
基礎題 一、String,StringBuffer, StringBuilder 的區別是什麼?String為什麼是不可變的?1. String是字元串常量,StringBuffer和StringBuilder是字元串變數。StringBuffer是線程安全的,StringBuilder是非線程安全 ...
基礎題
一、String,StringBuffer, StringBuilder 的區別是什麼?String為什麼是不可變的?
1. String是字元串常量,StringBuffer和StringBuilder是字元串變數。StringBuffer是線程安全的,StringBuilder是非線程安全的。具體來說String是一個不可變的對象,每次修改String對象實際上是創新新對象,並將引用指向新對象。效率很低。StringBuffer
是可變的,即每次修改只是針對其本身,大部分情況下比String效率高,StringBuffer保證同步(synchronized),所以線程安全。StringBuilder沒有實現同步,所以非線程安全。但效率應該比StringBuffer高。StringBuffer使用時最好指定容量,這樣會比不指定容量快30%-40%,甚至比不指定容量的StringBuilder還快。
二、VECTOR,ARRAYLIST, LINKEDLIST的區別是什麼?
vector是同步的,arraylist和linkedlist不是同步的。底層方面,vector與arraylist都是基於object[]array實現的,但考慮vector線程安全,所以arraylist效率上回比vector較快。元素隨機訪問上,vector與arraylist是基本相同的,時間複雜度是O(1),linkedlist的隨機訪問元素的複雜度為O(n)。但在插入刪除數據上,linkedlist則比arraylist要快很多。linkedlist比arraylist更占記憶體,因為linkedlist每個節點上還要存儲對前後兩個節點的引用。
三、HASHTABLE, HASHMAP,TreeMap區別
Hashmap和HashTable都實現了Map介面,但HashTable是線程安全的,HashMap是非線程安全的。HashMap中允許key-value值均為null,但HashTable則不允許。HashMap適合單線程,HashTable適合多線程。HashTAble中的hash數字預設大小是11,增加方式為old*2+1,HashMap中的hash預設大小為16,且均為2的指數。TreeMap則可以將保持的數據根據key值進行排列,可以按照指定的排序方式。預設為升序。
四、ConcurrentHashMap和HashTable的區別
兩者均應用於多線程中,但當HashTable增大到一定程度時,其性能會急劇下降。因為迭代時會被鎖很長時間。但ConcurrentHashMap則通過引入分割來保證鎖的個數不會很大。簡而言之就是HashTable會鎖住真個map,而ConcurrentHashMap則只需要鎖住map的一個部分。
五、Tomcat,apache,jboss的區別
Tomcat是servlet容器,用於解析jsp,servlet。是一個輕量級的高效的容器;缺點是不支持EJB,只能用於Java應用。
Apache是http伺服器(web伺服器),類似於IIS可以用來建立虛擬站點,編譯處理靜態頁面。支持SSL技術,支持多個虛擬主機等功能。
Jboss是應用伺服器,運行EJB的javaee應用伺服器,遵循javaee規範,能夠提供更多平臺的支持和更多集成功能,如資料庫連接,JCA等。其對servlet的支持是通過集成其他servlet容器來實現的。如tomcat。
六、GET POST區別
get是從伺服器上獲取數據,post是向伺服器發送數據。
get是把參數數據隊列加到提交表單的action屬性所指的URL中,值和表單內各個欄位一一對應,在url中可以看到。post是通過HTTPpost機制,將表單內各個欄位與其內容放置在html header內一起傳送到action屬性所指的url地址。
對於get方式,服務區端用request.QueryString獲取變數值,對於post方式,伺服器端用request.Form獲取提交的數據。get傳送的數據量較小,post較大,一般不受限制。get安全性比post要低,但執行效率較高。
七、SESSION, COOKIE區別
session數據放在伺服器上,cookie則放在客戶瀏覽器上。cookie不太安全,因為可以分析出本地cookie,併進行cookie欺騙,考慮安全應使用session。session會在一定時間內保存在伺服器上,當訪問增多時,會比較占用伺服器的性能,考慮減輕伺服器壓力則應該使用cookie。單個cookie保持的數據不超過4k,很多瀏覽器都限制要給站點最多保存20個cookie。
八、Servlet的生命周期
