
Javascript是前端面試的重點,本文重點梳理下 Javascript 中的常考基礎知識點,然後就一些容易出現的題目進行解析。限於文章的篇幅,無法將知識點講解的面面俱到,本文只羅列了一些重難點。 ...
引言
Javascript是前端面試的重點,本文重點梳理下 Javascript 中的常考基礎知識點,然後就一些容易出現的題目進行解析。限於文章的篇幅,無法將知識點講解的面面俱到,本文只羅列了一些重難點。
一、變數類型
1.JS 的數據類型分類
根據 JavaScript 中的變數類型傳遞方式,分為基本數據類型和引用數據類型。其中基本數據類型包括Undefined、Null、Boolean、Number、String、Symbol (ES6新增,表示獨一無二的值),而引用數據類型統稱為Object對象,主要包括對象、數組和函數。
在參數傳遞方式上,有所不同:
-
函數的參數如果是簡單類型,會將一個值類型的數值副本傳到函數內部,函數內部不影響函數外部傳遞的參數變數
-
如果是一個參數是引用類型,會將引用類型的地址值複製給傳入函數的參數,函數內部修改會影響傳遞參數的引用對象。
題目:基本類型和引用類型的區別
基本類型和引用類型存儲於記憶體的位置不同,基本類型直接存儲在棧中,而引用類型的對象存儲在堆中,與此同時,在棧中存儲了指針,而這個指針指向正是堆中實體的起始位置。下麵通過一個小題目,來看下兩者的主要區別:
// 基本類型 var a = 10 var b = a b = 20 console.log(a) // 10 console.log(b) // 20
上述代碼中,a b都是值類型,兩者分別修改賦值,相互之間沒有任何影響。再看引用類型的例子:
// 引用類型 var a = {x: 10, y: 20} var b = a b.x = 100 b.y = 200 console.log(a) // {x: 100, y: 200} console.log(b) // {x: 100, y: 200}
上述代碼中,a b都是引用類型。在執行了b = a之後,修改b的屬性值,a的也跟著變化。因為a和b都是引用類型,指向了同一個記憶體地址,即兩者引用的是同一個值,因此b修改屬性時,a的值隨之改動
2.數據類型的判斷
1)typeof
typeof返回一個表示數據類型的字元串,返回結果包括:number、boolean、string、symbol、object、undefined、function等7種數據類型,但不能判斷null、array等
typeof Symbol(); // symbol 有效 typeof ''; // string 有效 typeof 1; // number 有效 typeof true; //boolean 有效 typeof undefined; //undefined 有效 typeof new Function(); // function 有效 typeof null; //object 無效 typeof [] ; //object 無效 typeof new Date(); //object 無效 typeof new RegExp(); //object 無效
2)instanceof
instanceof 是用來判斷A是否為B的實例,表達式為:A instanceof B,如果A是B的實例,則返回true,否則返回false。instanceof 運算符用來測試一個對象在其原型鏈中是否存在一個構造函數的 prototype 屬性,但它不能檢測null 和 undefined
[] instanceof Array; //true {} instanceof Object;//true new Date() instanceof Date;//true new RegExp() instanceof RegExp//true null instanceof Null//報錯 undefined instanceof undefined//報錯
3)constructor
constructor作用和instanceof非常相似。但constructor檢測 Object與instanceof不一樣,還可以處理基本數據類型的檢測。不過函數的 constructor 是不穩定的,這個主要體現在把類的原型進行重寫,在重寫的過程中很有可能出現把之前的constructor給覆蓋了,這樣檢測出來的結果就是不准確的。
4)Object.prototype.toString.call()
Object.prototype.toString.call() 是最準確最常用的方式。
Object.prototype.toString.call('') ; // [object String]
Object.prototype.toString.call(1) ; // [object Number]
Object.prototype.toString.call(true) ; // [object Boolean]
Object.prototype.toString.call(undefined) ; // [object Undefined]
Object.prototype.toString.call(null) ; // [object Null]
Object.prototype.toString.call(new Function()) ; // [object Function]
Object.prototype.toString.call(new Date()) ; // [object Date]
Object.prototype.toString.call([]) ; // [object Array]
