
HBase是建立在Hadoop文件系統之上的分散式面向列的資料庫。它是一個開源項目,是橫向擴展的。 HBase是一個數據模型,類似於谷歌的大表設計,可以提供快速隨機訪問海量結構化數據。它利用了Hadoop的文件系統(HDFS)提供的容錯能力。 它是Hadoop的生態系統,提供對數據的隨機實時讀/寫訪 ...
1) HBase是什麼?
HBase是建立在Hadoop文件系統之上的分散式面向列的資料庫。它是一個開源項目,是橫向擴展的。
HBase是一個數據模型,類似於谷歌的大表設計,可以提供快速隨機訪問海量結構化數據。它利用了Hadoop的文件系統(HDFS)提供的容錯能力。
它是Hadoop的生態系統,提供對數據的隨機實時讀/寫訪問,是Hadoop文件系統的一部分。
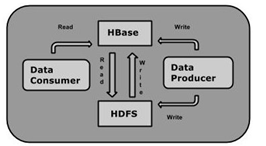
人們可以直接或通過HBase的存儲HDFS數據。使用HBase在HDFS讀取消費/隨機訪問數據。 HBase在Hadoop的文件系統之上,並提供了讀寫訪問。
2) HBase的存儲機制
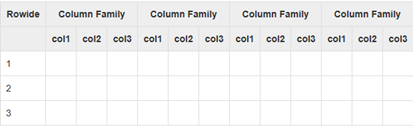
HBase是一個面向列的資料庫,在表中它由行排序。表模式定義只能列族,也就是鍵值對。一個表有多個列族以及每一個列族可以有任意數量的列。後續列的值連續地存儲在磁碟上。表中的每個單元格值都具有時間戳。
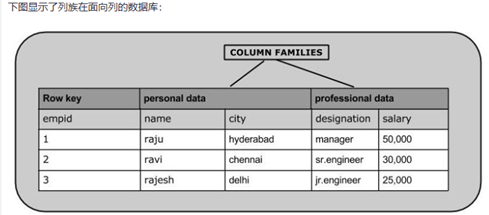
總之,在一個HBase:表是行的集合à行是列族的集合à列族是列的集合à列是鍵值對的集合,如圖:
3) Hbase的特點
- 建立在HDFS之上,面向列的針對結構化數據的可伸縮、高可靠、高性能、分散式列存儲的動態模式資料庫,列式資料庫(nosql)專門解決hadoop不擅長的工作。
- 採用BigTable的數據模型。增強的稀疏排序映射表(Key/Value),其中“鍵”是由行關鍵字、列關鍵字、時間截構成。
- 提供對大規模數據的隨機、實時讀寫訪問功能,其保存的數據可通過MapReduce處理。
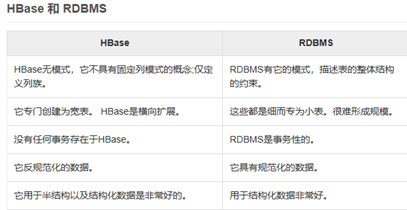
4) 行資料庫與列資料庫的區別

5) hbase表特點:
- 表比較大,一個表有數十億行,上百萬列;
- 無模式:每行都有一個可排序的主鍵和任意多的列,列可以根據需要冬天的增加,同一張表中的行也已有截然不同的列;
- 稀疏:空值列並不占用存儲空間,列獨立檢索;
- 數據多版本:每個單元中的數據可以有多個版本,預設情況下版本號自動分配,是單元格插入時間戳;
