1.1 什麼是Spark Apache Spark 是專為大規模數據處理而設計的 快速通用 的計算引擎。 一站式管理大數據的所有場景(批處理,流處理,sql) spark不涉及到數據的存儲,只做數據的計算 Spark是UC Berkeley AMP lab (加州大學伯克利分校的AM ...
1.1 什麼是Spark
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。
一站式管理大數據的所有場景(批處理,流處理,sql)
spark不涉及到數據的存儲,只做數據的計算
Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用並行計算框架,Spark擁有Hadoop MapReduce所具有的優點;
但不同於MapReduce的是Job中間輸出結果可以保存在記憶體中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需要迭代的MapReduce的演算法。
註意:spark框架不能替代Hadoop,只能替代MR,spark的存在完善了Hadoop的生態系統.
Spark是Scala編寫,方便快速編程。
學習spark的三個網站
1) http://spark.apache.org/
2) https://databricks.com/spark/about
3) https://github.com/apache/spark
- Apache Spark™ is a fast and general engine for large-scale data processing.
- Apache Spark is an open source cluster computing system that aims to make data analytics fast
- both fast to run and fast to write
目前,Spark生態系統已經發展成為一個包含多個子項目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子項目,Spark是基於記憶體計算的大數據並行計算框架。除了擴展了廣泛使用的
MapReduce 計算模型,而且高效地支持更多計算模式,包括互動式查詢和流處理。Spark 適用於各種各樣原先需要多種不同的分散式平臺的場景,包括批處理、迭代演算法、互動式查詢、流處理。通過在一個統一的框架下支持這些不同的計算,Spark 使我們可以簡單而低耗地把各種處理流程整合在一起。而這樣的組合,在實際的數據分析 過程中是很有意義的。不僅如此,Spark 的這種特性還大大減輕了原先需要對各種平臺分別管理的負擔。
大一統的軟體棧,各個組件關係密切並且可以相互調用,這種設計有幾個好處:1、軟體棧中所有的程式庫和高級組件 都可以從下層的改進中獲益。2、運行整個軟體棧的代價變小了。不需要運 行 5 到 10 套獨立的軟體系統了,一個機構只需要運行一套軟體系統即可。系統的部署、維護、測試、支持等大大縮減。3、能夠構建出無縫整合不同處理模型的應用。
