我們說過,在linux中內核態的許可權是最高的,那麼在內核態的場景下,操作系統是可以訪問任何一個記憶體區域的,所以操作系統是可以訪問到Java堆的這個記憶體區域的。
Q:那為什麼操作系統不直接訪問Java堆內的記憶體區域了?
A:這是因為JNI方法訪問的記憶體區域是一個已經確定了的記憶體區域地質,那麼該記憶體地址指向的是Java堆內記憶體的話,那麼如果在操作系統正在訪問這個記憶體地址的時候,Java在這個時候進行了GC操作,而GC操作會涉及到數據的移動操作[GC經常會進行先標誌在壓縮的操作。即,將可回收的空間做標誌,然後清空標誌位置的記憶體,然後會進行一個壓縮,壓縮就會涉及到對象的移動,移動的目的是為了騰出一塊更加完整、連續的記憶體空間,以容納更大的新對象],數據的移動會使JNI調用的數據錯亂。所以JNI調用的記憶體是不能進行GC操作的。
Q:如上面所說,JNI調用的記憶體是不能進行GC操作的,那該如何解決了?
A:①堆內記憶體與堆外記憶體之間數據拷貝的方式(並且在將堆內記憶體拷貝到堆外記憶體的過程JVM會保證不會進行GC操作):比如我們要完成一個從文件中讀數據到堆內記憶體的操作,即FileChannelImpl.read(HeapByteBuffer)。這裡實際上File I/O會將數據讀到堆外記憶體中,然後堆外記憶體再講數據拷貝到堆內記憶體,這樣我們就讀到了文件中的記憶體。

| 12345678910111213141516171819202122232425262728 | static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {``if (var1.isReadOnly()) {``throw new IllegalArgumentException(``"Read-only buffer"``);``} else if (var1 instanceof DirectBuffer) {``return readIntoNativeBuffer(var0, var1, var2, var4);``} else {``// 分配臨時的堆外記憶體``ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());``int var7;``try {``// File I/O 操作會將數據讀入到堆外記憶體中``int var6 = readIntoNativeBuffer(var0, var5, var2, var4);``var5.flip();``if (var6 > 0``) {``// 將堆外記憶體的數據拷貝到堆外記憶體中``var1.put(var5);``}``var7 = var6;``} finally {``// 裡面會調用DirectBuffer.cleaner().clean()來釋放臨時的堆外記憶體``Util.offerFirstTemporaryDirectBuffer(var5);``}``return var7;``}``} |
|---|
而寫操作則反之,我們會將堆內記憶體的數據線寫到對堆外記憶體中,然後操作系統會將堆外記憶體的數據寫入到文件中。
② 直接使用堆外記憶體,如DirectByteBuffer:這種方式是直接在堆外分配一個記憶體(即,native memory)來存儲數據,程式通過JNI直接將數據讀/寫到堆外記憶體中。因為數據直接寫入到了堆外記憶體中,所以這種方式就不會再在JVM管控的堆內再分配記憶體來存儲數據了,也就不存在堆內記憶體和堆外記憶體數據拷貝的操作了。這樣在進行I/O操作時,只需要將這個堆外記憶體地址傳給JNI的I/O的函數就好了。
DirectByteBuffer堆外記憶體的創建和回收的源碼解讀
堆外記憶體分配
| 123456789101112131415161718192021222324252627 | DirectByteBuffer(``int cap) { // package-private``super``(-``1``, 0``, cap, cap);``boolean pa = VM.isDirectMemoryPageAligned();``int ps = Bits.pageSize();``long size = Math.max(1L, (``long``)cap + (pa ? ps : 0``));``// 保留總分配記憶體(按頁分配)的大小和實際記憶體的大小``Bits.reserveMemory(size, cap);``long base = 0``;``try {``// 通過unsafe.allocateMemory分配堆外記憶體,並返回堆外記憶體的基地址``base = unsafe.allocateMemory(size);``} catch (OutOfMemoryError x) {``Bits.unreserveMemory(size, cap);``throw x;``}``unsafe.setMemory(base, size, (``byte``) 0``);``if (pa && (base % ps != 0``)) {``// Round up to page boundary``address = base + ps - (base & (ps - 1``));``} else {``address = base;``}``// 構建Cleaner對象用於跟蹤DirectByteBuffer對象的垃圾回收,以實現當DirectByteBuffer被垃圾回收時,堆外記憶體也會被釋放``cleaner = Cleaner.create(``this``, new Deallocator(base, size, cap));``att = null``;``} |
|---|
Bits.reserveMemory(size, cap) 方法