Object.prototype.toString.call(new RegExp()) ; // [object RegExp]
Object.prototype.toString.call(new Error()) ; // [object Error]
3.淺拷貝與深拷貝
淺拷貝只複製指向某個對象的指針,而不複製對象本身,新舊對象還是共用同一塊記憶體。
淺拷貝的實現方式(詳見https://github.com/ljianshu/Blog/issues/5):
-
Object.assign():需註意的是目標對象只有一層的時候,是深拷貝
-
Object.assign(target, ...sources);target:目標對象,sources:一個或多個源對象
- 註:Object.assign 可以把 n 個源對象拷貝到目標對象中去,如下
-
let m ={name: {asd: '123'}}; let n = Object.assign({}, m); console.log(n);//{name: {asd: '123'}}那到底是深拷貝還是淺拷貝呢,答案是修改第一級屬性深拷貝,以後級別屬性淺拷貝 。大家看下麵兩段代碼
-
let s ={name: {asd: '123'}}; let d = Object.assign({}, s); d.name.asd = '123456789'; console.log(d, s);//{name:{asd: "123456789"}},{name:{asd: "123456789"}}let o ={name: {asd: '123'}}; let p = Object.assign({}, o); p.name = '123456789'; console.log(p, o);//{name: "123456789"},{name: {asd: "123"}} -
Array.prototype.concat()
-
Array.prototype.slice()
深拷貝就是在拷貝數據的時候,將數據的所有引用結構都拷貝一份。簡單的說就是,在記憶體中存在兩個數據結構完全相同又相互獨立的數據,將引用型類型進行複製,而不是只複製其引用關係。
深拷貝的實現方式:
-
熱門的函數庫lodash,也有提供_.cloneDeep用來做深拷貝
-
jquery 提供一個$.extend可以用來做深拷貝
-
JSON.parse(JSON.stringify())
-
手寫遞歸方法
遞歸實現深拷貝的原理:要拷貝一個數據,我們肯定要去遍歷它的屬性,如果這個對象的屬性仍是對象,繼續使用這個方法,如此往複。
//定義檢測數據類型的功能函數 function checkedType(target) { return Object.prototype.toString.call(target).slice(8, -1) } //實現深度克隆---對象/數組 function clone(target) { //判斷拷貝的數據類型 //初始化變數result 成為最終克隆的數據 let result, targetType = checkedType(target) if (targetType === 'Object') { result = {} } else if (targetType === 'Array') { result = [] } else { return target } //遍歷目標數據 for (let i in target) { //獲取遍曆數據結構的每一項值。 let value = target[i] //判斷目標結構里的每一值是否存在對象/數組 if (checkedType(value) === 'Object' || checkedType(value) === 'Array') { //對象/數組裡嵌套了對象/數組 //繼續遍歷獲取到value值 result[i] = clone(value) } else { //獲取到value值是基本的數據類型或者是函數。 result[i] = value } } return result }
二、作用域和閉包
1.執行上下文和執行棧
執行上下文就是當前 JavaScript 代碼被解析和執行時所在環境的抽象概念, JavaScript 中運行任何的代碼都是在執行上下文中運行。執行上下文的生命周期包括三個階段:創建階段→執行階段→回收階段,我們重點介紹創建階段。
創建階段(當函數被調用,但未執行任何其內部代碼之前)會做以下三件事:
-
創建變數對象:首先初始化函數的參數arguments,提升函數聲明和變數聲明。
-
創建作用域鏈:下文會介紹
-
確定this指向:下文會介紹
function test(arg){ // 1. 形參 arg 是 "hi" // 2. 因為函數聲明比變數聲明優先順序高,所以此時 arg 是 function console.log(arg); var arg = 'hello'; // 3.var arg 變數聲明被忽略, arg = 'hello'被執行 function arg(){ console.log('hello world') } console.log(arg); } test('hi'); /* 輸出: function arg() { console.log('hello world'); } hello */
這是因為當函數執行的時候,首先會形成一個新的私有的作用域,然後依次按照如下的步驟執行:
-
如果有形參,先給形參賦值
-
進行私有作用域中的預解釋,函數聲明優先順序比變數聲明高,最後後者會被前者所覆蓋,但是可以重新賦值
-
私有作用域中的代碼從上到下執行
函數多了,就有多個函數執行上下文,每次調用函數創建一個新的執行上下文,那如何管理創建的那麼多執行上下文呢?