Spark的內置項目如下:
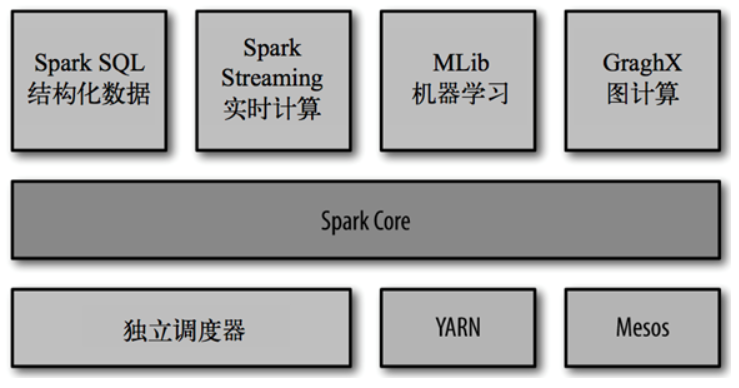
- Spark Core:實現了 Spark 的基本功能,包含任務調度、記憶體管理、錯誤恢復、與存儲系統交互等模塊。Spark Core 中還包含了對彈性分散式數據集(resilient distributed dataset,簡稱RDD)的 API 定義。
- Spark SQL:是 Spark 用來操作結構化數據的程式包。通過 Spark SQL,我們可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。Spark SQL 支持多種數據源,比如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API,並且與 Spark Core 中的 RDD API 高度對應。
- Spark MLlib:提供常見的機器學習(ML)功能的程式庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據 導入等額外的支持功能。
- 集群管理器:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計 算。為了實現這樣的要求,同時獲得最大靈活性,Spark 支持在各種集群管理器(cluster manager)上運行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自帶的一個簡易調度器,叫作獨立調度器。
1.2 Spark特點
快
與Hadoop的MapReduce相比,Spark基於記憶體的運算要快100倍以上,基於硬碟的運算也要快10倍以上。Spark實現了高效的DAG執行引擎,可以通過基於記憶體來高效處理數據流。計算的中間結果是存在於記憶體中的。

易用
Spark支持Java、Python和Scala的API,還支持超過80種高級演算法,使用戶可以快速構建不同的應用。而且Spark支持互動式的Python和Scala的shell,可以非常方便地在這些shell中使用Spark集群來驗證解決問題的方法。

通用
Spark提供了統一的解決方案。Spark可以用於批處理(Spark Core)、互動式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。這些不同類型的處理都可以在同一個應用中無縫使用。Spark統一的解決方案非常具有吸引力,畢竟任何公司都想用統一的平臺去處理遇到的問題,減少開發和維護的人力成本和部署平臺的物力成本。

相容性