- 數據類型單一:數據都是字元串,沒有類型
6) 存儲核心—Hstore
Hstore分為menstore和storefiles兩部分。
用戶寫入的數據首先會放入MemStore,當MemStore滿了以後會Flush成一個StoreFile(底層實現是HFile),當StoreFile文件數量增長到一定閾值,會觸發Compact合併操作,將多個StoreFiles合併成一個StoreFile,合併過程中會進行版本合併和數據刪除
HBase其實只有增加數據,所有的更新和刪除操作都是在後續的compact過程中進行的,這使得用戶的寫操作只要進入記憶體中就可以立即返回,保證了HBase I/O的高性能架構。
7) Hbase架構
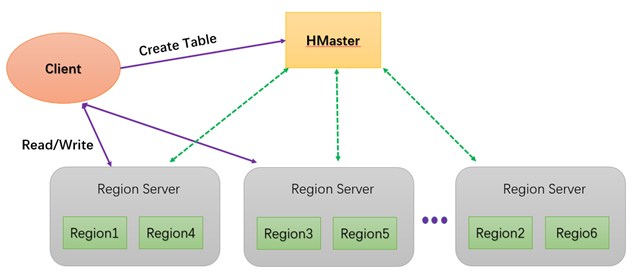
一個HMaster(管理伺服器)控制多個Region Server(數據伺服器);
- HMater負責表的創建、刪除、維護以及Region的分配和負載均衡;
- Region Server負責管理維護Region以及響應讀寫請求;
- 客戶端與HMaster進行有關表的元數據操作,之後直接讀寫Region servers。
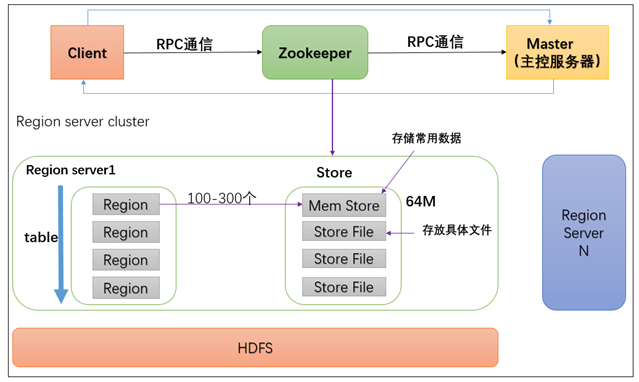
Master職責:
1. 為regionserver分配region;
2. 負責regionserver的負載均衡;
3. 垃圾文件回收;
4. 處理schema請求
Zookeeper職責:
- 保證集群只有一個Master;
- 監控Region Server狀態,實時通知Master;
- Hbase目錄入口地址;
- Hbase的Schema信息
Region職責:
- 對數據的讀寫支持;
- 對region管理的支持;
- Hbase目錄入口地址;
- Hbase的Schema信息
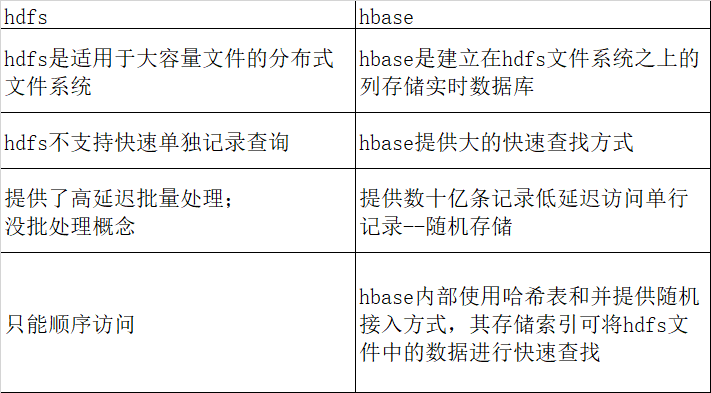
8) HBase 和 HDFS關係
9) hive與hbase區別
相同點:都是架構在hadoop之上,都是用hadoop作為底層存儲
不同點:
Hive:
- 是批處理系統,目的是檢索MapReduce jobs的編寫工作;
- 是純邏輯表並且是全表掃描,本身不存儲和計算數據,完全依賴HDFS和MapReduce;
- 時效性低
Hbase:
- 是實時操作系統,目的是彌補hadoop的缺陷項目;
- 是物理表,採用列存儲索引數據或實時數據,提供超大的記憶體hash表;
- 高時效性。