主要分三個階段:初始化——調用init()方法,響應客戶請求階段——調用service()方法,終止階段——調用destroy方法。工作原理:客戶發送一個請求,servlet調用service方法對請求進行響應,即對請求方式進行匹配,選擇調用doGet、doPost方法等,然後進入對於的方法中調用邏輯層的方法,實現對客戶的響應。自定義的servlet必須首先servlet介面。
具體生命周期包括:裝載Servlet、伺服器創建Servlet實例、伺服器調用Servlet的init()方法、客戶請求到達伺服器、伺服器創建請求對象、服務創建相應對象、伺服器激活Servlet的service方法,請求對象和響應對象作為service()方法的參數、service()方法獲得關於請求對象的信息,處理請求,訪問其他資源,獲得需要的信息、service()方法可能激活其他方法以處理請求,如doGet(),doPost()
九、HTTP 報文包含內容
請求方法包括GET,POST,HEAD,PUT,TRACE,OPTIONS,DELETE。請求頭如:Host、User-Agent、Connection、Accept-Charset等。請求頭部的最後會有一個空行,表示請求頭部結束,接下來為請求正文,這一行非常重要,必不可少。請求正文為可選部分,如get就沒有。
十、Statement與PreparedStatement的區別,什麼是SQL註入,如何防止SQL註入
使用PreparedStatement可以提升代碼的可讀性和可維護性,可以盡最大可能提高性能。因為Statement每次執行一個SQL命令都會對其編譯,但PreparedStatement則只編譯一次。PreparedStatement就類似於流水線生產。另一方面PreparedStatement可以極大提高安全性:它對傳遞過來的參數進行了強制參數類型轉換,確保插入或查詢數據時,與底層資料庫格式匹配。
SQL註入:就是通過將sql命令插入到web表單遞交或輸入功能變數名稱或頁面請求的查詢字元串,最終達到欺騙伺服器執行惡意SQL命令。如sql命令:select id from test where name='1' or 1=1; drop table test,但用PreparedStatement就可以避免這種問題。
十一、redirect, forward區別
redirect:伺服器根據邏輯,發送一個狀態碼,告訴瀏覽器重新去請求那個地址。所以地址欄顯示是新的url。forward是指伺服器請求資源,直接訪問目標地址url,把響應的內容讀取過來並再發送給瀏覽器,瀏覽器並不知道資源從哪裡來,所以地址欄不變。
redirect不能共用數據,forward轉發頁面和轉發到頁面可以貢獻request中的數據。redirect用於註銷,forward用於登陸。forward效率高於redirect。
十二、關於JAVA記憶體模型,一個對象(兩個屬性,四個方法)實例化100次,現在記憶體中的存儲狀態,幾個對象,幾個屬性,幾個方法。
Java新建的對象都放在堆里,如果實例化100次,堆中產生100個對象,一般對象與其屬性和方法屬於一個整體,但如果屬性和方法是靜態的,則屬性和方法只在記憶體中存一份。
十三、談談Hibernate的理解,一級和二級緩存的作用,在項目中Hibernate都是怎麼使用緩存的
一級緩存為session基本的緩存,是內置的不能卸載。一個Session做了一個查詢操作,它會把這個結果放在一級緩存中,如果短時間內這個session又做了同一個操作,那麼hibernate就直接從一級緩存中獲取數據。
二級緩存是SessionFactory的緩存,分為內置緩存和外置緩存兩類。即查詢結果放在二級緩存中,如果同一個sessionFactory創建的某個session執行了相同的操作,hibernate就會從二級緩存中獲取結果。適合放在二級緩存中的數據包括:很少被修改的數據,不是很重要的數據,允許出現偶偶併發的數據,不會被併發訪問的數據,參考數據。不適合放在二級緩存中的數據:經常被修改的數據,財務數據,絕對不允許出現併發,與其他應用共用的數據。
十四、反射講一講,主要是概念,都在哪需要反射機制,反射的性能,如何優化
能夠分析類能力的程式稱為反射。反射機制可以用來:在運行中分析類的能力,在運行中查看對象,如編寫一個toString方法供所有類使用。實現通用的數據操作代碼。利用Method對象,這個對象很像C++的指針。
反射性能優化方法主要為設置不用做安全檢查。
十五、談談Hibernate與Ibatis的區別,哪個性能會更高一些
Ibatis相當較為簡單,容易上手,Hibernate比較複雜,門檻較高。如果系統需要處理數據量很大,性能要求很高,需要執行高度優化的sql語句才能達到性能要求,則此時Ibatis會比較好。
對不同資料庫支持方面Hibernate較好,因為Ibatis需要修改的欄位較多。另外Hibernate現已成為主流的o/r Mapping框架,開發效率高。
十六、對Spring的理解,項目中都用什麼?怎麼用的?對IOC、和AOP的理解及實現原理
十七、線程同步,併發操作怎麼控制
線程同步不一定就是同時,而是協同步驟,或協同步調。線程同步就是多個線程在邏輯上互有因果關係,所以要對其執行順序進行協調。