Spark可以非常方便地與其他的開源產品進行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和調度器,並且可以處理所有Hadoop支持的數據,包括HDFS、HBase和Cassandra等。這對於已經部署Hadoop集群的用戶特別重要,因為不需要做任何數據遷移就可以使用Spark的強大處理能力。Spark也可以不依賴於第三方的資源管理和調度器,它實現了Standalone作為其內置的資源管理和調度框架,這樣進一步降低了Spark的使用門檻,使得所有人都可以非常容易地部署和使用Spark。此外,Spark還提供了在EC2上部署Standalone的Spark集群的工具。

1.3 Spark的用戶和用途
我們大致把Spark的用例分為兩類:數據科學應用和數據處理應用。也就對應的有兩種人群:數據科學家和工程師。
數據科學任務
主要是數據分析領域,數據科學家要負責分析數據並建模,具備 SQL、統計、預測建模(機器學習)等方面的經驗,以及一定的使用 Python、 Matlab 或 R 語言進行編程的能力。
數據處理應用
工程師定義為使用 Spark 開發 生產環境中的數據處理應用的軟體開發者,通過對接Spark的API實現對處理的處理和轉換等任務。
1.4 Spark技術棧
Spark技術棧:HDFS,Hadoop,Hive,MR,Storm,SparkCore,SparkSQL,SparkStreaming
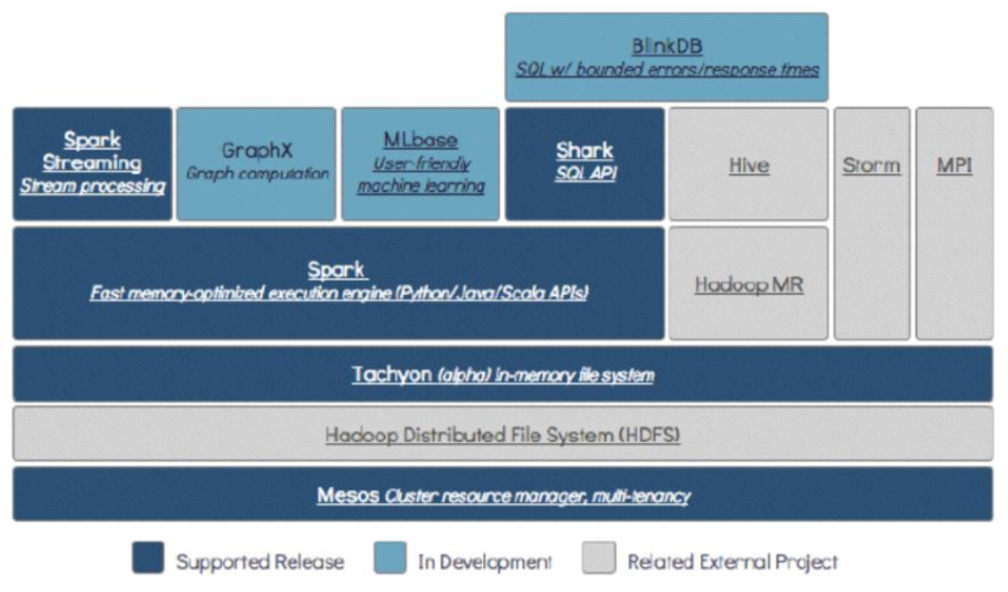
mesos相當於yarn 資源調度框架
tachyon基於記憶體:記憶體文件系統
HDFS存儲層(基於磁碟存儲 block存儲策略)
mesos資源調度/任務調度層
Spark SQL : 延遲應該在毫秒級別
Spark core:批處理 延遲度非常高
Spark streaming :流式處理 延遲5s左右
BlinkDB:支持精確度查詢的資料庫
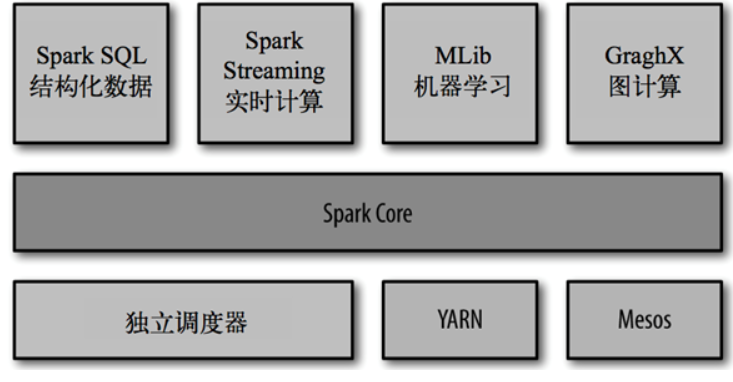
SparkCore處理批數據
SparkSql使用SQL處理分散式數據
SparkStreaming處理流式數據
一站式管理大數據的所有場景(批處理,流處理,sql)
- Spark Core:實現了 Spark 的基本功能,包含任務調度、記憶體管理、錯誤恢復、與存儲系統交互等模塊。Spark Core 中還包含了對彈性分散式數據集(resilient distributed dataset,簡稱RDD)的 API 定義。
- Spark SQL:是 Spark 用來操作結構化數據的程式包。通過 Spark SQL,我們可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。Spark SQL 支持多種數據源,比 如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API,並且與 Spark Core 中的 RDD API 高度對應。
- Spark MLlib:提供常見的機器學習(ML)功能的程式庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據 導入等額外的支持功能。
