
hdfs:分散式文件系統 有目錄結構,頂層目錄是: /,存的是文件,把文件存入hdfs後,會把這個文件進行切塊並且進行備份,切塊大小和備份的數量有客戶決定。 存文件的叫datanode,記錄文件的切塊信息的叫namenode Hdfs的安裝 準備四台linux伺服器 先在hdp-01上進行下麵操作 ...
hdfs:分散式文件系統
有目錄結構,頂層目錄是: /,存的是文件,把文件存入hdfs後,會把這個文件進行切塊並且進行備份,切塊大小和備份的數量有客戶決定。
存文件的叫datanode,記錄文件的切塊信息的叫namenode
Hdfs的安裝
準備四台linux伺服器
先在hdp-01上進行下麵操作
- 配置功能變數名稱映射
vim /etc/hosts
主機名:hdp-01 對應的ip地址:192.168.33.61
主機名:hdp-02 對應的ip地址:192.168.33.62
主機名:hdp-03 對應的ip地址:192.168.33.63
主機名:hdp-04 對應的ip地址:192.168.33.64
- 更改本機的功能變數名稱映射文件
c:/windows/system32/drivers/etc/hosts
|
192.168.33.61 hdp-01 192.168.33.62 hdp-02 192.168.33.63 hdp-03 192.168.33.64 hdp-04 |
- 關閉防火牆
service iptables stop
setenforce 0
- 安裝jdk
在linux中 tar –zxvf jdk-8u141-linux-x64.tar.gz –C /root/apps/
然後vim /etc/profile
export JAVA_HOME=/root/apps/ jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
然後source /etc/profile
Ok
- 安裝scp
yum install -y openssh-clients
yum list
yum list | grep ssh
- 配置免密登錄(在hdp-01上)
輸入ssh-keygen
然後三次回車
然後
ssh-copy-id hdp-02
ssh-copy-id hdp-03
ssh-copy-id hdp-04
- 然後開始安裝hadoop
上傳壓縮包,然後
[root@hdp-01 ~]# tar -zxvf hadoop-2.8.1.tar.gz -C apps/
然後修改配置文件
|
要點提示 |
核心配置參數: 1) 指定hadoop的預設文件系統為:hdfs 2) 指定hdfs的namenode節點為哪台機器 3) 指定namenode軟體存儲元數據的本地目錄 4) 指定datanode軟體存放文件塊的本地目錄 |
1) 修改hadoop-env.sh
export JAVA_HOME=/root/apps/ jdk1.8.0_141
2) 修改core-site.xml
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-01:9000</value> </property> </configuration> |
3) 修改hdfs-site.xml
|
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/root/hdpdata/name/</value> </property>
<property> <name>dfs.datanode.data.dir</name> <value>/root/hdpdata/data</value> </property>
<property> <name>dfs.namenode.secondary.http-address</name> <value>hdp-02:50090</value> </property>
</configuration> |
- 然後配置hadoop的環境變數 vi /etc/profile
export HADOOP_HOME=/root/apps/hadoop-2.8.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 講apps下的東西和/etc/profile和/etc/hosts/都拷貝到其他的機器上
scp -r /root/apps/hadoop-2.8.1 hdp-02:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp-03:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp-04:/root/apps/
- 初始化元數據目錄
hadoop namenode –format(在hdp-01上)
然後啟動namenode進程
hadoop-daemon.sh start namenode
然後,在windows中用瀏覽器訪問namenode提供的web埠:50070
http://hdp-01:50070
hadoop內部埠為9000
然後,啟動眾datanode們(在任意地方)
hadoop-daemon.sh start datanode
增加datanode隨時可以,減少可不能瞎搞。。。。
或者一種方便的啟動方法
修改hadoop安裝目錄中/etc/hadoop/slaves(把需要啟動datanode進程的節點列入)
|
hdp-01 hdp-02 hdp-03 hdp-04 |
在hdp-01上用腳本:start-dfs.sh 來自動啟動整個集群
如果要停止,則用腳本:stop-dfs.sh
hdfs的客戶端會讀以下兩個參數,來決定切塊大小、副本數量:
切塊大小的參數: dfs.blocksize
副本數量的參數: dfs.replication
上面兩個參數應該配置在客戶端機器的hadoop目錄中的hdfs-site.xml中配置
|
<property> <name>dfs.blocksize</name> <value>64m</value> </property>
<property> <name>dfs.replication</name> <value>2</value> </property>
|
至此完成
hdfs的一些操作
查看目錄信息
hadoop fs -ls /
上傳文件從/xxx/xx上傳到/yy
hadoop fs -put /xxx/xx /yyy
hadoop fs -copyFromLocal /本地文件 /hdfs路徑 ## copyFromLocal等價於 put
hadoop fs -moveFromLocal /本地文件 /hdfs路徑 ## 跟copyFromLocal的區別是:從本地移動到hdfs中
下載文件到本地
hadoop fs -get /hdfs路徑 /local路徑
hadoop fs -copyToLocal /hdfs中的路徑 /本地磁碟路徑 ## 跟get等價
hadoop fs -moveToLocal /hdfs路徑 /本地路徑 ## 從hdfs中移動到本地
追加內容到已存在的文件
hadoop fs -appendToFile /本地文件 /hdfs中的文件
其他命令和linux的基本差不多只不過前面加hadoop fs –
額外知識
1.
