
對於集合框架,是非常重要的知識,是程式員必須要知道的知識點。 但是我們為什麼要引入集合框架呢? 我們之前用過數組存儲數據,但是採用數組存儲存在了很多的缺陷。而現在我們引用了集合框架,可以完全彌補了數組的缺陷。它靈活,使用,提高軟體的開發效率。並且不同的集合適用於不同的場合。 集合框架的好處: 1.容 ...
對於集合框架,是非常重要的知識,是程式員必須要知道的知識點。
但是我們為什麼要引入集合框架呢?
我們之前用過數組存儲數據,但是採用數組存儲存在了很多的缺陷。而現在我們引用了集合框架,可以完全彌補了數組的缺陷。它靈活,使用,提高軟體的開發效率。並且不同的集合適用於不同的場合。
集合框架的好處:
1.容量自增長;
2. 提供有用的數據結構和演算法,從而減少編程工作;
3. 提高了程式速度和質量,因為它提供了高性能的數據結構和演算法;
4. 允許不同 API 之間的互操作,API之間可以來回傳遞集合;
5. 可以方便地擴展或改寫集合。
集合框架是為表示和操作集合而規定的一種統一的標準的體繫結構。
任何集合框架都包含三大塊內容:對外的介面、介面的實現和對集合運算的演算法。
介面:即表示集合的抽象數據類型。介面提供了讓我們對集合中所表示的內容進行單獨操作的可能。
實現:也就是集合框架中介面的具體實現。實際它們就是那些可復用的數據結構。
演算法:在一個實現了某個集合框架中的介面的對象身上完成某種有用的計算的方法,例如查找、排序等。這些演算法通常是多態的,因為相同的方法可以在同一個介面被多個類實現時有不同的表現。
事實上,演算法是可復用的函數。
它減少了程式設計的辛勞。
集合框架通過提供有用的數據結構和演算法使你能集中註意力於你的程式的重要部分上,而不是為了讓程式能正常運轉而將註意力於低層設計上。
通過這些在無關API之間的簡易的互用性,使你免除了為改編對象或轉換代碼以便聯合這些API而去寫大量的代碼。 它提高了程式速度和質量。
集合框架通過提供對有用的數據結構和演算法的高性能和高質量的實現使你的程式速度和質量得到提高。因為每個介面的實現是可互換的,所以你的程式可以很容易的通過改變一個實現而進行調整。
另外,你將可以從寫你自己的數據結構的苦差事中解脫出來,從而有更多時間關註於程式其它部分的質量和性能。
減少去學習和使用新的API 的辛勞。 許多API天生的有對集合的存儲和獲取。
在過去,這樣的API都有一些子API幫助操縱它的集合內容,因此在那些特殊的子API之間就會缺乏一致性,你也不得不從零開始學習,並且在使用時也很容易犯錯。而標準集合框架介面的出現使這個問題迎刃而解。
減少了設計新API的努力。 設計者和實現者不用再在每次創建一種依賴於集合內容的API時重新設計,他們只要使用標準集合框架的介面即可。 集合框架鼓勵軟體的復用。 對於遵照標準集合框架介面的新的數據結構天生即是可復用的。
同樣對於操作一個實現了這些介面的對象的演算法也是如此。 有了這些優點,並通過合理的使用,它就會成為程式員的一種強大的工具。不過,從歷史上來看,集合大多其結構相當複雜,也就給它們一個造成極不合理的學習曲線的壞名聲。
但是,希望Java2的集合框架能縮短你的學習曲線,從而快速掌握它
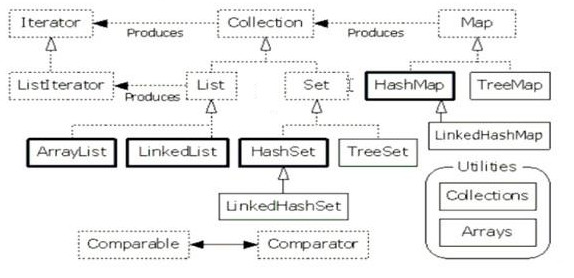
現在我們瞭解集合框架的內容簡圖:
從該簡圖可以看出:
java集合介面
Java中集合類定義主要是java.util.*包下麵,常用的集合在系統中定義了三大介面,這三類的區別是:
java.util.Set介面及其子類,set提供的是一個無序的集合;
java.util.List介面及其子類,List提供的是一個有序的集合;
java.util.Map介面及其子類,Map提供了一個映射(對應)關係的集合數據結構;
另外,在JDK5中新增了Queue(隊列)介面及其子類,提供了基於隊列的集合體系。每種集合,都可以理解為用來在記憶體中存放一組對象的某種”容器“---就像數組,就像前面我們自己定義的隊列。


Collection介面
Collection介面是所有集合介面的基類,提供了集合介面的通用操作
public interface Collection<E> extends Iterable<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
通過這些操作函數,我們可以進行獲取集合中元素的個數 (size, isEmpty),判斷集合中是否包含某個元素(contains),在集合中增加或刪除元素(add, remove),獲取訪問迭代器(iterator)等操作。
迭代器
迭代器(Iterator)可以用來遍歷集合併對集合中的元素進行刪操作。 可以通過集合的iterator 函數獲取該集合的迭代器。 Iterator介面如下所示:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove(); //optional
}
當集合中還有元素供迭代器訪問時,hasNext函數返回true。此時,可以通過next函數返回集合中的下一個元素。 函數remove刪除next()最後一次從集合中訪問的元素。
註意:Iterator.remove是在迭代過程中修改collection的唯一安全的方法,在迭代期間不允許使用其它的方法對collection進行操作。