線程併發是指同一時間間隔內,多個線程同時執行。如果線程在時間上能夠區分,那麼就可以上線程休眠指定的時間來進行同步,可用sleep()方法完成。如果線程在時間上不能區分,但在邏輯順序上可以區分的話,那麼可用jion()方法來完成,一個先執行完,然後執行另一個。如果線程設計較為複雜,那麼就只有通過wait(),notify()方法來完成了
十八、描述struts的工作流程。
簡略過程就是web應用啟動,接收用戶請求併進行匹配,返回用戶請求信息。
1. 在web應用啟動時,載入並初始化ActionServlet,ActionServlet從struct-config.xml文件中讀取配置信息,把它們存放到各個配置對象中。
2. 當ActionServlet接收到一個客戶請求時,首先檢索和用戶請求相配的ActionMapping實例,如果不存在,返回用戶請求路徑無效信息。
3. 如ActionForm實例不存在,則創建一個ActionForm對象,把客戶提交的表單數據保存到ActionForm對象中。
4. 根據配置信息決定是否需要表單驗證。如果需要驗證,就調用ActionForm的Validate()方法。如果Valiedate()方法返回null或返回一個不包含ActionMessage的ActionErrors對象,則表示表單驗證成功。
5. ActionServlet更加ActionMapping實例包含的映射信息決定請請求轉發給哪個Action。如果相應的Action實例不存在,則先創建這個實例,然後調用Action的execute()方法。
6. Action的execute()方法返回一個ActionForward對象,ActionServlet再把客戶請求轉發給ActionForward對象指向的JSP組建。
7. ActionForward對象指向的jsp組件生成的動態網頁,返回給客戶。
十九、Tomcat的session處理,如果讓你實現一個tomcatserver,如何實現session機制
當一個session開始時,Servlet容器會創建一個HttpSession對象,在某些情況下把這些HttpSession對象從記憶體中轉移到文件系統中或資料庫中。需要訪問的時候將它們載入到記憶體中。這樣的好處就是節省記憶體,當web伺服器產生故障時,還可以從文件系統或資料庫中恢復Session的數據。管理session有兩個類:1)StandardManager,這是一個預設的類,當tomcat啟動或重載時將會session對象保存到指定文件中。2)PersistentManager,管理方式更加靈活,具有容錯能力,可以及時把Session備份到Session Store中,可以控制記憶體中Session的數量。
二十、關於Cache(Ehcache,Memcached)
Memcache:分散式記憶體對象緩存系統,占用其他機子的記憶體。很多互聯網,負載均衡三台(以三台為例)web伺服器可以共用一臺Memcache的資源。傳遞的信息以鍵值對的形式存儲。傳遞的數據要實現序列化。
Oscache:頁面級緩存(網上強調最多的東西),占用本機的記憶體資源。可 以選擇緩存到硬碟,如存取到硬碟重啟服務也可重新獲得上次持久化的資源,而如果緩存到記憶體就不行。一般沒必要緩存到硬碟,因為I/O操作也是比較耗資源,和從資料庫取往往優勢很小。Oscache存取數據的作用域分為application和session兩種。
EhCache:Hibernate緩存,DAO緩存,安全性憑證緩存(Acegi),Web緩存,應用持久化和分散式緩存。EhCache在預設情況下,即在用戶未提供自身配置文件ehcache.xml或ehcache-failsafe.xml時,EhCache會依據其自身Jar存檔包含的ehcache-failsafe.xml文件所定製的策略來管理緩存。如果用戶在classpath下提供了ehcache.xml或ehcache-failsafe.xml文件,那麼EhCache將會應用這個文件。如果兩個文件同時提供,那麼EhCache會使用ehcache.xml文件的配置。
二一、sql的優化相關問題
1. 對查詢優化,避免全表掃描
2. 儘量避免where子句中對段進行null值判斷,否則將導致引擎放棄使用索引而進行全表掃描。
3. 儘量避免where子句中出現!=或<>,否則將導致引擎放棄使用索引而進行全表掃描。
4. 儘量避免where子句中出現or來連接條件。
5. 慎用in和not in,否則導致全表掃描
6. where中不要用函數操作。
7. Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁調用會引起明顯的性能消耗,同時帶來大量日誌。
8. 對於多張大數據量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,性能很差。
9. 儘可能的使用 varchar/nvarchar 代替 char/nchar,節省空間,提高查詢效率
10. select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
二二、oracle中 rownum與rowid的理解,一千條記錄我查200到300的記錄怎麼查?
