
一:模塊的基本認識: 內置模塊是python自帶的功能,在使用內置模塊相應功能時,需要先導入再使用 下載-->安裝-->使用 1.找到python所在的根目錄-->再找到Scripts目錄-->最後找到pip.exe 2.把pip.exe所在的目錄添加到環境變數中 3.pip install 要安裝 ...
一:模塊的基本認識:
- 內置模塊
- 內置模塊是python自帶的功能,在使用內置模塊相應功能時,需要先導入再使用
- 第三方模塊
- 下載-->安裝-->使用
1.找到python所在的根目錄-->再找到Scripts目錄-->最後找到pip.exe 2.把pip.exe所在的目錄添加到環境變數中 3.pip install 要安裝的模塊名稱 #pip install xlrd #安裝完成後,如果導入不成功 - 重啟pycharm - 安裝錯了
- 下載-->安裝-->使用
- 自定義模塊
- 自己寫一個模塊(一個py文件) : aaa.py
def f1(): prinrt('f1') def f2(): print('f2')
- 自己寫一個模塊(一個py文件) : aaa.py
-
- 在另一個py文件中調用模塊中的功能 :a1.py
#調自定義模塊中的功能 import aaa aaa.f1() aaa.f2()
- 運行
a1.py
- 在另一個py文件中調用模塊中的功能 :a1.py
二:模塊的調用
1.示例一:
# xxx.py def show(): print('nihao') def func(): pass print(111)
#導入模塊,載入此模塊中的所有值到記憶體(一) import xxx print(222) ##調用模塊中的函數 xxx.func()
#導入模塊(二) from xxx import func,show from xxx import func from xxx import * func()
#導入模塊(三) from xxx import func as f #起別名 def func(): print(222) f()
2.示例二:
xxxxxx #(某個文件夾) -jd.py #裡面有個f1函數 -tb.py -pdd.py
import xxxxxx.jd jd.f1()
from xxxxxx import jd jd.f1()
from xxxxxx.jd import f1 f1()
3.總結
-
其他推薦:from 模塊 inport 模塊 模塊.函數()
- 其他推薦:from 模塊.模塊 import 函數()
三:內置模塊及其使用方法
-
#獲取6個Unicode對應表中十進位相對應的數據
import random def get_random_code(length = 6): data = [] for i in range(length): v = random.randint(65,90) data.append(chr(v)) return ''.join(data) code = get_random_code() print(code)import random # 導入一個模塊 v = random.randint(起始,終止) #得到一個隨機數
-
用於加密相關的操作,代替了md5模塊和sha模塊
- 將指定的'字元串'進行加密
import hashlib def get_md5(num): obj = hashlib.md5() obj.update(data.encode(utf-8)) result = obj.hexdigest() return result val = get_md5('某段數字') print(val)
- 加鹽 : (讓密碼更加安全)
import hashlib def get_md5(data): # md5括弧內的內容越長,越不容易被破解 obj = hashlib.md5("sidrsicxwersdfsaersdfsdfresdy54436jgfdsjdxff123ad".encode('utf-8')) obj.update(data.encode('utf-8')) result = obj.hexdigest() return result val = get_md5('123') print(val)
- sys : python解釋器相關的數據
- sys.getrefcount : 獲取一個值的應用計數
import sys #導入模塊 a = [1,2,3] b = a print(sys.getrefcount(a)) #結果為:3 相當於a被使用了三次
- sys.getrecursionlimit : python中預設支持的遞歸數量
import sys print(sys.getrecursionlimit()) # 結果為 :1000
- sys.argv : 命令行參數,第一個元素是程式本身路徑
#寫一個腳本,接收兩個參數。
- 第一個參數:文件
- 第二個參數:內容
#請將第二個參數中的內容寫入到 文件(第一個參數)中
import sys if len(sys.argv) < 3: print('參數不夠,請重新運行') else: file_path = sys.argv[1] content = sys.argv[2] with open(file_path,mode='w',encoding='utf-8') as f: f.write(content)
- sys.path : 預設python去導入模塊時,會按照sys.path中的路徑挨個查找
import sys sys.path.append('D:\\') import oldboy
- sys.getrefcount : 獲取一個值的應用計數
- os : 和操作系統相關的數據
- os.path.exists(path) , 如果path存在,返回True;如果path不存在,返回False
-
-
os.path.abspath() : 獲取一個文件的絕對路徑
path = '某個需要查看路徑的文件' import os v1 = os.path.abspath(path) print(v1) # 這個文件所在的全部目錄
- os.path.dirname : 獲取路徑的上級目錄
import os v = r"C:\python36\新建文件夾\python36.exe D:/第三周/day14.py" print(os.path.dirname(v)) #C:\python36\新建文件夾\python36.exe D:/第三周 一級一級往上走
- os.path.join : 路徑的拼接
import os path = "C:\python36\新建文件夾\python36.exe" v = 'n.txt' result = os.path.join(path,v) print(result) #C:\python36\新建文件夾\python36.exe \n.txt result = os.path.join(path,'n1','n2','n3') print(result) #C:\python36\新建文件夾\python36.exe \n1\n2\n3
- os.listdir :查看一個目錄下所有的文件(第一層)
import os result = os.listdir(r'D:\untitled') for i in result: print(i)
- os.walk : 查看一個目錄下所有的文件(所有層)
import os result = os.walk(r'D:\untitled') for a,b,c in result: # a,正在查看的目錄 b,此目錄下的文件夾 c,此目錄下的文件 for item in c: path = os.path.join(a,item) print(path)
-
os.makedirs 創建目錄和子目錄