Collection的批量操作
集合的批量操作介面函數如下:
containsAll— 檢查集合中是否包含指定集合addAll— 在集合中加入指定集合removeAll— 在集合中刪除包含於指定集合的元素retainAll—刪除集合中不包含於指定集合的元素clear— 刪除集合中所有元素
在addAll, removeAll及 retainAll 操作中,如果集合的元素被更改,則返回true。
Set介面
Set 是一個不包含重覆元素的集合(Collection)。Set介面中的函數都是從Collection繼承而來。 但限制了add 的使用,需要其不能添加重覆元素。
Set介面聲明如下:
public interface Set<E> extends Collection<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array Operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
Set介面批量操作
Set的批量操作和離散數學的集合操作的概論結合的非常好,假如s1和s2是兩個Set,它們間的批量操作如下:
s1.containsAll(s2) — 判斷s2是否是s1的子集
s1.addAll(s2) —將s1轉化為s1和s2的並集
s1.retainAll(s2)—將s1轉化為s1和s2的交集
s1.removeAll(s2) —將s1轉化為s1和s2的差集
List介面
List是一個順序的Collection(通常被稱作序列)。List可以包含重覆元素。List介面基本功能如下:
按位置訪問 — 通過元素在list中的位置索引訪問元素。
查詢 — 獲取某元素在list中的位置
迭代 — 擴展了Iterator的介面能實現更多功能
List子集合 — 獲取List某個位置範圍的子集合
List介面如下:
List 介面繼承了 Collection 介面以定義一個允許重覆項的有序集合。該介面不但能夠對列表的一部分進行處理,還添加了面向位置的操作。
(1) 面向位置的操作包括插入某個元素或 Collection 的功能,還包括獲取、除去或更改元素的功能。在 List 中搜索元素可以從列表的頭部或尾部開始,如果找到元素,還將報告元素所在的位置 :
void add(int index, Object element): 在指定位置index上添加元素element
boolean addAll(int index, Collection c): 將集合c的所有元素添加到指定位置index
Object get(int index): 返回List中指定位置的元素
int indexOf(Object o): 返回第一個出現元素o的位置,否則返回-1
int lastIndexOf(Object o) :返回最後一個出現元素o的位置,否則返回-1
Object remove(int index) :刪除指定位置上的元素
Object set(int index, Object element) :用元素element取代位置index上的元素,並且返回舊的元素
(2) List 介面不但以位置序列迭代的遍歷整個列表,還能處理集合的子集:
ListIterator listIterator() : 返回一個列表迭代器,用來訪問列表中的元素
ListIterator listIterator(int index) : 返回一個列表迭代器,用來從指定位置index開始訪問列表中的元素
List subList(int fromIndex, int toIndex) :返回從指定位置fromIndex(包含)到toIndex(不包含)範圍中各個元素的列表視圖
“對子列表的更改(如 add()、remove() 和 set() 調用)對底層 List 也有影響。”
2.1.ListIterator介面
ListIterator 介面繼承 Iterator 介面以支持添加或更改底層集合中的元素,還支持雙向訪問。ListIterator沒有當前位置,游標位於調用previous和next方法返回的值之間。一個長度為n的列表,有n+1個有效索引值:
(1) void add(Object o): 將對象o添加到當前位置的前面
void set(Object o): 用對象o替代next或previous方法訪問的上一個元素。如果上次調用後列表結構被修改了,那麼將拋出IllegalStateException異常。
(2) boolean hasPrevious(): 判斷向後迭代時是否有元素可訪問
Object previous():返回上一個對象
int nextIndex(): 返回下次調用next方法時將返回的元素的索引
int previousIndex(): 返回下次調用previous方法時將返回的元素的索引
“正常情況下,不用ListIterator改變某次遍歷集合元素的方向 — 向前或者向後。雖然在技術上可以實現,但previous() 後立刻調用next(),返回的是同一個元素。把調用 next()和previous()的順序顛倒一下,結果相同。”