二三、如何分析ORACLE的執行計劃?
二四、 DB中索引原理,種類,使用索引的好處和問題是什麼?
原理:因為檢索磁碟比對數據,需要大量的時間和IO,所以就需要構造某列的數據的btree、hash值、點陣圖索引。一般的索引能快速的查找比對,而索引的值記錄了磁碟的位置,直接讀取資料庫欄位對應位置的內容。
索引好處:加快數據檢索速度、加速表與表之間的連接特別是實現數據的參考完整性方面有特別的意義、減少查詢中分組和排序的時間,使用優化隱藏器,提高系統性能。
缺點:創建和維護索引需要時間,索引需要占用物理空間,當對錶中的數據驚醒增刪改時所有也需要動態維護。
二五、JVM垃圾回收實現原理。垃圾回收的線程優先順序。
JVM的堆空間中主要分為年輕代、年老代和永久代。年輕代和年老代是存儲動態產生的對象。永久代主要是存儲java類信息,包括解析得到的方法屬性、欄位等等。永久代基本不參與垃圾回收。年輕代分為一個eden區和兩個相同的survior區。剛開始創建的對象都放置在eden區。這樣主要是為了將生命周期短的對象儘量留在年輕代中。當eden區申請不到空間時,進行minorGC,把存活的對象拷貝到survior。年老代主要存放生命周期比較長的對象,如緩存對象。具體JVM垃圾回收過程如下:
1、對象在Eden區完成記憶體分配。2、當Eden區滿了,在創建對象就會申請不到空間,則觸發minorGC,進行young(eden區和1survivor區的垃圾回收)。3、在minorGC時,Eden不能被回收的對象唄放入到空的survior(即Eden肯定被清空),另一個survivor里不能被GC回收的地想也會被放入到這個survivor,始終保證一個survivor是空的。4、當完成第三步的時候、如果發現survivor滿了,則這些對象唄copy到old區,或者survivor並沒有滿,但有些對象已經足夠old了,也被放入到old區。當old區北放滿之後,進行fullGC。
二六、jvm 最大記憶體設置。設置的原理。結合垃圾回收講講。
JVM記憶體可以分為堆記憶體和非堆記憶體,堆記憶體給開發人員用的,非堆記憶體給JVM本身用的,用來存放類型信息,即使GC時也不會釋放空間。
堆記憶體設置:
-Xms 初始堆記憶體,預設物理記憶體1/64,也是最小分配堆記憶體,當空餘堆記憶體小於40%時,會增加到-Xms的最大限制。
-Xmx 最大堆記憶體分配,預設物理記憶體1/4,當空餘堆記憶體大於70%時,會減小打-Xms的最小限制。
非堆記憶體設置:
-XX:PermSize 非堆記憶體的初始值,預設物理記憶體的1/64,也是最小非堆記憶體。
-XX:MaxPermSize 非堆記憶體最大值,預設物理記憶體的1/4。
查看堆大小命令為Runtime.getRuntime().maxMemory()。
二七、jvm怎樣通過參數調整記憶體大小
本地環境變數中JVM參數設置:
new一個JAVA_OPTS:
variable name: JAVA_OPTS
variable value: -Xms256M -Xmx512M -XX:PermSize=256M -XX:MaxPermSize=512M
eclipse中參數設置:在預設VM參數中輸入:-Xmx128m -Xms64m -Xmn32m -Xss16m
二八、進程與線程的區別
線程是進程的一個單元,也是進程內的可調度實體。區別就是:1、進程內的線程共用地址空間,進程則自己獨立的地址空間。2、進程是資源分配和擁有的單位,同一個進程內的線程共用進程資源。3、線程是處理器調度的基本單位。4、兩者均可併發執行。
二九、怎樣避免死鎖
1. 使用事務時,儘量縮短事務idea邏輯處理過程,及早提交或回滾事務
2. 設置死鎖的超時參數為合理範圍,如3-10分鐘,若超過時間,自動放棄本次操作,避免進程懸掛。
3. 優化程式,檢查並避免死鎖現象出現。
4. 對所有的腳本和sp都要仔細測試。
5. 所有的sp都要有錯誤處理。