- 集群管理器:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計 算。為了實現這樣的要求,同時獲得最大靈活性,Spark 支持在各種集群管理器(cluster manager)上運行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自帶的一個簡易調度器,叫作獨立調度器。
1.5 Spark演變歷史
Spark 相比 hadoop歷史
- 發展尤為迅速
- Hadoop歷史2006~2017 11年時間
- Spark2012~2017 5年時間
Spark是美國加州大學伯克利分校的AMP實驗室(主要創始人lester和Matei)開發的通用的大
數據處理框架
• 2009伯克利大學開始編寫最初的源代碼
• 2010年才開放的源碼
• 2012年2月發佈了0.6.0版本
• 2013年6月進入了Apache孵化器項目
• 2013年年中Spark的主要成員成立的DataBricks公司
• 2014年2月成為了Apache的頂級項目( 8個月的時間)
• 2014年5月底Spark1.0.0發佈
• 2014年9月Spark1.1.0發佈
• 2014年12月spark1.2.0發佈
• 2015年3月Spark1.3.0發佈
• 2015年6月Spark1.4.0發佈
• 2015年9月Spark1.5.0發佈
• 2016年1月Spark1.6.0發佈
• 2016年5月Spark2.0.0預覽版發佈
• 2016年7月Spark2.0.0正式版發佈
• 2016年12月Spark2.1.0正式版發佈
• 2017年7月Spark2.2發佈
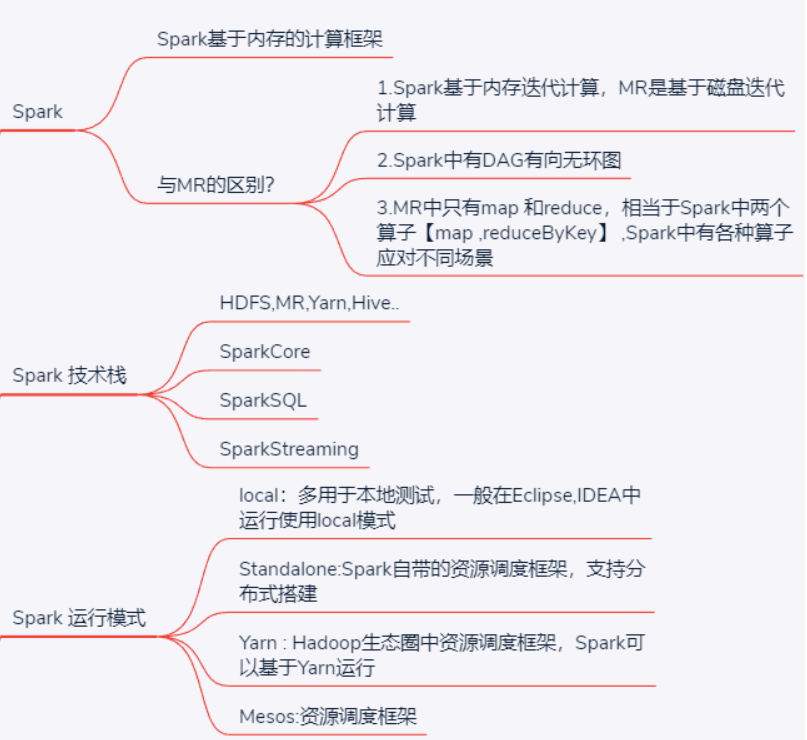
1.6 Spark與MapReduce的區別
都是分散式計算框架,Spark基於記憶體,MR基於HDFS。Spark處理數據的能力一般是MR的十倍以上,Spark中除了基於記憶體計算外,還有DAG有向無環圖來切分任務的執行先後順序。
spark不涉及到數據的存儲,只做數據的計算
spark與Hadoop MR不同的是,任務的中間結果可以保存到記憶體中,大大地提高了計算性能.
基於記憶體存儲
MR作業之間如果有依賴關係的話,每個作業都是從磁碟獲取數據,處理完成之後數據落盤。
如:磁碟-MR作業-磁碟-MR作業-磁碟
Spark作業之間如果有依賴關係的話,spark程式處理完成之後可以將數據先存於記憶體中,不落盤,下一個spark程式就可以直接從記憶體中獲取數據然後進行處理
如:磁碟-spark作業-記憶體-spark作業-記憶體-spark作業-磁碟
具體不同點
- Spark相比於MR處理數據是可以基於記憶體來處理數據的
- spark與Hadoop MR不同的是,任務的中間結果可以保存到記憶體中,大大地提高了計算性能.