“我們還需要稍微再解釋一下 add() 操作。添加一個元素會導致新元素立刻被添加到隱式游標的前面。因此,添加元素後調用 previous() 會返回新元素,而調用 next() 則不起作用,返回添加操作之前的下一個元素。”
2.2.AbstractList和AbstractSequentialList抽象類
有兩個抽象的 List 實現類:AbstractList 和 AbstractSequentialList。像 AbstractSet 類一樣,它們覆蓋了 equals() 和 hashCode() 方法以確保兩個相等的集合返回相同的哈希碼。若兩個列表大小相等且包含順序相同的相同元素,則這兩個列表相等。這裡的 hashCode() 實現在 List 介面定義中指定,而在這裡實現。
除了equals()和hashCode(),AbstractList和AbstractSequentialList實現了其餘 List 方法的一部分。因為數據的隨機訪問和順序訪問是分別實現的,使得具體列表實現的創建更為容易。需要定義的一套方法取決於您希望支持的行為。您永遠不必親自提供的是 iterator方法的實現。
2.3. LinkedList類和ArrayList類
在“集合框架”中有兩種常規的 List 實現:ArrayList 和 LinkedList。使用兩種 List 實現的哪一種取決於您特定的需要。如果要支持隨機訪問,而不必在除尾部的任何位置插入或除去元素,那麼,ArrayList 提供了可選的集合。但如果,您要頻繁的從列表的中間位置添加和除去元素,而只要順序的訪問列表元素,那麼,LinkedList 實現更好。
“ArrayList 和 LinkedList 都實現 Cloneable 介面,都提供了兩個構造函數,一個無參的,一個接受另一個Collection”
2.3.1. LinkedList類
LinkedList類添加了一些處理列表兩端元素的方法。
(1) void addFirst(Object o): 將對象o添加到列表的開頭
void addLast(Object o):將對象o添加到列表的結尾
(2) Object getFirst(): 返回列表開頭的元素
Object getLast(): 返回列表結尾的元素
(3) Object removeFirst(): 刪除並且返回列表開頭的元素
Object removeLast():刪除並且返回列表結尾的元素
(4) LinkedList(): 構建一個空的鏈接列表
LinkedList(Collection c): 構建一個鏈接列表,並且添加集合c的所有元素
“使用這些新方法,您就可以輕鬆的把 LinkedList 當作一個堆棧、隊列或其它面向端點的數據結構。”
LinkedList<Dog> list=new LinkedList<Dog>();//LinkedList list=new LinkedList()是一樣的 //============用add(object o)方法,總是在尾部添加 list.add(dog); list.add(dog1); list.addLast(dog2);//最後一個位置 list.addFirst(dog3);//第一個位置 //查看集合中第一條狗狗的信息==========getFirst()方法 Dog dgfirst= (Dog) list.getFirst(); System.out.println("第一條狗狗的大名是"+dgfirst.getName()); //查看集合中最後一條狗狗的信息===getLast()方法 Dog dglast= (Dog) list.getLast(); System.out.println("最後一條狗狗的大名是"+dglast.getName()); //刪除第一條狗狗的信息 Dog refirst= (Dog) list.removeFirst(); System.out.println("刪除第一條"+refirst.getName()); Dog relast= (Dog) list.removeLast(); System.out.println("刪除最後一條"+relast.getName()); System.out.println("\n刪除之後還有"+list.size()+"條狗狗"); for (int i = 0; i <list.size(); i++) { Dog dogall=(Dog) list.get(i); System.out.println(dogall.getName()+"\t\t"+dogall.getStrain()); } //判斷集合中是否包含集合中某指定的信息=============用contains(object o)方法 if (list.contains(dog3)) { System.out.println("集合中包含"+dog3.getName()+"的信息"); } else { System.out.println("集合中不包含"+dog3.getName()+"的信息"); }
2.3.2. ArrayList類