6. 一般不要修改sql事務的預設級別。不推薦強行加鎖。
三十、垃圾回收演算法使用的產品、場景
標記-清除演算法:標記階段,確定所有要回收的對象,並標記,清除階段則將需要回收的對象清除。
複製演算法:把記憶體分為大小相等的兩塊,每次使用其中的一塊,當垃圾回收時,把存活的對象複製到另一塊上,然後把這塊記憶體整個清理掉。兩塊記憶體比是8:1
標記整理演算法:把存活的對象往記憶體的一端移動,然後直接回收邊界以外的記憶體。標記-整理演算法提高了記憶體的利用率,並且它適合在收集對象存活時間較長的老年代。
分代回收演算法:根據對象的存活時間把記憶體分為新生代和老年代,根據各代對象的存活特點,每代採用不同的GC演算法。新生代用標記-複製演算法,老年代用標記-整理演算法。
三一、實際項目中JVM調優
1、JVM啟動參數:調整各代的記憶體比例和垃圾回收演算法,提高吞吐量。
2、改進程式邏輯演算法,提高性能
3、自定義封裝線程池,解決用戶響應時間長的問題。比如設置線程最小數量、最大數量
4、連接池
三二、jdk併發包的集合介紹
Map併發包,其實現為ConcurrentHashMap,它實現了ConcurrentMap介面。put方法為根據計算出的hash值去獲取segment對象。找到segment對象後調用該對象的put方法完成操作。segment中的put方法則是先加鎖,之後判斷數組大小,然後覺得是否擴充。然後得到key索要放置的位置。
List併發包,客在高併發環境下使用CopyOnWriteArrayList代替ArrayList。添加元素是利用數組的copy功能和加鎖機制。併發情況下,CopyOnWriteArrayList比ArrayList略快了些。
set併發,CopyOnWriteSet和CopyOnWriteArrayList底層實現差不多就是在添加元素時會進行唯一性判斷,如果對象數組已經含有重覆的元素,不進行增加處理。
queue併發,併發類是ArrayBlockingQueue,底層為數組,並對關鍵的方法入隊、出隊操作加入了鎖隊機制。
Atomic系列類,比如AtomicInteger類,通過使用計數器操作時,一般為了避免線程安全問題,在方法上加鎖操作。有了併發包下的原子系列類,我們就可以直接使用。
三三、線程之間的通信
主要包括互斥鎖、條件變數、讀寫鎖和線程信號燈。
互斥鎖:以排他方式防止數據被併發修改。互斥鎖兩個狀態0和1。具體為申請鎖、占用鎖以防止數據被修改,此時預設阻塞等等,最後釋放鎖。
條件變數通信機制:原理,條件變數出現時,可以彌補互斥鎖的缺陷,有些問題僅僅依靠互斥鎖無法解決。但條件變數不能單獨使用,必須配合互斥鎖一起實現對資源的互斥訪問。
讀寫鎖:在對數據讀寫時,往往讀占主要部分。基本原則是如果其他線程讀數據,則允許其他線程執行讀操作,但不允許寫操作。如果有其他線程申請寫操作,則其他線程不能申請讀操作和寫操作。
線程信號:線程擁有與信號相關的私有數據——線程信號掩碼。線程可以向別的線程發送信號,每個線程可以設置自己的阻塞集合。所有線程中,同一信號子任何線程里的對該信號的處理一定相同。
三四、介紹threadlocal
可以叫做線程本地變數或線程本地存儲。ThreadLocal為變數在每個線程中都創建了一個副本,每個線程都可以訪問自己內部的副本變數。但可能這樣做會導致記憶體占用較大。
ThreadLocal類的幾個方法:get() 用來獲取ThreadLocal在當前線程中保存的變數副本,set()用來設置當前線程中變數的副本,remove()用來一衝當前線程中的變數副本,initialValue()一般用來在使用時進行重寫,是一個延遲載入方法。最常見的ThreadLocal使用場景是用來解決資料庫連接、Session管理等。
三五、jdbc的操作過程
載入資料庫驅動包、連接資料庫、使用sql語句操作資料庫、關閉資料庫連接
三六、HTTP1.1的新特性