JavaScript 引擎創建了執行棧來管理執行上下文。可以把執行棧認為是一個存儲函數調用的棧結構,遵循先進後出的原則。

從上面的流程圖,我們需要記住幾個關鍵點:
-
JavaScript執行在單線程上,所有的代碼都是排隊執行。
-
一開始瀏覽器執行全局的代碼時,首先創建全局的執行上下文,壓入執行棧的頂部。
-
每當進入一個函數的執行就會創建函數的執行上下文,並且把它壓入執行棧的頂部。當前函數執行完成後,當前函數的執行上下文出棧,並等待垃圾回收。
-
瀏覽器的JS執行引擎總是訪問棧頂的執行上下文。
-
全局上下文只有唯一的一個,它在瀏覽器關閉時出棧。
2.作用域與作用域鏈
ES6 到來JavaScript 有全局作用域、函數作用域和塊級作用域(ES6新增)。我們可以這樣理解:作用域就是一個獨立的地盤,讓變數不會外泄、暴露出去。也就是說作用域最大的用處就是隔離變數,不同作用域下同名變數不會有衝突。在介紹作用域鏈之前,先要瞭解下自由變數,如下代碼中,console.log(a)要得到a變數,但是在當前的作用域中沒有定義a(可對比一下b)。當前作用域沒有定義的變數,這成為 自由變數。
var a = 100 function fn() { var b = 200 console.log(a) // 這裡的a在這裡就是一個自由變數 console.log(b) } fn()
自由變數的值如何得到 —— 向父級作用域(創建該函數的那個父級作用域)尋找。如果父級也沒呢?再一層一層向上尋找,直到找到全局作用域還是沒找到,就宣佈放棄。這種一層一層的關係,就是作用域鏈 。
function F1() { var a = 100 return function () { console.log(a) } } function F2(f1) { var a = 200 console.log(f1()) } var f1 = F1() F2(f1) // 100
3.閉包是什麼
閉包這個概念也是JavaScript中比較抽象的概念,我個人理解,閉包是就是函數中的函數(其他語言不能這樣),裡面的函數可以訪問外面函數的變數,外面的變數的是這個內部函數的一部分。
閉包的作用:
-
使用閉包可以訪問函數中的變數。
-
可以使變數長期保存在記憶體中,生命周期比較長。
(閉包的缺點)-> 閉包不能濫用,否則會導致記憶體泄露,影響網頁的性能。閉包使用完了後,要立即釋放資源,將引用變數指向null。
閉包主要有兩個應用場景:
-
函數作為參數傳遞(見作用域部分例子)
-
函數作為返回值(如下例)
function outer() { var num = 0 //內部變數 return function add() { //通過return返回add函數,就可以在outer函數外訪問了。 num++ //內部函數有引用,作為add函數的一部分了 console.log(num) } } var func1 = outer() // func1() //實際上是調用add函數, 輸出1 func1() //輸出2 var func2 = outer() func2() // 輸出1 func2() // 輸出2
4.this全面解析
先搞明白一個很重要的概念 —— this的值是在執行的時候才能確認,定義的時候不能確認!為什麼呢 —— 因為this是執行上下文環境的一部分,而執行上下文需要在代碼執行之前確定,而不是定義的時候。看如下例子:
// 情況1 function foo() { console.log(this.a) //1 } var a = 1 foo() // 情況2 function fn(){ console.log(this); } var obj={fn:fn}; obj.fn(); //this->obj // 情況3 function CreateJsPerson(name,age){ //this是當前類的一個實例p1 this.name=name; //=>p1.name=name this.age=age; //=>p1.age=age } var p1=new CreateJsPerson("尹華芝",48); // 情況4 function add(c, d){ return this.a + this.b + c + d; } var o = {a:1, b:3}; add.call(o, 5, 7); // 1 + 3 + 5 + 7 = 16 add.apply(o, [10, 20]); // 1 + 3 + 10 + 20 = 34 // 情況5 <button id="btn1">箭頭函數this</button> <script type="text/javascript"> let btn1 = document.getElementById('btn1'); let obj = { name: 'kobe', age: 39, getName: function () { btn1.onclick = () => { console.log(this);//obj }; } }; obj.getName(); </script>

三、非同步
1.同步 vs 非同步