ArrayList類封裝了一個動態再分配的Object[]數組。每個ArrayList對象有一個capacity。這個capacity表示存儲列表中元素的數組的容量。當元素添加到ArrayList時,它的capacity在常量時間內自動增加。
在向一個ArrayList對象添加大量元素的程式中,可使用ensureCapacity方法增加capacity。這可以減少增加重分配的數量。
(1) void ensureCapacity(int minCapacity): 將ArrayList對象容量增加minCapacity
(2) void trimToSize(): 整理ArrayList對象容量為列表當前大小。程式可使用這個操作減少ArrayList對象存儲空間。
2.3.2.1. RandomAccess介面
一個特征介面。該介面沒有任何方法,不過你可以使用該介面來測試某個集合是否支持有效的隨機訪問。ArrayList和Vector類用於實現該介面。
List<Dog> list=new ArrayList<Dog>();// List list=new ArrayList()是一樣的 //============用add(object o)方法,總是在尾部添加 list.add(dog); list.add(dog1); list.add(dog2); list.add(dog3); /** * 添加某元素到某指定任何位置的做法 * * list.add(int index,Object o) * list.add(2,dog3);//添加dog3到指定位置 */ //獲取集合中狗狗的數量===============用size()方法 System.out.println("共計有"+list.size()+"條狗狗"); //通過遍歷集合顯示狗狗的信息===============用get(int index)方法 System.out.println("分別是:"); for (int i = 0; i <list.size(); i++) { Dog dogall=(Dog) list.get(i); System.out.println(dogall.getName()+"\t\t"+dogall.getStrain()); } System.out.println("刪除之前共計有"+list.size()+"條狗狗"); //刪除集合中某指定位置的狗狗==================用remove(int index) 或 remove(Object o)方法 //方法中寫索引或對象都可以 list.remove(0); list.remove(dog2); System.out.println("\n刪除之後還有"+list.size()+"條狗狗"); for (int i = 0; i <list.size(); i++) { Dog dogall=(Dog) list.get(i); System.out.println(dogall.getName()+"\t\t"+dogall.getStrain()); }Map介面,HashMap類的常用方法
void clear()
從此映射中移除所有映射關係(可選操作)。
boolean containsKey(Object key)
如果此映射包含指定鍵的映射關係,則返回 true。
boolean containsValue(Object value)
如果此映射為指定值映射一個或多個鍵,則返回 true。
Set<Map.Entry<K,V>> entrySet()
返回此映射中包含的映射關係的 set 視圖。
boolean equals(Object o)
比較指定的對象與此映射是否相等。
V get(Object key)
返回此映射中映射到指定鍵的值。
int hashCode()
返回此映射的哈希碼值。
boolean isEmpty()
如果此映射未包含鍵-值映射關係,則返回 true。
Set<K> keySet()
返回此映射中包含的鍵的 set 視圖。
V put(K key, V value)
將指定的值與此映射中的指定鍵相關聯(可選操作)。
void putAll(Map<? extends K,? extends V> t)
從指定映射中將所有映射關係複製到此映射中(可選操作)。
V remove(Object key)
如果存在此鍵的映射關係,則將其從映射中移除(可選操作)。
int size()
返回此映射中的鍵-值映射關係數。
Collection<V> values()
返回此映射中包含的值的 collection 視圖。
Iterator迭代器
(1) 使用方法iterator()要求容器返回一個Iterator。第一次調用Iterator的next()方法時,它返回序列的第一個元素。註意:iterator()方法是java.lang.Iterable介面,被Collection繼承。
(2) 使用next()獲得序列中的下一個元素。
(3) 使用hasNext()檢查序列中是否還有元素。
(4) 使用remove()將迭代器新返回的元素刪除。
Iterator是Java迭代器最簡單的實現,為List設計的ListIterator具有更多的功能,它可以從兩個方向遍歷List,也可以從List中插入和刪除元素。
