
"Hadoop集群搭建 05安裝配置YARN" "Hadoop集群搭建 04安裝配置HDFS " "Hadoop集群搭建 03編譯安裝hadoop" "Hadoop集群搭建 02安裝配置Zookeeper" "Hadoop集群搭建 01前期準備" 這一篇接著記錄集群搭建,開始安裝配置zookeepe ...
這一篇接著記錄集群搭建,開始安裝配置zookeeper,它的作用是做集群的信息同步,zookeeper配置時本身就是一個獨立的小集群,集群機器一般為奇數個,只要機器過半正常工作那麼這個zookeeper集群就能正常工作,工作時自動選舉一個leader其餘為follower,所以最低是配置三台。
註意本篇文章的幾乎所有操作如不標註,則預設為hadoop用戶下操作
1.首先修改下上一篇寫的批量腳本
複製一份,然後把ips內刪除兩台機器名,,只留下前三台即可,然後把幾個腳本的名稱啥的都改一下,和內部引用名都改一下。
可以用我改好的https://www.lanzous.com/b849762/ 密碼:1qq6
2.安裝zookeeper
可以用xshell的rz命令上傳zookeeper安裝包,安裝包在這裡https://www.lanzous.com/b849708/ 密碼:8a10
[hadoop@nn1 ~]$ cd zk_op/
批量發送給三台機器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/upload/zookeeper-3.4.8.tar.gz /tmp/
查看是否上傳成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /tmp | grep zoo*"
批量解壓到各自的/usr/local/目錄下
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh tar -zxf /tmp/zookeeper-3.4.8.tar.gz -C /usr/local/
再次查看是否操作成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zoo*"
批量改變/usr/local/zookeeper-3.4.8目錄的用戶組為hadoop:hadoop
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chown -R hadoop:hadoop /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chmod -R 770 /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper-3.4.8"
批量創建軟鏈接(可以理解為快捷方式)
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh ln - s /usr/local/zookeeper-3.4.8/ /usr/local/zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper"
這裡軟鏈接的用戶組合許可權可以不用修改,預設為root或者hadoop都可以。 修改/usr/local/zookeeper/conf/zoo.cfg
可以用我改好的https://www.lanzous.com/b849762/ 密碼:1qq6
批量刪除原有的zoo_sample.cfg文件,當然先備份為好
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh rm -f /usr/local/zookeeper/conf/zoo_sample.cfg
把我們準備好的配置文件放進去,批量。
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/zoo.cfg /usr/local/zookeeper/conf/
=================================================================================================
然後修改/usr/local/zookeeper/bin/zkEnv.sh腳本文件,添加日誌文件路徑
[hadoop@nn1 zk_op]$ vim /usr/local/zookeeper/bin/zkEnv.sh
ZOO_LOG_DIR=/data
把這個配置文件批量分發給其他機器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/
給5台機器創建/data目錄,註意這裡是給5台機器創建。用的沒改過的原本批量腳本。
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh mkdir /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh chown hadoop:hadoop /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_all.sh "ls -l | grep data"上面為啥是突然創建5個/data呢,,,因為後邊的hdfs和yarn都需要,後邊的hdfs是運行在後三台機器上的,所以現在直接都創建好。
然後回到zk_op中,給前三台機器創建id文件。用於zookeeper識別
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh touch /data/myid然後_分別進三台機器_,給這個文件追加id值。
第一臺:
echo "1" > /data/myid
第二台:
echo "2" > /data/myid
第三台:
echo "3" > /data/myid
3.批量設置環境變數
在nn1上切換到root用戶更改系統環境變數
[hadoop@nn1 zk_op]$ su - root
[root@nn1 ~]# vim /etc/profile
文件在末尾添加
#set Hadoop Path
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:/usr/local/zookeeper/bin然後批量發送給其他兩台機器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /etc/profile /tmp/
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh cp -f /tmp/profile /etc/profile
批量檢查一下
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh tail /etc/profile
批量source一下環境變數
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh source /etc/profile4.批量啟動zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start
查看一下是否啟動。看看有沒有相關進程
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh jps如下圖查看進程,有QPM進程就說明啟動成功
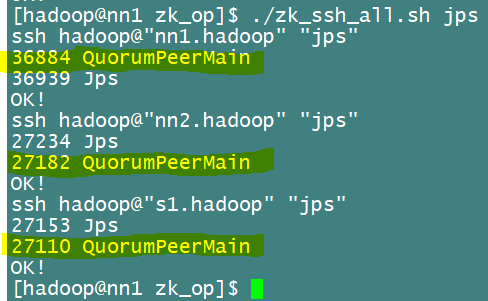
或者直接查看狀態,
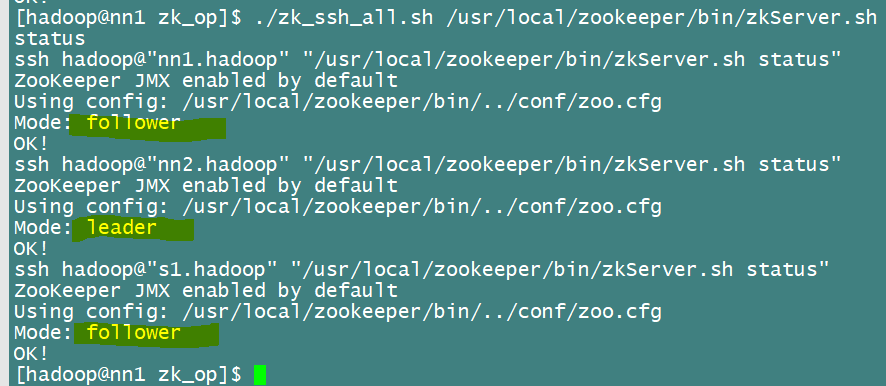
好了,zookeeper安裝配置順利結束!!!

