
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 13) --為什麼數據表刪掉一半,表文件大小不變? 我們還是以MySQL中應用最廣泛的InnoDB引擎為基礎來展開討論。一個表中包含兩部分:表結構定義和數據。在MySQL8.0版本以前 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
13) --為什麼數據表刪掉一半,表文件大小不變?
我們還是以MySQL中應用最廣泛的InnoDB引擎為基礎來展開討論。一個表中包含兩部分:表結構定義和數據。在MySQL8.0版本以前,表結構是以.frm為尾碼的文件存儲的。而在MySQL8.0版本,已經允許把表結構定義放在系統數據表中了。因為表結構定義占用的空間很小,索引我們今天主要討論的是表數據。
參數innodb_file_per_table
表數據既可以放在共用表空間里,也可以單獨存儲在文件里。這個行為是由參數innodb_file_per_table控制的。OFF時表的數據存放在共用表空間里,也就是跟數據字典放在一起。ON時每個表存儲在一個以.ibd為尾碼的文件中。從MySQL5.66版本開始,這個值預設是ON了。建議你無論使用MySQL的哪個版本都將這個值設置為ON,因為單獨存儲為文件的表更方便管理。而且,當你不需要的時候,通過drop table命令,系統就會直接刪除這個文件。而如果是在共用表空間中,即使表刪掉了,空間也是不會回收的。
我們接下來的討論都是基於這個設置展開的。(innodb_file_per_table設置為ON)。
數據刪除流程:
我們在刪除整個表的時候,可以使用drop table命令回收表空間。但是,我們遇到的更多的是刪除某些行,這時就遇到了我們文章開頭的問題:表中的數據被刪除了,但是表空間卻沒有被回收。
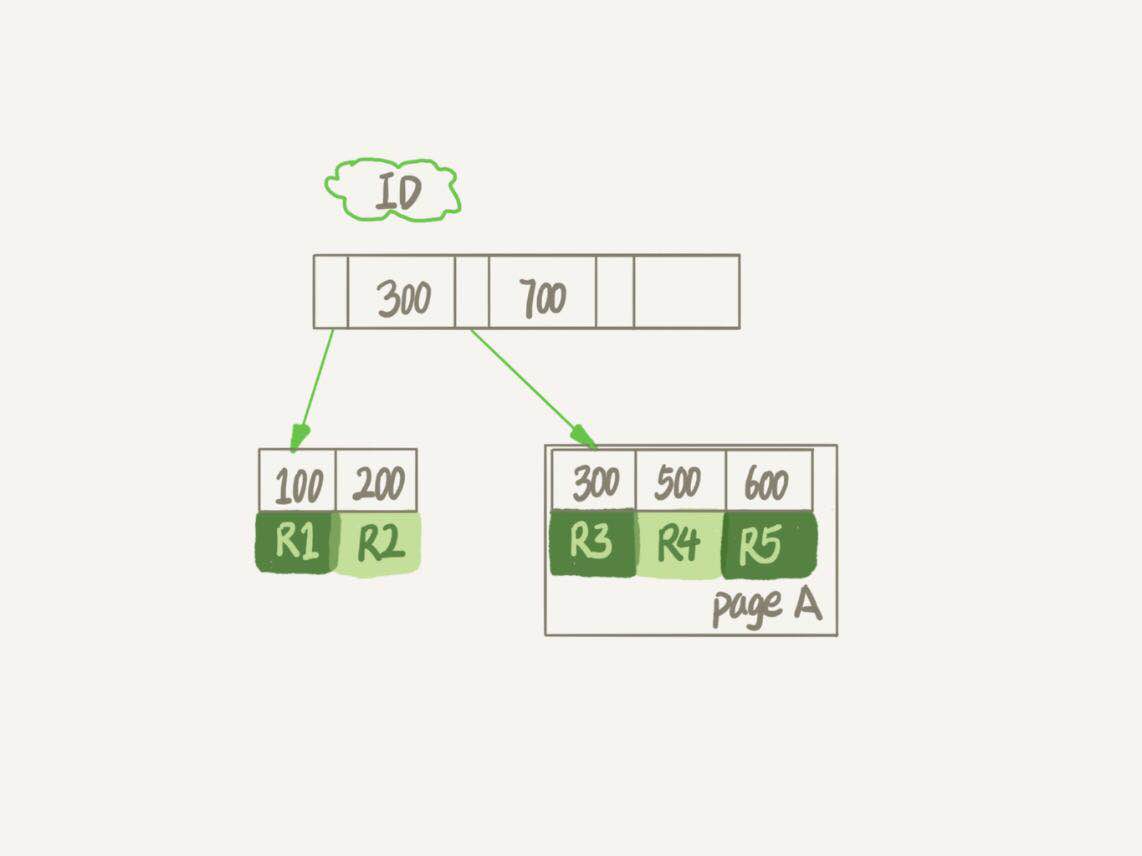
圖1 B+樹索引示意圖
我們之前有提到過,InnoDB里的數據是用B+樹的結構組織的。如果要刪除R4這條記錄,InnoDB引擎會把R4這個記錄標記為刪除。如果之後要插入一個ID在300~600之間的記錄時,可能會復用這個位置。但是,磁碟的大小不會縮小。
我們知道,InnoDB的數據是按頁存儲的,如果我們刪掉一個數據頁上的所有數據會怎樣呢?答案是,整個數據頁都可以被覆用。數據頁復用與行記錄的復用不同,記錄的復用只限於符合範圍條件的數據。比如上面這個例子中,如果插入的ID是400則可以復用,如果ID是800就不能復用記錄的空間。而當整個數據頁都被刪掉時,這個數據頁可以被覆用到任何位置。比如page A上的所有記錄被刪除時,如果要插入一條ID=50的記錄並需要使用新頁時,page A是可以被覆用的。
進一步的說,如果我們使用delete命令把整個表的數據刪除,所有的數據頁都會被標為可復用,但是磁碟上,文件不會變小。你現在知道了,delete命令其實只是把記錄的位置,活著數據頁標記為“可復用”,但磁碟的大小是不會改變的。也就是說,通過delete命令是不能回收表空間的。這些可以復用,而沒有被使用的空間,看起來就像是“空洞”。
實際上,不止是刪除數據會造成空洞,插入數據也會。
如果數據是按照索引遞增順序插入的,那麼索引是緊湊的。但如果數據是隨機插入的,就可能造成索引的數據頁分裂。還使用圖1做例子,假設page A已經滿了,如果我要插入一條ID=550的記錄,由於索引的組織關係,它應該在R4與R5之間。但由於page A已滿,這個插入操作會導致page A分裂成兩個新的數據頁來存儲數據。並且值得註意的是,我們之前假定page A已滿,即這個頁可以存放3條記錄(只是個假設,實際上會遠多於三條記錄),分裂之後的兩個新的數據頁每個都只存放了兩條記錄。這兩個新的數據頁上剩下的空間就是空洞了。實際上,可能不止1個記錄的位置是空洞。
另外,更新索引上的值,可以理解為刪除一個舊的值,再插入一個新的值。不難理解,這也是會造成空洞的。
也就是說,經過大量的增刪改的表,都是可能存在空洞的。所以,如果能夠把這些空洞去掉,就能達到收縮表空間的目的。而重建表,就可以達到這樣的目的。