Iterator模式有三個重要的作用:
1)它支持以不同的方式遍歷一個聚合 複雜的聚合可用多種方式進行遍歷,如二叉樹的遍歷,可以採用前序、中序或後序遍歷。迭代器模式使得改變遍歷演算法變得很容易: 僅需用一個不同的迭代器的實例代替原先的實例即可,你也可以自己定義迭代器的子類以支持新的遍歷,或者可以在遍歷中增加一些邏輯,如有條件的遍歷等。
2)迭代器簡化了聚合的介面 有了迭代器的遍歷介面,聚合本身就不再需要類似的遍歷介面了,這樣就簡化了聚合的介面。
3)在同一個聚合上可以有多個遍歷 每個迭代器保持它自己的遍歷狀態,因此你可以同時進行多個遍歷。
4)此外,Iterator模式可以為遍歷不同的聚合結構(需擁有相同的基類)提供一個統一的介面,即支持多態迭代。
簡 單說來,迭代器模式也是Delegate原則的一個應用,它將對集合進行遍歷的功能封裝成獨立的Iterator,不但簡化了集合的介面,也使得修改、增 加遍歷方式變得簡單。從這一點講,該模式與Bridge模式、Strategy模式有一定的相似性,但Iterator模式所討論的問題與集合密切相關, 造成在Iterator在實現上具有一定的特殊性,具體將在示例部分進行討論。
正如前面所說,與集合密切相關,限制了 Iterator模式的廣泛使用。在一般的底層集合支持類中,我們往往不願“避輕就重”將集合設計成集合 + Iterator 的形式,而是將遍歷的功能直接交由集合完成,以免犯了“過度設計”的詬病,但是,如果我們的集合類確實需要支持多種遍歷方式(僅此一點仍不一定需要考慮 Iterator模式,直接交由集合完成往往更方便),或者,為了與系統提供或使用的其它機制,如STL演算法,保持一致時,Iterator模式才值得考 慮。
Iterator遍歷
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ArrayTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
System.out.println("用for迴圈遍歷");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("用增強for迴圈");
for (Integer i : list) {
System.out.println(i);
}
System.out.println("用iterator+while");
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
int i = (Integer) it.next();
System.out.println(i);
}
System.out.println("用iterator+for");
for (Iterator<Integer> iter = list.iterator(); iter.hasNext();) {
int i = (Integer) iter.next();
System.out.println(i);
}
}
}
泛型集合
泛型(Generic type 或者 generics)是對 Java 語言的類型系統的一種擴展,以支持創建可以按類型進行參數化的類。可以把類型參數看作是使用參數化類型時指定的類型的一個占位符,就像方法的形式參數是運行時傳遞的值的占位符一樣。 可以在集合框架(Collection framework)中看到泛型的動機。例如,Map 類允許您向一個 Map 添加任意類的對象,即使最常見的情況是在給定映射(map)中保存某個特定類型(比如 String)的對象。 因為 Map.get() 被定義為返回 Object,所以一般必須將 Map.get() 的結果強制類型轉換為期望的類型,如下麵的代碼所示: Map m = new HashMap(); m.put("key", "blarg"); String s = (String) m.get("key"); 要讓程式通過編譯,必須將 get() 的結果強制類型轉換為 String
泛型(Generic type 或者 generics)是對 Java 語言的類型系統的一種擴展,以支持創建可以按類型進行參數化的類。可以把類型參數看作是使用參數化類型時指定的類型的一個占位符,就像方法的形式參數是運行時傳遞的值的占位符一樣。
可以在集合框架(Collection framework)中看到泛型的動機。例如,Map 類允許您向一個 Map 添加任意類的對象,即使最常見的情況是在給定映射(map)中保存某個特定類型(比如 String)的對象。
因為 Map.get() 被定義為返回 Object,所以一般必須將 Map.get() 的結果強制類型轉換為期望的類型,如下麵的代碼所示:
Map m = new HashMap();
m.put("key", "blarg");
String s = (String) m.get("key");
要讓程式通過編譯,必須將 get() 的結果強制類型轉換為 String,並且希望結果真的是一個 String。但是有可能某人已經在該映射中保存了不是 String 的東西,這樣的話,上面的代碼將會拋出 ClassCastException。