同步,我的理解是一種線性執行的方式,執行的流程不能跨越。比如說話後在吃飯,吃完飯後在看手機,必須等待上一件事完了,才執行後面的事情。
非同步,是一種並行處理的方式,不必等待一個程式執行完,可以執行其它的任務。比方說一個人邊吃飯,邊看手機,邊說話,就是非同步處理的方式。在程式中非同步處理的結果通常使用回調函數來處理結果。
// 同步 console.log(100) alert(200); console.log(300) //100 200 300 // 非同步 console.log(100) setTimeout(function(){ console.log(200) }) console.log(300) //100 300 200
2.非同步和單線程
JS 需要非同步的根本原因是 JS 是單線程運行的,即在同一時間只能做一件事,不能“一心二用”。為了利用多核CPU的計算能力,HTML5提出Web Worker標準,允許JavaScript腳本創建多個線程,但是子線程完全受主線程式控制制,且不得操作DOM。所以,這個新標準並沒有改變JavaScript單線程的本質。
一個 Ajax 請求由於網路比較慢,請求需要 5 秒鐘。如果是同步,這 5 秒鐘頁面就卡死在這裡啥也幹不了了。非同步的話,就好很多了,5 秒等待就等待了,其他事情不耽誤做,至於那 5 秒鐘等待是網速太慢,不是因為 JS 的原因。
3.前端非同步的場景
前端使用非同步的場景
-
定時任務:setTimeout,setInterval
-
網路請求:ajax請求,動態載入
-
事件綁定
4.Event Loop
一個完整的 Event Loop 過程,可以概括為以下階段:
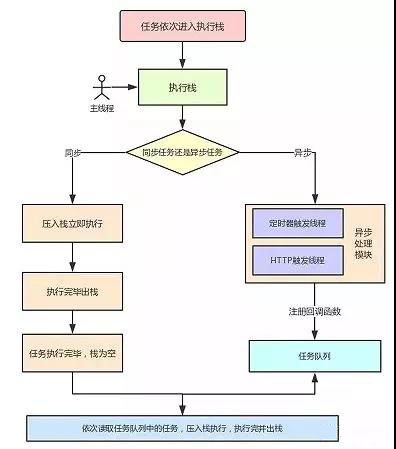
-
一開始執行棧空,我們可以把執行棧認為是一個存儲函數調用的棧結構,遵循先進後出的原則。micro 隊列空,macro 隊列里有且只有一個 script 腳本(整體代碼)。
-
全局上下文(script 標簽)被推入執行棧,同步代碼執行。在執行的過程中,會判斷是同步任務還是非同步任務,通過對一些介面的調用,可以產生新的 macro-task 與 micro-task,它們會分別被推入各自的任務隊列里。同步代碼執行完了,script 腳本會被移出 macro 隊列,這個過程本質上是隊列的 macro-task 的執行和出隊的過程。
-
上一步我們出隊的是一個 macro-task,這一步我們處理的是 micro-task。但需要註意的是:當 macro-task 出隊時,任務是一個一個執行的;而 micro-task 出隊時,任務是一隊一隊執行的。因此,我們處理 micro 隊列這一步,會逐個執行隊列中的任務並把它出隊,直到隊列被清空。
-
執行渲染操作,更新界面
-
檢查是否存在 Web worker 任務,如果有,則對其進行處理
-
上述過程迴圈往複,直到兩個隊列都清空
接下來我們看道例子來介紹上面流程:
Promise.resolve().then(()=>{ console.log('Promise1') setTimeout(()=>{ console.log('setTimeout2') },0) }) setTimeout(()=>{ console.log('setTimeout1') Promise.resolve().then(()=>{ console.log('Promise2') }) },0)
最後輸出結果是Promise1,setTimeout1,Promise2,setTimeout2
-
一開始執行棧的同步任務(這屬於巨集任務)執行完畢,會去查看是否有微任務隊列,上題中存在(有且只有一個),然後執行微任務隊列中的所有任務輸出Promise1,同時會生成一個巨集任務 setTimeout2
-
然後去查看巨集任務隊列,巨集任務 setTimeout1 在 setTimeout2 之前,先執行巨集任務 setTimeout1,輸出 setTimeout1
-
在執行巨集任務setTimeout1時會生成微任務Promise2 ,放入微任務隊列中,接著先去清空微任務隊列中的所有任務,輸出 Promise2
-
清空完微任務隊列中的所有任務後,就又會去巨集任務隊列取一個,這回執行的是 setTimeout2
讓我們再看一個例子:
for (var i = 0; i < 5; i++) { console.log(i); } //輸出://0 1 2 3 4 //-------省略線--------- //如果改成這樣呢? for (var i = 0; i < 5; i++) { setTimeout(function() { console.log(i); }, 1000 * i); } //setTimeout 會延遲執行,那麼執行到 console.log 的時候,其實 i 已經變成 5 了 //輸出://開始輸出一個 5,然後每隔一秒再輸出一個 5,一共 5 個 5 //&那應該怎麼改才能輸出 0 到 4 呢? //加個閉包就解決了,穩! for (var i = 0; i < 5; i++) { (function() { setTimeout(function() { console.log(i); }, i * 1000); })(i); } //&刪掉這個 i 會發生什麼? for (var i = 0; i < 5; i++) { (function() { setTimeout(function() { console.log(i); }, i * 1000); })(i); } //這樣子的話,內部其實沒有對 i 保持引用,其實會變成輸出 5。 //&如果改一下,會輸出什麼? for (var i = 0; i < 5; i++) { setTimeout((function(i) { console.log(i); })(i), i * 1000); } //&如果改成這樣,會輸出什麼? for (var i = 0; i < 5; i++) { setTimeout((function(i) { console.log(i); })(i), i * 1000); } //這裡給 setTimeout 傳遞了一個立即執行函數。額,setTimeout 可以接受函數或者字元串作為參數,那麼這裡立即執行函數是個啥呢,應該是個 undefined ,
也就是說等價於: setTimeout(undefined, ...); //而立即執行函數會立即執行,那麼應該是立馬輸出的。 //“應該是立馬輸出 0 到 4 吧。” //&最後改成這樣,會輸出什麼? setTimeout(function() { console.log(1) }, 0); new Promise(function executor(resolve) { console.log(2); for( var i=0 ; i<10000 ; i++ ) { i == 9999 && resolve(); } console.log(3); }).then(function() { console.log(4); }); console.log(5); //首先先碰到一個 setTimeout,於是會先設置一個定時,在定時結束後將傳遞這個函數放到任務隊列裡面,因此開始肯定不會輸出 1 。 //然後是一個 Promise,裡面的函數是直接執行的,因此應該直接輸出 2 3 。 //然後,Promise 的 then 應當會放到當前 tick 的最後,但是還是在當前 tick 中。 //因此,應當先輸出 5,然後再輸出 4 。 //最後在到下一個 tick,就是 1 。 //最終輸出2 3 5 4 1
例子出處:https://zhuanlan.zhihu.com/p/25407758
四、原型鏈與繼承
1.原型和原型鏈
原型:在JavaScript中原型是一個prototype對象,用於表示類型之間的關係。
原型鏈:JavaScript萬物都是對象,對象和對象之間也有關係,並不是孤立存在的。對象之間的繼承關係,在JavaScript中是通過prototype對象指向父類對象,直到指向Object對象為止,這樣就形成了一個原型指向的鏈條,專業術語稱之為原型鏈。
var Person = function() { this.age = 18 this.name = '匿名' } var Student = function() {} //創建繼承關係,父類實例作為子類原型 Student.prototype = new Person() var s1 = new Student() console.log(s1)

當試圖得到一個對象的某個屬性時,如果這個對象本身沒有這個屬性,那麼會去它的 __proto__(即它的構造函數的prototype)中尋找。如果一直找到最上層都沒有找到,那麼就宣告失敗,返回undefined。最上層是什麼 —— Object.prototype.__proto__===null

2.繼承
介紹幾種常見繼承方式:
> 原型鏈+借用構造函數的組合繼承
function Parent(value) { this.val = value } Parent.prototype.getValue = function() { console.log(this.val) } function Child(value) { Parent.call(this, value) } Child.prototype = new Parent() const child = new Child(1) child.getValue() // 1 child instanceof Parent // true
以上繼承的方式核心是在子類的構造函數中通過 Parent.call(this) 繼承父類的屬性,然後改變子類的原型為 newParent() 來繼承父類的函數。
這種繼承方式優點在於構造函數可以傳參,不會與父類引用屬性共用,可以復用父類的函數,但是也存在一個缺點就是在繼承父類函數的時候調用了父類構造函數,導致子類的原型上多了不需要的父類屬性,存在記憶體上的浪費。
> 寄生組合繼承:這種繼承方式對上一種組合繼承進行了優化