- Spark中有DAG有向無環圖來切分任務的執行先後順序
- Spark存儲數據可以指定副本個數(持久化存儲),MR預設3個。
- spark中做了很多已有的運算元的封裝,提供了各種場景的運算元,而MR中只有map和reduce 相當於Spark中的map和reduceByKey兩個運算元
- Spark是粗粒度資源申請,Application執行快
- Spark中shuffle map端自動聚合功能,MR手動設置
- Spark中shuffle ByPass機制有自己靈活的實現
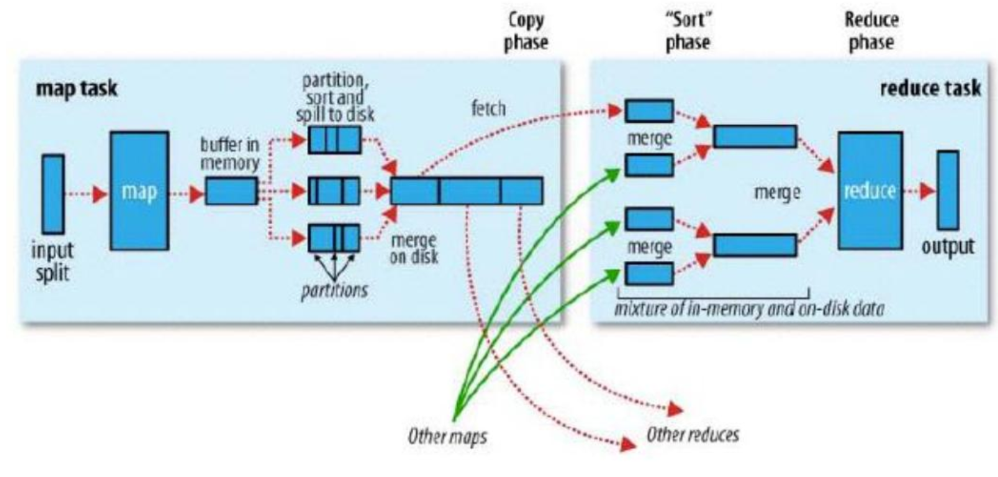
MR
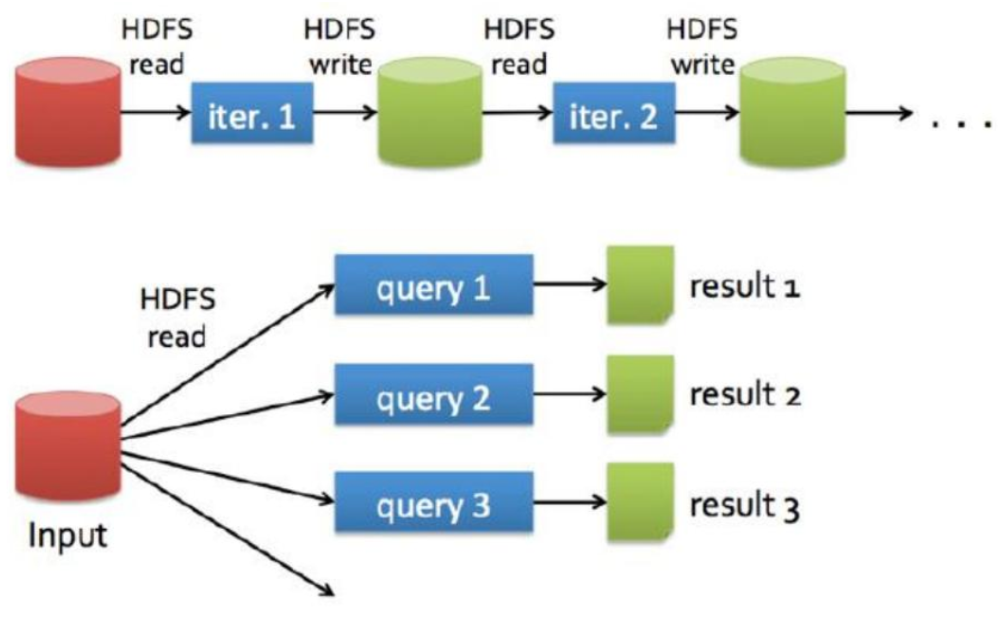
Spark
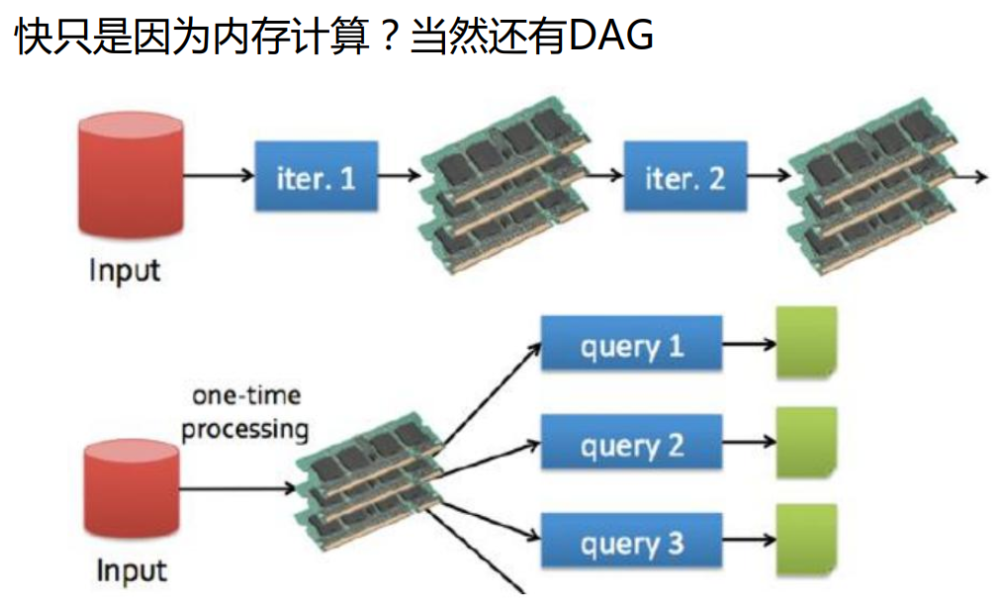
1.7 Spark API
API就是用這些語言進行編碼的時候使用的方法
應用可以通過使用Spark提供的庫獲得Spark集群的計算能力,這些庫都是Scala編寫的,但是Spark提供了面向各種語言的API,例如Scala、 Python Java等, 所以可以使用以上語言進行Spark應用開發。
Spark的API主要由兩個抽象部件組成: SparkContext和RDD ,應用程式通過這兩個部件和Spark進行交互,連接到
Spark-集群並使用相關資源。
SparkContext
是定義在Spark庫中的一個類,作為Spark庫的入口。 包含應用程式main ()方法的Driver program通過SparkContext對象訪問Spark,因為SparkContext對象表示與Spark集群的一 個連接。每個Spark應用都有且只有一個激活的SparkContext類實例,如若需要新的實例,必須先讓當前實例失活。(在shell中SparkContext已經自動創建好,就是sc)
RDD基礎概念
- 彈性分散式數據集(Resilient Distributed Dataset)
- 並行分佈在整個集群中
把指定路徑下的文本文件載入到ines這個RDD中,這個lines就是一個RDD, 代表是就是整個文本文件 - RDD是Spark分發數據和計算的基礎抽象類
例如: lines.count()
在.count(的函數操作是在RDD數據集上的,而不是對某一具體分片 - 一個RDD是一個不可改變的分散式集合對象
就lines來說,如果我們對其所代表的源文件進行了增刪改操作,則相當於生成了一個新的RDD,來存放修改後的數據集 - Spark中所有的計算都是通過RDD的創建、轉換,操作完成的
- 一個RDD內部由許多partitions (分片)組成
partitions:
每個分片包括一部分數據, 分片可在集群不同節點上計算
分片是Spark並行處理的單元,Spark順序的,並行的處理分片
1.8 Spark運行模式(部署模式)
Local
在本地eclipse、IDEA中寫spark代碼運行程式,一般用於測試
Standalone
spark自帶的資源調度框架(可以拋開hdfs,拋開yarn去運行),支持完全分散式集群搭建。Spark可以運行在standalone集群上
Yarn
Hadoop生態圈裡面的一個資源調度框架,Spark也是可以基於Yarn來計算的。
要基於Yarn來進行資源調度,必須實現AppalicationMaster介面,Spark實現了這個介面,所以可以基於Yarn。
Mesos
運行在 mesos 資源管理器框架之上,由 mesos 負責資源管理,Spark 負責任務調度和計算,(很少用)
總結