理想情況下,您可能會得出這樣一個觀點,即 m 是一個 Map,它將 String 鍵映射到 String 值。這可以讓您消除代碼中的強制類型轉換,同時獲得一個附加的類型檢查層,該檢查層可以防止有人將錯誤類型的鍵或值保存在集合中。這就是泛型所做的工作。
泛型的好處
Java 語言中引入泛型是一個較大的功能增強。不僅語言、類型系統和編譯器有了較大的變化,以支持泛型,而且類庫也進行了大翻修,所以許多重要的類,比如集合框架,都已經成為泛型化的了。這帶來了很多好處:
類型安全。 泛型的主要目標是提高 Java 程式的類型安全。通過知道使用泛型定義的變數的類型限制,編譯器可以在一個高得多的程度上驗證類型假設。沒有泛型,這些假設就只存在於程式員的頭腦中(或者如果幸運的話,還存在於代碼註釋中)。
Java 程式中的一種流行技術是定義這樣的集合,即它的元素或鍵是公共類型的,比如“String 列表”或者“String 到 String 的映射”。通過在變數聲明中捕獲這一附加的類型信息,泛型允許編譯器實施這些附加的類型約束。類型錯誤現在就可以在編譯時被捕獲了,而不是在運行時當作 ClassCastException 展示出來。將類型檢查從運行時挪到編譯時有助於您更容易找到錯誤,並可提高程式的可靠性。
消除強制類型轉換。 泛型的一個附帶好處是,消除源代碼中的許多強制類型轉換。這使得代碼更加可讀,並且減少了出錯機會。
儘管減少強制類型轉換可以降低使用泛型類的代碼的羅嗦程度,但是聲明泛型變數會帶來相應的羅嗦。比較下麵兩個代碼例子。
該代碼不使用泛型:
List li = new ArrayList();
li.put(new Integer(3));
Integer i = (Integer) li.get(0);
該代碼使用泛型:
List<Integer> li = new ArrayList<Integer>();
li.put(new Integer(3));
Integer i = li.get(0);
在簡單的程式中使用一次泛型變數不會降低羅嗦程度。但是對於多次使用泛型變數的大型程式來說,則可以累積起來降低羅嗦程度。
潛在的性能收益。 泛型為較大的優化帶來可能。在泛型的初始實現中,編譯器將強制類型轉換(沒有泛型的話,程式員會指定這些強制類型轉換)插入生成的位元組碼中。但是更多類型信息可用於編譯器這一事實,為未來版本的 JVM 的優化帶來可能。
由於泛型的實現方式,支持泛型(幾乎)不需要 JVM 或類文件更改。所有工作都在編譯器中完成,編譯器生成類似於沒有泛型(和強制類型轉換)時所寫的代碼,只是更能確保類型安全而已。
泛型用法的例子
泛型的許多最佳例子都來自集合框架,因為泛型讓您在保存在集合中的元素上指定類型約束。考慮這個使用 Map 類的例子,其中涉及一定程度的優化,即 Map.get() 返回的結果將確實是一個 String:
Map m = new HashMap();
m.put("key", "blarg");
String s = (String) m.get("key");
如果有人已經在映射中放置了不是 String 的其他東西,上面的代碼將會拋出 ClassCastException。泛型允許您表達這樣的類型約束,即 m 是一個將 String 鍵映射到 String 值的 Map。這可以消除代碼中的強制類型轉換,同時獲得一個附加的類型檢查層,這個檢查層可以防止有人將錯誤類型的鍵或值保存在集合中。
下麵的代碼示例展示了 JDK 5.0 中集合框架中的 Map 介面的定義的一部分:
public interface Map<K, V> {
public void put(K key, V value);
public V get(K key);
}
註意該介面的兩個附加物:
類型參數 K 和 V 在類級別的規格說明,表示在聲明一個 Map 類型的變數時指定的類型的占位符。
在 get()、put() 和其他方法的方法簽名中使用的 K 和 V。
為了贏得使用泛型的好處,必須在定義或實例化 Map 類型的變數時為 K 和 V 提供具體的值。以一種相對直觀的方式做這件事:
Map<String, String> m = new HashMap<String, String>();
m.put("key", "blarg");
String s = m.get("key");
當使用 Map 的泛型化版本時,您不再需要將 Map.get() 的結果強制類型轉換為 String,因為編譯器知道 get() 將返回一個 String。
在使用泛型的版本中並沒有減少鍵盤錄入;實際上,比使用強制類型轉換的版本需要做更多鍵入。使用泛型只是帶來了附加的類型安全。因為編譯器知道關於您將放進 Map 中的鍵和值的類型的更多信息,所以類型檢查從執行時挪到了編譯時,這會提高可靠性並加快開發速度。
向後相容
在 Java 語言中引入泛型的一個重要目標就是維護向後相容。儘管 JDK 5.0 的標準類庫中的許多類,比如集合框架,都已經泛型化了,但是使用集合類(比如 HashMap 和 ArrayList)的現有代碼將繼續不加修改地在 JDK 5.0 中工作。當然,沒有利用泛型的現有代碼將不會贏得泛型的類型安全好處。