支持持續連接,通過建立一個TCP後,發送請求並得到響應,然後發送更多的請求並得到更多的響應。通過把簡歷和釋放TCP連接的開銷分攤到多個請求上,則對每個請求而言,優於TCP而造成的相對開銷被大大降低。而且還可以發送流水線請求。
三七、異常處理,包含了什麼
參考:http://lavasoft.blog.51cto.com/62575/18920/
三八、堆排序與快速排序

package cst.zju.algorithm;
/*
* 快速排序
*/
public class Quicksort {
public int[] data;
public Quicksort(int a[]){
this.data = a;
}
public void quicksort(int left, int right){
int index;
if(left < right){
index = partition(left, right);
quicksort(left, index-1);
quicksort(index+1, right);
}
}
public int partition(int left, int right){
int pivot = this.data[left];
while(left < right){
while(left < right && this.data[right] >= pivot)
right --;
if(left < right)
this.data[left++] = this.data[right];
while(left < right && this.data[left] <= pivot){
left ++;
}
if(left < right){
this.data[right--] = this.data[left];
}
}
this.data[left] = pivot;
return left;
}
public void printdata(){
for(int i = 0; i < this.data.length; i ++)
System.out.print(this.data[i] + " ");
System.out.println("");
}
public static void main(String[] args) {
int[] a = { 5, 3, 6, 2, 1, 9, 4, 8, 7 };
Quicksort qs = new Quicksort(a);
qs.quicksort(0, a.length-1);
qs.printdata();
}
}
View Code
package cst.zju.algorithm;
import java.awt.print.Printable;
import javax.security.auth.kerberos.KerberosKey;
/**
* 堆排序,假設父節點為i,則左節點為2*i+1,右節點為2*i+2
* @author dandelion
*
*/
public class Heapsort {
public static int[] data;
public Heapsort(int[] data){
this.data = data;
}
public void printdata(){
for(int i = 0; i < data.length; i ++){
System.out.print(data[i] + " ");
}
System.out.println("");
}
public static void main(String[] args) {
int[] a = { 5, 3, 6, 2, 1, 9, 4, 8, 7 };
Heapsort t = new Heapsort(a);
t.printdata();
System.out.println("=========================");
t.heapSort();