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960 | static void reserveMemory(``long size, int cap) {``if (!memoryLimitSet && VM.isBooted()) {``maxMemory = VM.maxDirectMemory();``memoryLimitSet = true``;``}``// optimist!``if (tryReserveMemory(size, cap)) {``return``;``}``final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();``// retry while helping enqueue pending Reference objects``// which includes executing pending Cleaner(s) which includes``// Cleaner(s) that free direct buffer memory``while (jlra.tryHandlePendingReference()) {``if (tryReserveMemory(size, cap)) {``return``;``}``}``// trigger VM's Reference processing``System.gc();``// a retry loop with exponential back-off delays``// (this gives VM some time to do it's job)``boolean interrupted = false``;``try {``long sleepTime = 1``;``int sleeps = 0``;``while (``true``) {``if (tryReserveMemory(size, cap)) {``return``;``}``if (sleeps >= MAX_SLEEPS) {``break``;``}``if (!jlra.tryHandlePendingReference()) {``try {``Thread.sleep(sleepTime);``sleepTime <<= 1``;``sleeps++;``} catch (InterruptedException e) {``interrupted = true``;``}``}``}``// no luck``throw new OutOfMemoryError(``"Direct buffer memory"``);``} finally {``if (interrupted) {``// don't swallow interrupts``Thread.currentThread().interrupt();``}``}``} |
|---|
該方法用於在系統中保存總分配記憶體(按頁分配)的大小和實際記憶體的大小。
其中,如果系統中記憶體( 即,堆外記憶體 )不夠的話:
| 12345678910 | final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();``// retry while helping enqueue pending Reference objects``// which includes executing pending Cleaner(s) which includes``// Cleaner(s) that free direct buffer memory``while (jlra.tryHandlePendingReference()) {``if (tryReserveMemory(size, cap)) {``return``;``}``} |
|---|
jlra.tryHandlePendingReference()會觸發一次非堵塞的Reference#tryHandlePending(false)。該方法會將已經被JVM垃圾回收的DirectBuffer對象的堆外記憶體釋放。
因為在Reference的靜態代碼塊中定義了:
| 123456 | SharedSecrets.setJavaLangRefAccess(``new JavaLangRefAccess() {``@Override``public boolean tryHandlePendingReference() {``return tryHandlePending(``false``);``}``}); |
|---|
如果在進行一次堆外記憶體資源回收後,還不夠進行本次堆外記憶體分配的話,則
| 12 | // trigger VM's Reference processing``System.gc(); |
|---|
System.gc()會觸發一個full gc,當然前提是你沒有顯示的設置-XX:+DisableExplicitGC來禁用顯式GC。並且你需要知道,調用System.gc()並不能夠保證full gc馬上就能被執行。
所以在後面打代碼中,會進行最多9次嘗試,看是否有足夠的可用堆外記憶體來分配堆外記憶體。並且每次嘗試之前,都對延遲等待時間,已給JVM足夠的時間去完成full gc操作。如果9次嘗試後依舊沒有足夠的可用堆外記憶體來分配本次堆外記憶體,則拋出OutOfMemoryError(“Direct buffer memory”)異常。

註意,這裡之所以用使用full gc的很重要的一個原因是:System.gc()會對新生代的老生代都會進行記憶體回收,這樣會比較徹底地回收DirectByteBuffer對象以及他們關聯的堆外記憶體.
