
目前是剛剛初學完zookeeper,這篇文章主要是簡單的對一些基本的概念進行梳理強化。 zookeeper基礎概念的理解 有時候電腦領域很多名詞都是從一長串英文提取首字母縮寫而來,但很不幸zookeeper不是。那麼,zookeeper到底是用來乾什麼的?我這裡先擺一段官網的介紹: ZooKeep ...
-
zookeeper基礎概念的理解
有時候電腦領域很多名詞都是從一長串英文提取首字母縮寫而來,但很不幸zookeeper不是。那麼,zookeeper到底是用來乾什麼的?我這裡先擺一段官網的介紹:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.(官網鏈接:http://zookeeper.apache.org)
由於目前還沒有實際項目使用zookeeper的經驗,針對上述的情況,目前只是對configuration、distributed synchronization有比較清楚的一個認識,認識到什麼程度就先記錄到什麼程度,後期有更加深刻的認識後還會修改更新。首先,要明確兩點,第一,zk是在分散式場景中使用,第二,主要的工作就是任務進程的協調調度。在多個應用訪問同一個資源的情況下會出現資源競爭,例如一個是查詢餘額操作、一個是取錢操作、一個是存錢操作,這三個操作不可能放任不管讓其自動操作,那麼就會出現一個用於協調任務的調度器,zk就扮演這樣一個角色,當然這隻是其中一種應用-分散式鎖,zk的其他應用還包括配置維護、分散式消息隊列、分散式通知等。
-
zk的基本數據模型
zk的基本數據模型與Linux文件系統具有相似的結構,其中每一個節點稱為znode,每一個znode都包含有兩部分內容:
-
數據(預設最大存儲空間為1MB,是原子操作)
-
元數據信息,包括cZxid、ctime、mtimp、pZxid等節點屬性信息

-

-
節點類型
znode的類型在創建時就確定唯一,不可改變,包括:
-
臨時節點、臨時有序節點
-
永久節點、永久有序節點
臨時性的節點生命周期取決於會話(session),會話結束節點自動消失,同時臨時性節點不允許有子節點。永久性節點不依賴於會話,只有執行刪除操作後才會消失。
-
-
watch機制
客戶端可以通過設置watcher來監視節點的增、刪、改等狀態變化,當watcher被觸發時,客戶端會收到一條通知,考慮到需要減小網路數據傳輸流量,一個watcher只能被觸發一次,要想多次觸發,需要在觸發執行的代碼中再次設置watcher。
-
應用場景
-
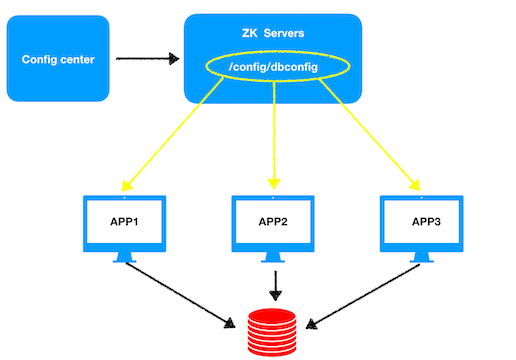
配置管理
在一個分散式的系統中,每台機器運行一個app,app需要讀取資料庫的信息,而app與資料庫連接需要相應的資料庫信息,如ip地址、埠等,這個信息就可以通過一個配置文件存儲在配置中心中,配置中心將配置信息寫入znode的數據中進行存儲,同時每個app會在相應的節點上註冊一個watcher。一旦配置信息改變,配置中心將新的數據寫入到節點中之後,watch機制觸發,相應的app就會更改連接資料庫所需的信息重新與資料庫建立連接。

-
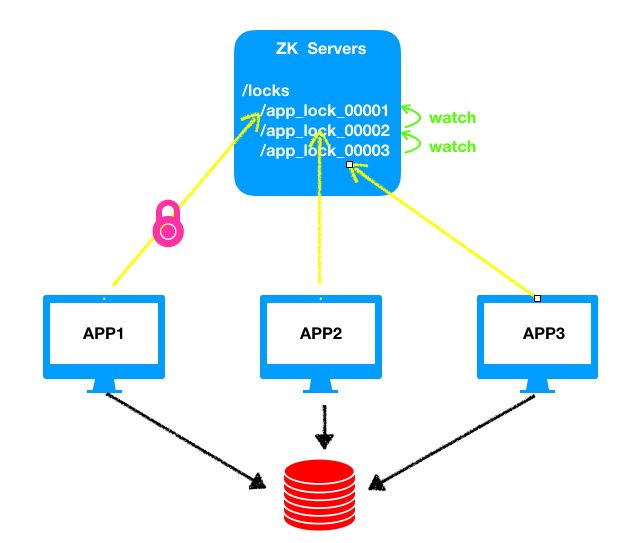
分散式鎖
假設同一時間只能允許一個任務訪問資料庫中的某條數據,那麼首先各個app會在ZK上註冊一個自己的臨時節點比如節點分別為/app_lock_00001、/app_lock_00002、/app_lock_00003,我們設置序號最小的節點獲得鎖,即/app_lock_00001,同時/app_lock_00002監聽/app_lock_00001,/app_lock_00003監聽/app_lock_00002,此時app1開始執行訪問數據的操作,執行完成後斷開連接,臨時節點消失,/app_lock_00002節點監聽到之後app2開始執行,同樣的操作一直到app3執行完畢。

-
-
zk各台機器節點之間的角色
zk中各個機器節點之間的角色有:leader、follower、observe,三種,先不考慮observer,哪台節點是leader、哪些是follower是通過選舉機制決定的。具體來講有兩種選舉機制:
-
client端在連接zk servers的時候,會創建臨時節點,根據client端與zk servers創建節點的時間順序,哪一個先創建,哪一個作為leader,其他的就是follower。
-
client端在連接zk servers的時候,會創建臨時有序節點,根據節點序號的大小,最小的為leader,其它為follower,並依次監聽比當前節點號小的節點
zk運行正常情況下有以下特點:
-
客戶端可隨便連接其中的一臺機器節點
-
客戶端可以同時連接多台機器,實現連接的冗餘
-
與事務(增、刪、改)有關的操作會通過follower轉發至leader,查詢操作直接由所連接的伺服器負責響應。
那麼,對於事務操作轉發給leader之後是如何進行的呢?首先,leader收到事務操作之後提出一個Proposal,其它的follower負責投票,leader收集投票之後如果超過半數,那麼這次提議成功,同時響應對應的事務操作。同時發送消息給follower,follower接收消息之後會把操作更新至記憶體,最後響應client端。加入client數量不斷增加的話,zk servers有可能就滿足不了客戶端訪問的需求,而leader只有一個,那麼就只能添加機器作為follower角色。依照這個邏輯,follower會不斷增加,那麼就會出現一個問題:一旦出現事務操作,leader要搜集半數以上的投票,follower越多,收集過程就會越慢。為瞭解決這個問題,在zookeeper3.3.3版本後引入了observer角色,observer不參與投票,但是其他方麵包括轉發事務操作、響應客戶端查詢操作都與follower一樣,這樣在增加機器的同時就不會因為投票規則而影響整體的響應性能。
以上是一個基本的認識,深入的細節可以參考博文:
-