function Parent(value) { this.val = value } Parent.prototype.getValue = function() { console.log(this.val) } function Child(value) { Parent.call(this, value) } Child.prototype = Object.create(Parent.prototype, { constructor: { value: Child, enumerable: false, writable: true, configurable: true } }) const child = new Child(1) child.getValue() // 1 child instanceof Parent // true
以上繼承實現的核心就是將父類的原型賦值給了子類,並且將構造函數設置為子類,這樣既解決了無用的父類屬性問題,還能正確的找到子類的構造函數。
-
ES6中class 的繼承
ES6中引入了class關鍵字,class可以通過extends關鍵字實現繼承,還可以通過static關鍵字定義類的靜態方法,這比 ES5 的通過修改原型鏈實現繼承,要清晰和方便很多。需要註意的是,class關鍵字只是原型的語法糖,JavaScript繼承仍然是基於原型實現的。
class Parent { constructor(value) { this.val = value } getValue() { console.log(this.val) } } class Child extends Parent { constructor(value) { super(value) this.val = value } } let child = new Child(1) child.getValue() // 1 child instanceof Parent // true
class 實現繼承的核心在於使用 extends 表明繼承自哪個父類,並且在子類構造函數中必須調用 super,因為這段代碼可以看成 Parent.call(this,value)。
五、DOM操作與BOM操作
1.DOM操作
當網頁被載入時,瀏覽器會創建頁面的文檔對象模型(DOM),我們可以認為 DOM 就是 JS 能識別的 HTML 結構,一個普通的 JS 對象或者數組。接下來我們介紹常見DOM操作:
> 新增節點和移動節點
var div1 = document.getElementById('div1') // 添加新節點 var p1 = document.createElement('p') p1.innerHTML = 'this is p1' div1.appendChild(p1) // 添加新創建的元素 // 移動已有節點。註意,這裡是“移動”,並不是拷貝 var p2 = document.getElementById('p2') div1.appendChild(p2)
> 獲取父元素
var div1 = document.getElementById('div1') var parent = div1.parentElement
> 獲取子元素
var div1 = document.getElementById('div1') var child = div1.childNodes
> 刪除節點
var div1 = document.getElementById('div1') var child = div1.childNodes div1.removeChild(child[0])
2.DOM事件模型和事件流
DOM事件模型分為捕獲和冒泡。
一個事件發生後,會在子元素和父元素之間傳播(propagation)。這種傳播分成三個階段。
(1)捕獲階段:事件從window對象自上而下向目標節點傳播的階段;
(2)目標階段:真正的目標節點正在處理事件的階段;
(3)冒泡階段:事件從目標節點自下而上向window對象傳播的階段。
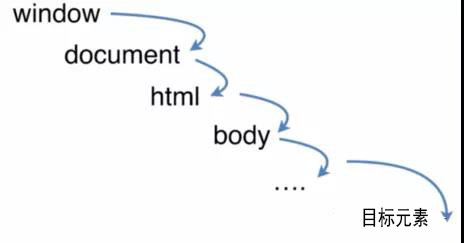
捕獲是從上到下,事件先從window對象,然後再到document(對象),然後是html標簽(通過document.documentElement獲取html標簽),然後是body標簽(通過document.body獲取body標簽),然後按照普通的html結構一層一層往下傳,最後到達目標元素。
接下來我們看個事件冒泡的例子:
// 事件冒泡 <div id="outer"> <div id="inner"></div> </div> ...... window.onclick = function() { console.log('window'); }; document.onclick = function() { console.log('document'); }; document.documentElement.onclick = function() { console.log('html'); }; document.body.onclick = function() { console.log('body'); } outer.onclick = function(ev) { console.log('outer'); }; inner.onclick = function(ev) { console.log('inner'); };

如何阻止冒泡?