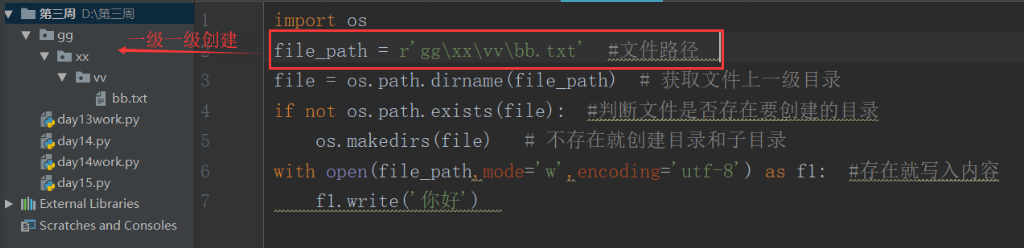
-
- os.rename 重命名
import os os.rename('某個文件的名字','想要修改後的名字')
- os.stat 讀取文件大小
import os #1.讀取文件大小(位元組) file_size = os.stat('某個文件').st_size #2. 一點一點讀取文件 read_size = 0 with open('某個文件',mode='rb') as f1,open('將要寫入的文件',mode='wb') as f2: while read_size < file_size: chunk = f1.read(1024) #每次最多去讀取1024位元組 f2.write(chunk) read_size += len(chunk) val = int(read_size / file_size * 100) #查看列印進度 print('%s%%\r' %val ,end='')
- os.rename 重命名
-
-
-
優點:所有語言通用;缺點:只能序列化基本的數據類型
-
json.dumps 序列化
-
json.loads 反序列化
-
- pickle:優點:python中所有的東西都能被他序列化 缺點:序列化的內容只有python認識
import json #序列化:將python的值轉換為json格式的字元串 v = [11,22,{'k1':'v1'},True,'ggg'] v1 = json.dumps(v) print(v1) #"[11, 22, {"k1": "v1"}, true, "ggg"]" #反序列化 : 將json格式的字元串轉換成python的數據類型 v2 = '["alex",123]' print(type(v2)) #字元串類型 v3 = json.loads(v2) print(v3,type(v3)) #['alex', 123] <class 'list'>
- 字典或列表中如有中文,序列化時想要保留中文顯示
v = {'k1':'alex','k2':'李傑'} import json val = json.dumps(v,ensure_ascii=False) print(val)
-
-
-
-
json 最外層必須是容器類的,如列表/字典,元組會被轉換為列表.
-
裡面的內容可以是:str int bool list tuple 集合不能存在於json中
-
字串必須使用雙引號(" ")連接
-
-
-
-
import shutil shutil.rmtree('要刪除的目錄')
- 重命名
import shutil shutil.move('原目錄','修改後的目錄')
- 壓縮文件 shutil.make_archive
import shutil shutil.make_archive('要壓縮的文件','文件的尾碼名(如zip)','要壓縮到的路徑')
- 解壓文件 shutil.unpack_archive
import shutil shutil.unpack_archive('要解壓的文件',extract_dir=r'D:\code\xxxxxx\xxxx',format='zip')
-
-
-
UTG/GMT 世界時間
-
本地時間 本地時區的時間
-
time :
-
time.time() 時間戳(獲取當前時間) 從1970-1-1 00:00 後走過的秒數
-
time.sleep(8) 等待的秒數
-
- 獲取datetime格式時間
import time from datetime import datetime,timezone,timedelta v1 = datetime.now() # 獲取當前本地時間 print(v1) # 2019-04-18 16:39:31.802269 tz = timezone(timedelta(hours=7)) #當前東7區時間 (如要獲取西7區時間 hours=-7) v2 = datetime.now(tz) print(v2) #2019-04-18 15:39:31.802269+07:00 (中國在東8區,所以慢一個小時) v3 = datetime.utcnow() #當前UTC時間(世界時間) print(v3) #2019-04-18 08:39:31.802269 (比中國時間慢8個小時)
- 把datetime格式轉換成字元串 (strftime)
import time from datetime import datetime,timezone,timedelta v1 = datetime.now() val = v1.strftime("%Y-%m-%d %H:%M:%S") #(年-月-日 時:分:秒) print(val) #2019-04-18 16:48:29
- 字元串轉成datetime格式 datetime.strptime
import time from datetime import datetime,timezone,timedelta v1 = datetime.strptime('2019-4-18','%Y-%m-%d') print(v1,type(v1)) # 2019-04-18 00:00:00 <class 'datetime.datetime'>
- datetime時間的加減
import time from datetime import datetime,timezone,timedelta v1 = datetime.strptime('2008-08-08','%Y-%m-d') v2 = v1-timedelta(days=150) #括弧里的內容可以是:(year+或- month+或-) data = v2.strftime('%Y-%m-%d') print(data) #2008-03-11 #先轉換為datetime格式進行加減,然後轉換為字元串格式列印出來
- 時間戳和datetime的關係
import time from datetime import datetime,timezone,timedelta ctime = time.time() print(ctime) # 1555578896.8276453 v1 = datetime.fromtimestamp(ctime) print(v1) # 2019-04-18 17:14:56.827645 v1 = datetime.now() val = v1.timestamp() print(val) #1555579030.002739
-
四:異常處理
#固定搭配 try: except Exception as e:
#寫函數去,接受一個列表。列表中都是url,請訪問每個地址並獲取結果。 import requests def func(url_list): result = [] try: for url in url_list: response = requests.get(url) result.append(response.text) except Exception as e: pass return result #['http://www.baidu.com'] (中國無法訪問谷歌) def func2(url_list): result = [] for url in url_list: try: response = requests.get(url) result.append(response.text) except Exception as e: pass return result #['http://www.baidu.com','http://www.bing.com'] func(['http://www.baidu.com','http://www.google.com','http://www.bing.com'])