DirectByteBuffer對象本身其實是很小的,但是它後面可能關聯了一個非常大的堆外記憶體,因此我們通常稱之為冰山對象.
我們做ygc的時候會將新生代里的不可達的DirectByteBuffer對象及其堆外記憶體回收了,但是無法對old里的DirectByteBuffer對象及其堆外記憶體進行回收,這也是我們通常碰到的最大的問題。( 並且堆外記憶體多用於生命期中等或較長的對象 )
如果有大量的DirectByteBuffer對象移到了old,但是又一直沒有做cms gc或者full gc,而只進行ygc,那麼我們的物理記憶體可能被慢慢耗光,但是我們還不知道發生了什麼,因為heap明明剩餘的記憶體還很多(前提是我們禁用了System.gc – JVM參數DisableExplicitGC)。
總的來說,Bits.reserveMemory(size, cap)方法在可用堆外記憶體不足以分配給當前要創建的堆外記憶體大小時,會實現以下的步驟來嘗試完成本次堆外記憶體的創建:
① 觸發一次非堵塞的Reference#tryHandlePending(false)。該方法會將已經被JVM垃圾回收的DirectBuffer對象的堆外記憶體釋放。
② 如果進行一次堆外記憶體資源回收後,還不夠進行本次堆外記憶體分配的話,則進行 System.gc()。System.gc()會觸發一個full gc,但你需要知道,調用System.gc()並不能夠保證full gc馬上就能被執行。所以在後面打代碼中,會進行最多9次嘗試,看是否有足夠的可用堆外記憶體來分配堆外記憶體。並且每次嘗試之前,都對延遲等待時間,已給JVM足夠的時間去完成full gc操作。
註意,如果你設置了-XX:+DisableExplicitGC,將會禁用顯示GC,這會使System.gc()調用無效。
③ 如果9次嘗試後依舊沒有足夠的可用堆外記憶體來分配本次堆外記憶體,則拋出OutOfMemoryError(“Direct buffer memory”)異常。
那麼可用堆外記憶體到底是多少了?,即預設堆外存記憶體有多大:
① 如果我們沒有通過-XX:MaxDirectMemorySize來指定最大的堆外記憶體。則
② 如果我們沒通過-Dsun.nio.MaxDirectMemorySize指定了這個屬性,且它不等於-1。則
③ 那麼最大堆外記憶體的值來自於directMemory = Runtime.getRuntime().maxMemory(),這是一個native方法
| 1234567891011 | JNIEXPORT jlong JNICALL``Java_java_lang_Runtime_maxMemory(JNIEnv *env, jobject this``)``{``return JVM_MaxMemory();``}``JVM_ENTRY_NO_ENV(jlong, JVM_MaxMemory(``void``))``JVMWrapper(``"JVM_MaxMemory"``);``size_t n = Universe::heap()->max_capacity();``return convert_size_t_to_jlong(n);``JVM_END |
|---|
其中在我們使用CMS GC的情況下也就是我們設置的-Xmx的值里除去一個survivor的大小就是預設的堆外記憶體的大小了。
堆外記憶體回收
Cleaner是PhantomReference的子類,並通過自身的next和prev欄位維護的一個雙向鏈表。PhantomReference的作用在於跟蹤垃圾回收過程,並不會對對象的垃圾回收過程造成任何的影響。
所以cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); 用於對當前構造的DirectByteBuffer對象的垃圾回收過程進行跟蹤。