二 泛型基礎
類型參數
在定義泛型類或聲明泛型類的變數時,使用尖括弧來指定形式類型參數。形式類型參數與實際類型參數之間的關係類似於形式方法參數與實際方法參數之間的關係,只是類型參數表示類型,而不是表示值。
泛型類中的類型參數幾乎可以用於任何可以使用類名的地方。例如,下麵是 java.util.Map 介面的定義的摘錄:
public interface Map<K, V> {
public void put(K key, V value);
public V get(K key);
}
Map 介面是由兩個類型參數化的,這兩個類型是鍵類型 K 和值類型 V。(不使用泛型)將會接受或返回 Object 的方法現在在它們的方法簽名中使用 K 或 V,指示附加的類型約束位於 Map 的規格說明之下。
當聲明或者實例化一個泛型的對象時,必須指定類型參數的值:
Map<String, String> map = new HashMap<String, String>();
註意,在本例中,必須指定兩次類型參數。一次是在聲明變數 map 的類型時,另一次是在選擇 HashMap 類的參數化以便可以實例化正確類型的一個實例時。
編譯器在遇到一個 Map<String, String> 類型的變數時,知道 K 和 V 現在被綁定為 String,因此它知道在這樣的變數上調用 Map.get() 將會得到 String 類型。
除了異常類型、枚舉或匿名內部類以外,任何類都可以具有類型參數。
命名類型參數
推薦的命名約定是使用大寫的單個字母名稱作為類型參數。這與 C++ 約定有所不同(參閱 附錄 A:與 C++ 模板的比較),並反映了大多數泛型類將具有少量類型參數的假定。對於常見的泛型模式,推薦的名稱是:
K —— 鍵,比如映射的鍵。
V —— 值,比如 List 和 Set 的內容,或者 Map 中的值。
E —— 異常類。
T —— 泛型。
泛型不是協變的
關於泛型的混淆,一個常見的來源就是假設它們像數組一樣是協變的。其實它們不是協變的。List<Object> 不是 List<String> 的父類型。
如果 A 擴展 B,那麼 A 的數組也是 B 的數組,並且完全可以在需要 B[] 的地方使用 A[]:
Integer[] intArray = new Integer[10];
Number[] numberArray = intArray;
上面的代碼是有效的,因為一個 Integer 是 一個 Number,因而一個 In
簡單例子:
public static void main(String[] args) { Dog dog=new Dog( "歐歐", "雪娜娜"); Dog dog1=new Dog( "亞亞", "拉布拉多"); Dog dog2=new Dog( "美美", "雪娜娜"); Dog dog3=new Dog( "菲菲", "拉布拉多"); Map<String, Dog> map=new HashMap<String, Dog>(); //Map map=new HashMap()一樣的 map.put(dog.getName(),dog); map.put(dog1.getName(),dog1); map.put(dog2.getName(),dog2); map.put(dog3.getName(),dog3); /** * 通過迭代器依次輸出集合中的所有信息 */ System.out.println("使用Iterator遍歷,所有狗狗的昵稱和品種分別是:"); Set<String> setkeys=map.keySet();//取出所有key的集合 Set setkeys=map.keySet() 是一樣的 Iterator<String> it= setkeys.iterator();//獲取Iterator對象 Iterator it= setkeys.iterator()是一樣的 /** * foreach迴圈遍歷 */ /* * for (String key1 : setkeys) { Dog dogkey=map.get(key1); // Dog dogkey= (Dog)map.get(key) System.out.println(key1+"\t"+dogkey.getStrain()); } */ while (it.hasNext()) { String key = (String) it.next(); Dog dogkey=map.get(key); // Dog dogkey= (Dog)map.get(key) System.out.println(key+"\t"+dogkey.getStrain()); } }
Java基本類型與包裝類
Java語言提供了八種基本類型。六種數字類型(四個整數型,兩個浮點型),一種字元類型,還有一種布爾型。
1、整數:包括int,short,byte,long ,初始值為0
2、浮點型:float,double ,初始值為0.0
3、字元:char ,初始值為空格,即'' ",如果輸出,在Console上是看不到效果的。
4、布爾:boolean ,初始值為false

註意:


