
mapreduce是一個運算框架,讓多台機器進行並行進行運算, 他把所有的計算都分為兩個階段,一個是map階段,一個是reduce階段 map階段:讀取hdfs中的文件,分給多個機器上的maptask,分文件的時候是按照文件的大小分的 比如每個maptask都會處理128M的文件大小,然後有個500 ...
mapreduce是一個運算框架,讓多台機器進行並行進行運算,
他把所有的計算都分為兩個階段,一個是map階段,一個是reduce階段
map階段:讀取hdfs中的文件,分給多個機器上的maptask,分文件的時候是按照文件的大小分的
比如每個maptask都會處理128M的文件大小,然後有個500M的文件,就會啟動ceil(500/128)個maptask
每讀取文件的一行的處理,需要自己去寫,註意每個maptask的處理邏輯都是一樣的
處理出來的結果一定是一對key和value。
maptask裡面的方法叫map(long k, string v, context); k是文件的起始偏移量,v是內容,
context是要把產生的key,value對放入的容器。
reduce階段:每個機器上有reducetask,其作用是對maptask產生的key和value進行聚合
聚合的原則是key一樣的一定分發給一個reducetask,這個操作叫做shuffle
然後把相同key的數據作為一組進行處理。最後會把結果寫到hdfs裡面
每有幾個reducetask,就會生成幾個part-r-xxxx文件
reducetask裡面的方法reduce(k,value迭代器,context),k就是key,迭代器遍歷每一個key相同的value,然後context就是寫入hdfs里的,也是一個key和value
入門樣例:wordcount
設計思路,每個maptask讀取文件,
map裡面k 起始偏移量沒用,我們每讀一行v,產生就是key是每一個單詞,然後value就定為1就行,把這個key,value放入context裡面
在reduce階段,每個key相同的就會作為一組,也就是單詞相同的作為一組,就統計出現幾次就行。
開始在esclipe寫mapreduce的業務邏輯,首先我們需要一些jar包,相關的jar包在解壓出來的hadoop下的share/hadoop文件夾下

這幾個文件夾下的jar包和這幾個文件夾下的lib下的jar包都拷貝到esclipe再buildPath
首先編寫mapper方法
package test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN :是map task讀取到的數據的key的類型,是一行的起始偏移量Long * VALUEIN:是map task讀取到的數據的value的類型,是一行的內容String * * KEYOUT:是用戶的自定義map方法要返回的結果kv數據的key的類型,在wordcount邏輯中,我們需要返回的是單詞String * VALUEOUT:是用戶的自定義map方法要返回的結果kv數據的value的類型,在wordcount邏輯中,我們需要返回的是整數Integer * * * 但是,在mapreduce中,map產生的數據需要傳輸給reduce,需要進行序列化和反序列化,而jdk中的原生序列化機制產生的數據量比較冗餘,就會導致數據在mapreduce運行過程中傳輸效率低下 * 所以,hadoop專門設計了自己的序列化機制,那麼,mapreduce中傳輸的數據類型就必須實現hadoop自己的序列化介面 * * hadoop為jdk中的常用基本類型Long String Integer Float等數據類型封住了自己的實現了hadoop序列化介面的類型:LongWritable,Text,IntWritable,FloatWritable * * * * */ //第一個泛型為起始偏移量,沒啥用,第二個為字元串,為讀取到的一行內容,第三個,第四個為context中的key,和value,即發送給reduce的k,v對 public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override //重寫map方法 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 切單詞 String line = value.toString(); String[] words = line.split(" "); for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } }
接下來是reduce類
package test; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; //第一個,第二個為接收到的map的key,value,第三第四為寫入到hdfs的key,value public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override //一個key,眾多value的迭代器,一個context; protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int count = 0; Iterator<IntWritable> iterator = values.iterator(); while(iterator.hasNext()){ IntWritable value = iterator.next(); count += value.get(); } context.write(key, new IntWritable(count)); } }
然而我們寫的程式需要提交給我們的hadoop集群去運行,而管理這個事情的就是我們的yarn
yarn是一個分散式程式的運行調度平臺
yarn中有兩大核心角色:
1、Resource Manager
接受用戶提交的分散式計算程式,併為其劃分資源
接收客戶端要運行幾個容器,進行任務調度
管理、監控各個Node Manager上的資源情況,以便於均衡負載
2、Node Manager
管理它所在機器的運算資源創建容器(cpu + 記憶體)
負責接受Resource Manager分配的任務,創建容器、回收資源
我們需要把我們的程式的jar包分發給每一個NodeManager,讓他們去運行,
node manager在物理上應該跟data node部署在一起
resource manager在物理上應該獨立部署在一臺專門的機器上
yarn的安裝
yarn我們不需要再下載了,在我們的hadoop裡面已經有了yarn,我們只需要寫一下配置文件就行
[root@hdp-04 ~]# vi apps/hadoop-2.8.1/etc/hadoop/yarn-site.xml
第一個指明哪一臺機器當做resourcemanager,第二個指明nodemanager的任務是什麼
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hdp-01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
然後複製這個文件到你的其他機器上
在你的resourcemanager機器上敲 start-yarn.sh,(關閉時stop-yarn.sh)
hadoop就會啟動resourcemanager,其他的nodemanager,hadoop是通過slave文件知道的(在/root/apps/hadoop-2.8.1/etc/hadoop/slaves),裡面寫入你的nodemanager的ip就行,一行一個。
啟動之後可以敲jps看一下
或者看網頁的形式,resourcemanager的埠號是8088.比如hdp-01:8088
然後安裝完yarn之後嘞,我們就可以寫一個java的提交任務的程式了
package test; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class JobSubmitter { public static void main(String[] args) throws Exception { //在JVM中設置訪問hdfs的用戶身份為root,因為要對存在datanode節點的文件進行讀寫,不然可能會許可權不夠 // 構造一個訪問指定HDFS系統的客戶端對象: 參數1:——HDFS系統的URI,參數2:——客戶端要特別指定的參數,參數3:客戶端的身份(用戶名) //FileSystem fs = FileSystem.get(new URI("hdfs://172.31.2.38:9000/"), conf, "root"); //如果是這樣設置訪問用戶身份是不行的,因為不光是自己的客戶端訪問hdfs, //job還會創建自己的hdfs的對象FileSystem去訪問datanode,那麼job創建的對象是從系統環境變數拿到的用戶名,所以這樣設置身份 System.setProperty("HADOOP_USER_NAME", "root"); //設置配置參數 Configuration conf = new Configuration(); //設置job運行時要訪問的預設文件系統 conf.set("fs.defaultFS", "hdfs://172.31.2.38:9000"); //設置job要提交到那裡去運行,可以是yarn,也可以是local conf.set("mapreduce.framework.name", "yarn"); //設置resourcemanager在哪 conf.set("yarn.resourcemanager.hostname", "172.31.2.38"); //如果從windows提交job,需要設置跨平臺提交時,把windows中的命令,替換成linux的 //比如運行jar包中某個程式,在linux和windows是不一樣的,這樣可以自動轉化 conf.set("mapreduce.app-submission.cross-platform","true"); //設置job Job job = Job.getInstance(conf); //封裝jar包在windows下的位置 job.setJar("d:/wc.jar"); //設置本次job所要調用的Mapper的class類和reduce的class類 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); //設置mapper實現類的產生結果的key,value類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //設置reduce實現類的產生結果的key,value類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //設置map時,job要處理的數據的路徑,和產生的結果的路徑在哪 FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); //註意輸出路徑一定要不存在 FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //設置想要啟動reduce task的數量是多少 job.setNumReduceTasks(2); //提交給yarn,等待這個job完成才退出 boolean res = job.waitForCompletion(true); System.exit(res?0:-1); } }
額外知識點:
maven創建報錯說插件下載失敗,右鍵項目
然後 右鍵屬性Maven,Update project
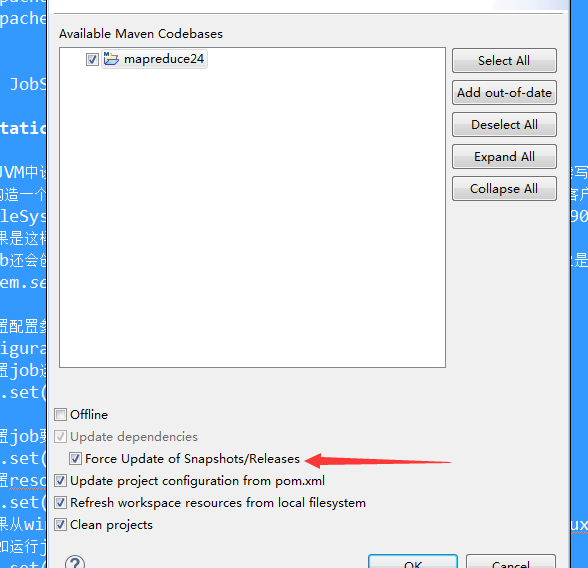
把這個給點上就行了。或者進入到org/apache/maven,把裡面的東西全刪了,讓他自己去下載。
在編程時的易錯點:
註意自己寫的路徑file:\為windows,/為linux
註意改完源碼之後,要註意重新生成一個jar包,不然提交到linux里,還是會報錯


