
問題: 正常start-all.sh無法啟動datanode進程,但是./hadoop-daemon.sh start datanode又可以啟動。過一會後datanode進程又莫名消失。 原理: 多次hdfs namenode -format導致namenode生成了新的clusterID, 和d ...
問題:
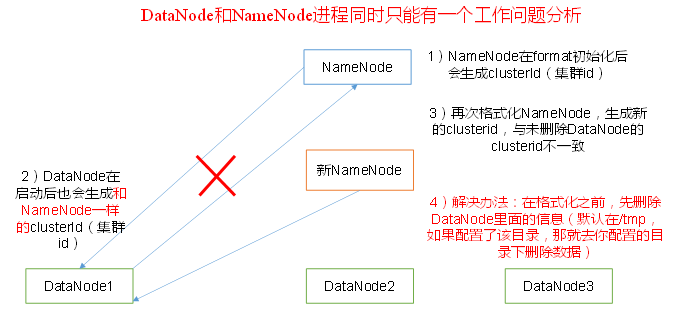
正常start-all.sh無法啟動datanode進程,但是./hadoop-daemon.sh start datanode又可以啟動。過一會後datanode進程又莫名消失。
原理:
多次hdfs namenode -format導致namenode生成了新的clusterID, 和datanode的不一致。
解決:
查日誌,發現異常信息如下:
2019-07-22 17:46:09,856 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/wjy/hadoop/tmp/dfs/data java.io.IOException: Incompatible clusterIDs in /home/wjy/hadoop-3.1.1/tmp/dfs/data: namenode clusterID = CID-8041cf56-7cbd-423e-a0b6-f782c1e1340f; datanode clusterID = CID-0d8412e3-e59b-4b1b-acdf-871b8cfa2f79
照著網上說的刪除本地dfs.data.dir下的所有內容然後重啟進程並沒有解決我的問題。這個dfs.data.dir是在hdfs-site.xml里找的(由於我用的hadoop3.1.1,所以是dfs.datanode.data.dir):

把data下麵的current文件夾刪了以後再次格式化namenode,還是那個問題,不同的是namenode的clusterID發生了改變(這很正常,因為重新格式化以後又生成了新的clusterID),datanode的clusterID卻一直沒變。按理說datanode的clusterID應該是在data/current/VERSION裡面被記錄的,但是現在我根本就把這個文件夾給刪掉了。。。 而且啟動datanode時應該會生成一個和namenode一樣的clusterID的,並沒有。把namenode的VERSION給複製過去做適當的修改還是沒用。
後來我發現在下圖這個路徑下麵還有一個data文件夾,下麵的VERSION文件中的clusterID正是錯誤信息中的那個!
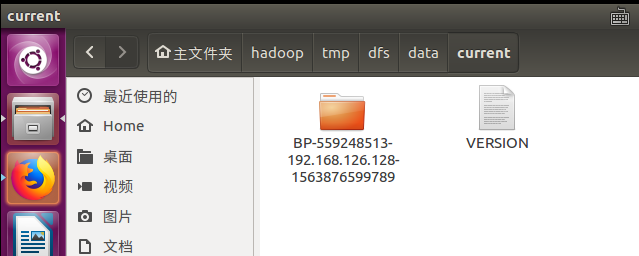
原來我之前刪錯了。。。 把這個current給刪掉再重啟一次datanode果然就好了(完全分散式記得要刪除所有節點的哦,不然slave的datanode也會起不來的)。
可是很奇怪,為什麼這個文件不生成在設置的dfs.datanode.name.dir的文件夾下麵呢?而是在這個預設路徑裡面。