System.out.println("=========================");
t.printdata();
}
public void swap(int i, int j){
if (i == j) return;
this.data[i] = this.data[i] + this.data[j];
this.data[j] = this.data[i] - this.data[j];
this.data[i] = this.data[i] - this.data[j];
}
public void reconstructionHeap(int lastindex){
for(int i = (lastindex-1)/2; i >= 0; i --){
int j = i;
//保證當前結點的子節點存在
while(2*j+1 <= lastindex){
int big = 2*j + 1;
if(big < lastindex){
//保證右子節點存在
if(data[big] < data[big + 1]){
big = big + 1;
}
}
if(data[j] < data[big]){
swap(j, big);
j = big;
}else{
break;
}
}
}
}
public void heapSort(){
for(int i = 0; i < this.data.length; i ++){
int tmp = this.data.length - 1 - i;
reconstructionHeap(tmp);
swap(0,tmp);
printdata();
}
}
}
View Code
堆排序是漸進最優的比較排序演算法,達到了O(nlgn)這一下界,而快排有一定的可能性會產生最壞劃分,時間複雜度可能為O(n^2)。堆排比較的幾乎都不是相鄰元素,對cache極不友好。數學複雜度並不一定代表實際運行的複雜度。
三九、Collection有哪些類
Set, List, Map, SortedSet, SortedMap, HashSet, TreeSet, ArrayList, LinkedList, Vector, Collections, Arrays, AbstractCollection
四十、Hashcode總為1會怎樣,如何解決hash衝突
當所有對象Hashcode返回都為1時,所有對象都出現hash衝突,其性能會下降
解決hash衝突:
線性再散列法、插入元素時,如果發生衝突,演算法會簡單的遍歷hash表,直到找到表中的下一個空槽,並將該元素放入該槽中。查找元素時,首先散列值所指向的槽,如果沒有找到匹配,則繼續遍歷hash表,直到:(1)找到相應的元素;(2)找到一個空槽(指示查找的元素不存在);(3)整個hash表遍歷完畢(指示該元素不存在並且hash表是滿的)。
非線性再散列法、線性再散列法是從衝突位置開始,採用一個步長以順序方式遍歷hash表,來查找一個可用的槽,從上面的討論可以看出,它容易產生聚集現象。非線性再散列法可以避免遍歷散列表,它會計算一個新的hash值,並通過它跳轉到表中一個完全不同的部分。
外部拉鏈法、將hash表看作是一個鏈表數組,表中的每個槽要不為空,要不指向hash到該槽的表項的鏈表。
四一、如何用兩個隊列實現棧
即可以將A隊列作為棧push,B隊列作為棧pop。量隊列數據相同。
四二、Object的通用方法
通用方法有equals(), finalize(), toString(), 其他native方法有hashcode(), registerNatives(), getClass(), clone(), notify(), notifyAll(), wait()等。
四三、Java中如何實現多態
多態是OOP中的一個重要特性,主要用來實現動態聯編,程式的最終狀態只有在執行過程中才被決定而非在編譯期間就決定了。有利於提高大型系統的靈活性和擴展性。