元數據:對數據的描述信息,namenode記錄的就叫元數據
2.
配置yum源配置文件
先將那個磁碟掛載到一個文件夾下比如/mnt/cdrom

然後配置yum
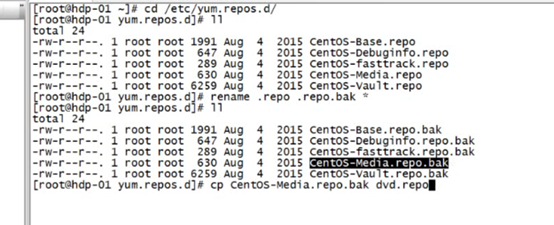
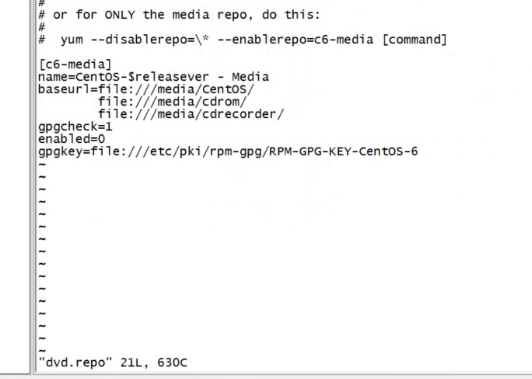
改為這樣的
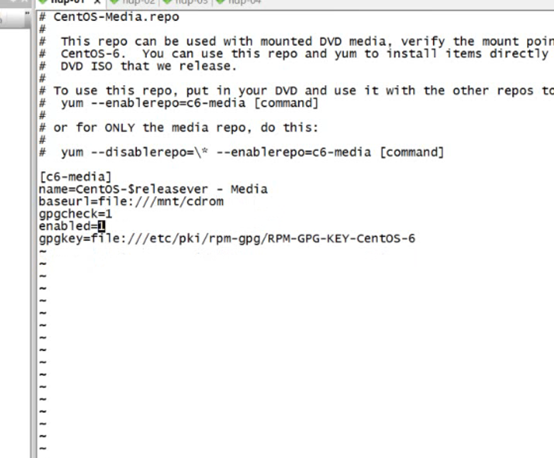
3.
命令netstat –nltp 監聽埠號
或者ps –ef是查看進程號
4.
讓防火牆每次開機不重啟
chkconfig iptables off
service的執行腳本放在 /etc/service下
凡是能使用 service 服務 動作 的指令
都可以在/etc/init.d目錄下執行
例如: /etc/init.d/sshd start
使用 service 服務 動作 例子 service papche2 restart
其實是執行了一個腳本
/etc/init.d apache2 restatr
linux伺服器啟動的時候分為6個等級
0.表示關機
1.單用戶模式
2.無網路的多用戶模式
3.有網路的多用戶模式
4.不可用
5.圖形化界面
6.重新啟動
具體和預設的啟動等級可以在 /etc/inittab目錄下查看
查看各個級別下服務開機自啟動情況 可以使用 chkconfig --list
增加一個自啟動服務 chkconfig --add 服務名 例如 chkconfig --add sshd
減少一個自啟動服務 chkconfig --add 服務名 例如 chkconfig --del sshd
chkconfig --level 等級 服務 off/on
chkconfig是當前不生效,Linux重啟之後才生效的命令(開機自啟動項)
service是即使生效,重啟後失效的命令
5.
C語言寫的東西和平臺是有關係的,在Windows下寫的東西放到linux不一定可以
而java可以,因為有java虛擬機
6.
Hdfs的url hdfs://hdp-01:9000/
ll –h
在類 Unix 系統中,/dev/null 稱空設備,是一個特殊的設備文件,它丟棄一切寫入其中的數據(但報告寫入操作成功),讀取它則會立即得到一個 EOF。
而使用 cat $filename > /dev/null 則不會得到任何信息,因為我們將本來該通過標準輸出顯示的文件信息重定向到了 /dev/null 中。
使用 cat $filename 1 > /dev/null 也會得到同樣的效果,因為預設重定向的 1 就是標準輸出。 如果你對 shell
7
Cat 來拼接兩個文件,如在hdfs下的兩個block文件
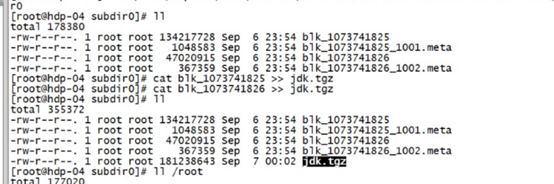
如此拼接就成了一個完整的源文件
源文件的路徑在
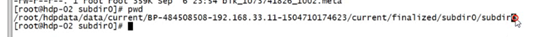
java客戶端的api
//官方文檔
//先把hadoop安裝包解壓後的share目錄下的hadoop目錄下的相關jar包都拷到你的esclipe下。
//http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
//會先預設讀取classpath中載入的core-default.xml.hdfs-default.xml core-size.xml....
//這些都是一個個jar包,你也可以在src目錄下自己寫一個hdfs-site.xml文件
Configuration conf = new Configuration();
conf.set("dfs.replication","2");//指定副本數
conf.set("dfs.blocksize","64m");//指定切塊大小
//模擬一個客戶端
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"),conf,"root");
然後可以通過fs.xxxxx的方法來使用