重建表:
你可以使用alter table A engine=InnoDB命令來重建表。MySQL會自動完成轉存數據,交換表名,刪除舊表的操作。在MySQL5.6版本之前,當在重建表的過程中,如果向舊表插入數據,會造成數據丟失,因此整個DDL過程中,舊表是不能有更新的。也就是整個DDL不是Online的。而在這個版本開始引入了Online DDL,對這個操作流程做了優化。
- 建立一個臨時表A(舊表),掃描表A主鍵的所有數據頁。
- 用數據頁中表A的記錄生成B+樹,存儲到臨時文件中
- 生成臨時文件的過程中,將所有對A的操作記錄在一個日誌文件中(row log)
- 臨時文件生成後,將日誌文件中的操作應用到臨時文件,得到一個邏輯數據上與表A相同的數據文件,對應的就是同種state3的狀態。
- 用臨時文件替換表A的數據文件。
這個過程還存在一個細節。我們知道,alter語句在啟動的時候需要獲取MDL寫鎖。這樣還能叫Online嘛?其實,這個寫鎖在真正拷貝數據之前就會退化成讀鎖。為什麼要退化呢?為了實現Online,MDL讀鎖不會阻塞增刪改操作。那麼為什麼不直接就用讀鎖呢?為了保護自己,禁止除自身外其他線程對這個表同時做DDL。而相對來講,這個過程中最耗時的是拷貝數據到臨時表的過程。因此對於整個DDL過程來說,鎖的時間非常短,可以認為是Online的。
需要額外說明的是,對於大表來說,這個操作很消耗IO和CPU資源,因此,如果是線上服務,你要小心地控制操作時間。
Online和inplace:
對於非Online模式,在重建表A的時候,會生成一個tmp table用來存放導出的數據。這個一個臨時表,是在server層創建的。而Online模式,表A重建出來的數據是放在“tmp_file”里的,這個臨時文件是InnoDB在內部創建出來的。整個DDL過程都在InnoDB內部完成。對於Server層來說,沒有把數據挪動到臨時表,是一個“原地”操作,這就是“inplace”名稱的來源。因此,如果你有一個1TB的表,現在磁碟間是1.2TB,能不能做一個inplace的DDL呢?答案是不能。因為,tmp_file也是要占用臨時空間的。我們重建表的語句alter table t engine = InnoDB,其實隱含的含義是:alter table t engine = InnoDB,ALGORITHM=inplace;跟inplace對應的是拷貝表的方式,用法是alter table t engine = InnoDB,ALGORITHM=copy;而強制拷貝表即off line 方式。
因此,舉一個例子,我要給InnoDB表的一個欄位加全文索引,寫法是alter table t add FULLTEX(filed_name);整個過程是inplace的,但會阻塞增刪改操作,是非Online的。
DDL過程如果是Online的,就一定是inplace的。
反過來未必,也就是說inplace的DDL,有可能不是Online的。截止到MySQL8.0,添加全文索引(FULLTEXT index)可空間索引(SPATIAL index)就屬於這種情況。
上期問題:
一個記憶體配置為128GB,innodb_io_capacity設置為20000的大規格實例,正常會建議你將redo log設置成4個1GB的文件,但是如果你配置時不小心將redo log設置為了4個100M的文件,會發生什麼情況呢?為什麼呢?
對於一個高配置的機器,如果redo log設置太小,很快就會被寫滿。也就是會不停地去移動redo log中的checkpoint,這個checkpoint可以表示哪些內容是已經更新到硬碟可以去掉的位置。而要移動check point就要去刷臟頁,這時系統不得不停止所有更新。所以你會看到磁碟壓力很小,但是資料庫出現間歇性的性能下跌。
問題:
如果有一個情況是這樣的:想要收縮表空間,結果適得其反,看上去是:
- 一個表t文件大小為1TB;
- 對這個表執行alter table t engine = InnoDB;
- 執行完成後,空間不僅沒有變小,還稍微大了一點,變為了1.01TB
請問這是什麼原因導致的呢?