通過 event.stopPropagation() 方法阻止事件冒泡到父元素,阻止任何父事件處理程式被執行。
我們可以在上例中inner元素的click事件上,添加 event.stopPropagation()這句話後,就阻止了父事件的執行,最後只列印了'inner'。
inner.onclick = function(ev) { console.log('inner') ev.stopPropagation() }
3.事件代理(事件委托)
由於事件會在冒泡階段向上傳播到父節點,因此可以把子節點的監聽函數定義在父節點上,由父節點的監聽函數統一處理多個子元素的事件。這種方法叫做事件的代理。
我們設定一種場景,如下代碼,一個 <div>中包含了若幹個 <a>,而且還能繼續增加。那如何快捷方便地為所有 <a>綁定事件呢?
<div id="div1"> <a href="#">a1</a> <a href="#">a2</a> <a href="#">a3</a> <a href="#">a4</a> </div> <button>點擊增加一個 a 標簽</button>
如果給每個 <a>標簽一一都綁定一個事件,那對於記憶體消耗是非常大的。藉助事件代理,我們只需要給父容器div綁定方法即可,這樣不管點擊的是哪一個後代元素,都會根據冒泡傳播的傳遞機制,把父容器的click行為觸發,然後把對應的方法執行,根據事件源,我們可以知道點擊的是誰,從而完成不同的事。
var div1 = document.getElementById('div1') div1.addEventListener('click', function (e) { // e.target 可以監聽到觸發點擊事件的元素是哪一個 var target = e.target if (e.nodeName === 'A') { // 點擊的是 <a> 元素 alert(target.innerHTML) } })
最後,使用代理的優點如下:
-
使代碼簡潔
-
減少瀏覽器的記憶體占用
4.BOM 操作
BOM(瀏覽器對象模型)是瀏覽器本身的一些信息的設置和獲取,例如獲取瀏覽器的寬度、高度,設置讓瀏覽器跳轉到哪個地址。
-
window.screen對象:包含有關用戶屏幕的信息
-
window.location對象:用於獲得當前頁面的地址(URL),並把瀏覽器重定向到新的頁面
-
window.history對象:瀏覽歷史的前進後退等
-
window.navigator對象:常常用來獲取瀏覽器信息、是否移動端訪問等等
獲取屏幕的寬度和高度
console.log(screen.width)
console.log(screen.height)
獲取網址、協議、path、參數、hash 等
// 例如當前網址是 https://www.baidu.com/search?a=10&b=10#some console.log(location.href) // https://www.baidu.com/search?a=10&b=10#some console.log(location.protocol) // https: console.log(location.pathname) // /search console.log(location.search) // ?a=10&b=10 console.log(location.hash) // #some
另外,還有調用瀏覽器的前進、後退功能等
history.back()
history.forward()
獲取瀏覽器特性(即俗稱的UA)然後識別客戶端,例如判斷是不是 Chrome 瀏覽器