當DirectByteBuffer對象從pending狀態 ——> enqueue狀態時,會觸發Cleaner的clean(),而Cleaner的clean()的方法會實現通過unsafe對堆外記憶體的釋放。


雖然Cleaner不會調用到Reference.clear(),但Cleaner的clean()方法調用了remove(this),即將當前Cleaner從Cleaner鏈表中移除,這樣當clean()執行完後,Cleaner就是一個無引用指向的對象了,也就是可被GC回收的對象。
thunk方法:

通過配置參數的方式來回收堆外記憶體
同時我們可以通過-XX:MaxDirectMemorySize來指定最大的堆外記憶體大小,當使用達到了閾值的時候將調用System.gc()來做一次full gc,以此來回收掉沒有被使用的堆外記憶體。
堆外記憶體那些事
使用堆外記憶體的原因
- 對垃圾回收停頓的改善
因為full gc 意味著徹底回收,徹底回收時,垃圾收集器會對所有分配的堆內記憶體進行完整的掃描,這意味著一個重要的事實——這樣一次垃圾收集對Java應用造成的影響,跟堆的大小是成正比的。過大的堆會影響Java應用的性能。如果使用堆外記憶體的話,堆外記憶體是直接受操作系統管理( 而不是虛擬機 )。這樣做的結果就是能保持一個較小的堆內記憶體,以減少垃圾收集對應用的影響。
- 在某些場景下可以提升程式I/O操縱的性能。少去了將數據從堆內記憶體拷貝到堆外記憶體的步驟。
什麼情況下使用堆外記憶體
- 堆外記憶體適用於生命周期中等或較長的對象。( 如果是生命周期較短的對象,在YGC的時候就被回收了,就不存在大記憶體且生命周期較長的對象在FGC對應用造成的性能影響 )。
- 直接的文件拷貝操作,或者I/O操作。直接使用堆外記憶體就能少去記憶體從用戶記憶體拷貝到系統記憶體的操作,因為I/O操作是系統內核記憶體和設備間的通信,而不是通過程式直接和外設通信的。
- 同時,還可以使用 池+堆外記憶體 的組合方式,來對生命周期較短,但涉及到I/O操作的對象進行堆外記憶體的再使用。( Netty中就使用了該方式 )
堆外記憶體 VS 記憶體池
- 記憶體池:主要用於兩類對象:①生命周期較短,且結構簡單的對象,在記憶體池中重覆利用這些對象能增加CPU緩存的命中率,從而提高性能;②載入含有大量重覆對象的大片數據,此時使用記憶體池能減少垃圾回收的時間。
- 堆外記憶體:它和記憶體池一樣,也能縮短垃圾回收時間,但是它適用的對象和記憶體池完全相反。記憶體池往往適用於生命期較短的可變對象,而生命期中等或較長的對象,正是堆外記憶體要解決的。
堆外記憶體的特點
- 對於大記憶體有良好的伸縮性
- 對垃圾回收停頓的改善可以明顯感覺到
- 在進程間可以共用,減少虛擬機間的複製
堆外記憶體的一些問題
- 堆外記憶體回收問題,以及堆外記憶體的泄漏問題。這個在上面的源碼解析已經提到了
- 堆外記憶體的數據結構問題:堆外記憶體最大的問題就是你的數據結構變得不那麼直觀,如果數據結構比較複雜,就要對它進行串列化(serialization),而串列化本身也會影響性能。另一個問題是由於你可以使用更大的記憶體,你可能開始擔心虛擬記憶體(即硬碟)的速度對你的影響了。
參考
- http://lovestblog.cn/blog/2015/05/12/direct-buffer/
- http://www.infoq.com/cn/news/2014/12/external-memory-heap-memory
- http://www.jianshu.com/p/85e931636f27
- 聖思園《併發與Netty》課程
微信公眾號【Java技術江湖】一位阿裡 Java 工程師的技術小站。(關註公眾號後回覆”Java“即可領取 Java基礎、進階、項目和架構師等免費學習資料,更有資料庫、分散式、微服務等熱門技術學習視頻,內容豐富,兼顧原理和實踐,另外也將贈送作者原創的Java學習指南、Java程式員面試指南等乾貨資源)