多態的三個必要條件:有繼承、有方法重寫、父類引用指向子類對象。
引用變數的兩種類型:編譯時類型由申明類型決定,運行時類型由實際對應的對象決定。
package cst.zju.oop;
public class Animal {
public void voice(){
System.out.println("動物叫聲");
}
}
class Cat extends Animal{
public void voice(){
System.out.println("喵喵喵");
}
public void catchMouse(){
System.out.println("抓老鼠");
}
}
class Dog extends Animal{
public void voice(){
System.out.println("旺旺網");
}
}
class Pig extends Animal{
public void voice(){
System.out.println("哼哼哼");
}
}
View Code
package cst.zju.oop;
public class TestAnimal {
public static void testvoice(Animal e){
e.voice();
if(e instanceof Cat){
((Cat) e).catchMouse();
}
}
public static void main(String[] args) {
Animal a = new Cat();
Animal b = new Dog();
Animal c = new Pig();
testvoice(a);
testvoice(b);
testvoice(c);
//報錯,因為Animal類中沒有這個方法
//a.catchMouse();
Cat a1 = (Cat) a;
a1.catchMouse();
}
}
View Code
多態記憶體:
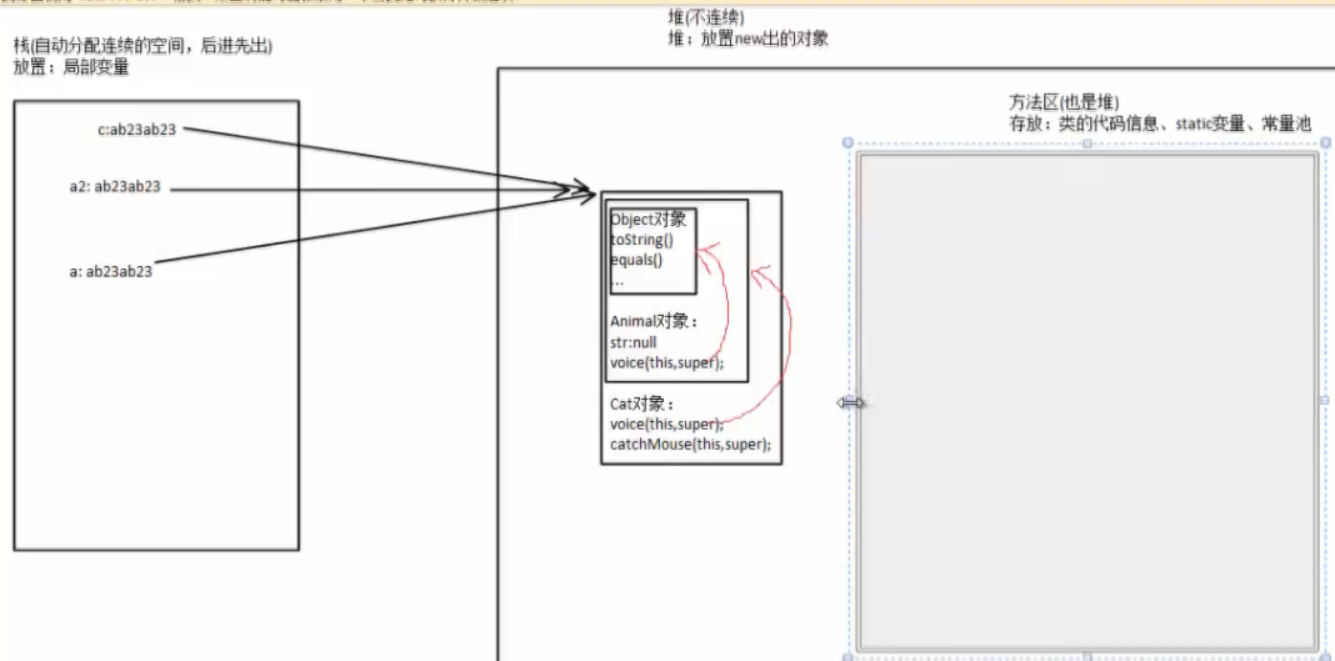
四四、Java記憶體泄漏
記憶體泄漏一般情況下有兩種情況:C++/C語言中,在堆中分配的記憶體,沒有將其釋放掉就刪除了所有能訪問到這塊記憶體的方式全部刪除。(如指針重新賦值)
另一種情況就是在記憶體對象已經不需要時,還保留這塊記憶體和它的訪問方式(引用),由於Java中GC機制,所以Java中的記憶體泄漏通常指第二種情況。
儘管對於C/C++中的記憶體泄露情況來說,Java記憶體泄露導致的破壞性小,除了少數情況會出現程式崩潰的情況外,大多數情況下程式仍然能正常運行。但是,在移動設備對於記憶體和CPU都有較嚴格的限制的情況下,Java的記憶體溢出會導致程式效率低下、占用大量不需要的記憶體等問題。這將導致整個機器性能變差,嚴重的也會引起拋出OutOfMemoryError,導致程式崩潰。
在不涉及複雜數據結構情況下,Java記憶體泄漏表現為一個記憶體對象的生命周期超出程式需要它的長度。(稱為對象游離)。
記憶體泄漏實例:Java堆溢出、虛擬機棧和本地方法棧溢出、方法區和運行時常量池溢出、本機直接記憶體溢出
四五、final欄位總結
1. final類不能被繼承,其中的方法也是預設final類型,沒有子類。
2. final方法不能被子類覆蓋,但可以繼承
3. final變數表示常量,只能被賦值一次賦值後不改變
4. final不能用於構造方法
四六、override(重寫)和overload(重載)區別
override:子類在繼承父類時,子類可以定義某些方法與父類的方法名稱、參數個數、類型、順序、返回值類型一致,但調用時自動調用子類的方法,父類相當於被覆蓋了。
overload:可以表現在類的多態上,函數名相同,但其他參數個數、類型、順序、返回值等都不相同。
四七、static初始化
未經初始化的全局靜態變數會被自動初始化為0。