var ua = navigator.userAgent var isChrome = ua.indexOf('Chrome') console.log(isChrome)
5.Ajax與跨域
Ajax 是一種非同步請求數據的一種技術,對於改善用戶的體驗和程式的性能很有幫助。
簡單地說,在不需要重新刷新頁面的情況下,Ajax 通過非同步請求載入後臺數據,併在網頁上呈現出來。常見運用場景有表單驗證是否登入成功、百度搜索下拉框提示和快遞單號查詢等等。Ajax的目的是提高用戶體驗,較少網路數據的傳輸量。
如何手寫 XMLHttpRequest 不藉助任何庫
var xhr = new XMLHttpRequest() xhr.onreadystatechange = function () { // 這裡的函數非同步執行 if (xhr.readyState == 4) { if (xhr.status == 200) { alert(xhr.responseText) } } } xhr.open("GET", "/api", false) xhr.send(null)
因為瀏覽器出於安全考慮,有同源策略。也就是說,如果協議、功能變數名稱或者埠有一個不同就是跨域,Ajax 請求會失敗。
那麼是出於什麼安全考慮才會引入這種機制呢?其實主要是用來防止 CSRF 攻擊的。簡單點說,CSRF 攻擊是利用用戶的登錄態發起惡意請求。
然後我們來考慮一個問題,請求跨域了,那麼請求到底發出去沒有?請求必然是發出去了,但是瀏覽器攔截了響應。
常見的幾種跨域解決方案(https://github.com/ljianshu/Blog/issues/55):
-
JSONP:利用同源策略對
<script>標簽不受限制,不過只支持GET請求 -
CORS:實現 CORS 通信的關鍵是後端,服務端設置
Access-Control-Allow-Origin就可以開啟,備受推崇的跨域解決方案,比 JSONP 簡單許多 -
Node中間件代理或nginx反向代理:主要是通過同源策略對伺服器不加限制
6.存儲
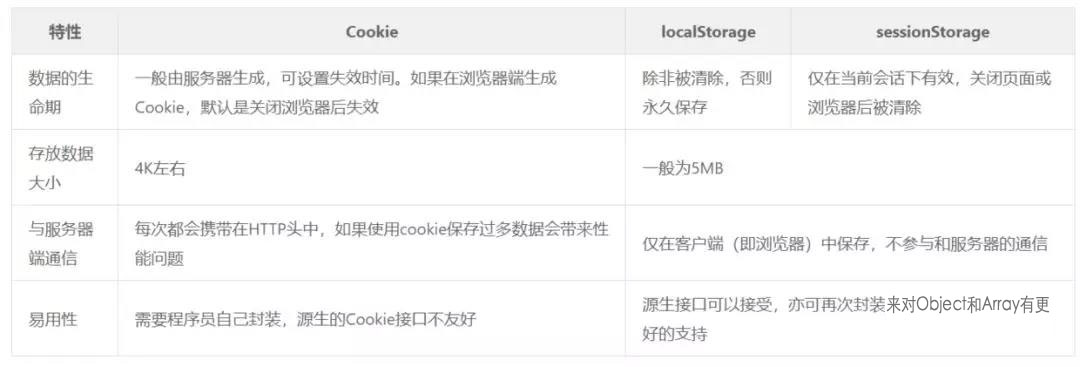
sessionStorage 、localStorage 和 cookie 之間的區別
-
共同點:都是保存在瀏覽器端,且都遵循同源策略。
-
不同點:在於生命周期與作用域的不同
作用域:localStorage只要在相同的協議、相同的主機名、相同的埠下,就能讀取/修改到同一份localStorage數據。sessionStorage比localStorage更嚴苛一點,除了協議、主機名、埠外,還要求在同一視窗(也就是瀏覽器的標簽頁)下

生命周期:localStorage 是持久化的本地存儲,存儲在其中的數據是永遠不會過期的,使其消失的唯一辦法是手動刪除;而 sessionStorage 是臨時性的本地存儲,它是會話級別的存儲,當會話結束(頁面被關閉)時,存儲內容也隨之被釋放。
六、模塊化
幾種常見模塊化規範的簡介
-
CommonJS規範主要用於服務端編程,載入模塊是同步的,這並不適合在瀏覽器環境,因為同步意味著阻塞載入,瀏覽器資源是非同步載入的,因此有了AMD CMD解決方案
-
AMD規範在瀏覽器環境中非同步載入模塊,而且可以並行載入多個模塊。不過,AMD規範開發成本高,代碼的閱讀和書寫比較困難,模塊定義方式的語義不順暢。
-
CMD規範與AMD規範很相似,都用於瀏覽器編程,依賴就近,延遲執行,可以很容易在Node.js中運行。不過,依賴SPM 打包,模塊的載入邏輯偏重
-
ES6 在語言標準的層面上,實現了模塊功能,而且實現得相當簡單,完全可以取代 CommonJS 和 AMD 規範,成為瀏覽器和伺服器通用的模塊解決方案


