
1.1.1 hive是什麼? Hive是基於 Hadoop 的一個數據倉庫工具: 1.1.2 hive和Hadoop關係 Hive利用HDFS存儲數據,利用MapReduce查詢數據,聚合函數需要經過MapReduce,非聚合函數直接讀取hdfs塊信息,不通過MapReduce。 1.1.3 hiv ...
1.1.1 hive是什麼?
Hive是基於 Hadoop 的一個數據倉庫工具:
- 1. hive本身不提供數據存儲功能,使用HDFS做數據存儲;
- 2. hive也不分散式計算框架,hive的核心工作就是把sql語句翻譯成MR程式;
- 3. hive也不提供資源調度系統,也是預設由Hadoop當中YARN集群來調度;
- 4. 可以將結構化的數據映射為一張資料庫表,並提供 HQL(Hive SQL)查詢功能。
1.1.2 hive和Hadoop關係
Hive利用HDFS存儲數據,利用MapReduce查詢數據,聚合函數需要經過MapReduce,非聚合函數直接讀取hdfs塊信息,不通過MapReduce。
1.1.3 hive特點
- 可以將結構化的數據文件映射為一張資料庫表(二維表),並提供類SQL查詢功能
- 可以將sql語句轉換為MapReduce任務進行運行。Hive 將用戶的HiveQL 語句通過解釋器轉換為MapReduce 作業提交到Hadoop 集群上,Hadoop 監控作業執行過程,然後返回作業執行結果給用戶。
- Hive 在載入數據過程中不會對數據進行任何的修改,只是將數據移動到HDFS 中Hive 設定的目錄下,因此,Hive 不支持對數據的改寫和添加,所有的數據都是在載入的時候確定的。
- Hive的適應場景:只適合做海量離線數據的統計分析。
- Hive中所有的數據都存儲在 HDFS 中,沒有專門的數據存儲格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
- 只需要在創建表的時候告訴 Hive 數據中的列分隔符和行分隔符,Hive 就可以解析數據。
- Hive 中包含以下數據模型:DB、Table,External Table,Partition,Bucket。
1.1.4 hive數據的存儲
db:在hdfs中表現為${hive.metastore.warehouse.dir}目錄下一個文件夾
table:在hdfs中表現所屬db目錄下一個文件夾
external table:與table類似,不過其數據存放位置可以在任意指定路徑
partition:在hdfs中表現為table目錄下的子目錄
bucket:在hdfs中表現為同一個表目錄下根據hash散列之後的多個文件
1.1.5 Hive 體繫結構
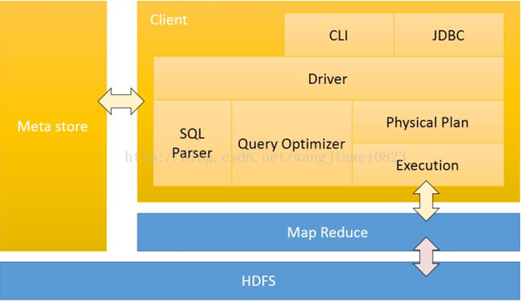

1.1.6 hive的架構原理
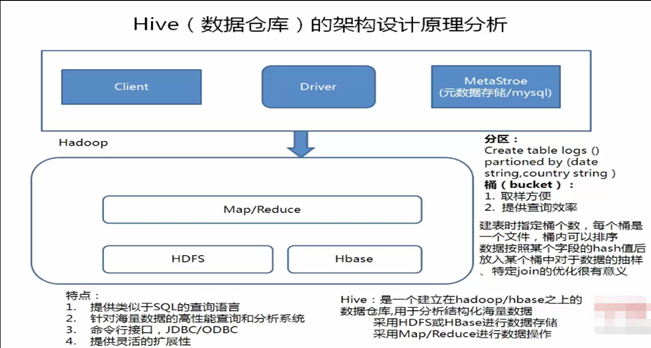
Driver是核心,Driver可以解析語法,最難的就是解析sql的語法,只要把SQL的語法解析知道怎麼做了,它內部用MapReduce模板程式,它很容易把它組裝起來,比如做一個join操作,最重要的是識別語法,認識你的語法,知道你語法有什麼東西,解析出來會得到一個語法樹,根據一些語法樹,去找一些MapReduce模板程式,把它組裝起來。
例如:有二個表去join,內部有一個優化機制,有一個預設值,如果小表小於預設值,就採用map—join ,如果小表大於預設值,就採用reduce——join(其中map——join是先把小表載入到記憶體中),組裝時候就是輸入一些參數:比如:你的輸入數據在哪裡,你的表數據的分隔符是什麼,你的文件格式是什麼:然而這些東西是我們建表的時候就指定了,所以這些都知道了,程式就可以正常的跑起來。
Hive有了Driver之後,還需要藉助Metastore,Metastore裡邊記錄了hive中所建的:庫,表,分區,分桶的信息,描述信息都在Metastore,如果用了MySQL作為hive的Metastore:需要註意的是:你建的表不是直接建在MySQL里,而是把這個表的描述信息放在了MySQL里,而tables表,欄位表是存在HDFS上的hive表上,hive會自動把他的目錄規劃/usr/hive/warehouse/庫文件/庫目錄/表目錄,你的數據就在目錄下
1.1.7 內外表
內部表在刪除表的時候,會刪除元數據和數據;外部表在刪除表的時候,只刪除元數據,不刪除數據
內部表和外部表使用場景:
- 一般情況來說,如果數據只交給hive處理,那麼一般直接使用內部表;
- 如果數據需要多個不同的組件進行處理,那麼最好用外部表,一個目錄的數據需要被spark、hbase等其他組件使用,並且hive也要使用,那麼該份數據通過創建一張臨時表為外部表,然後通過寫HQL語句轉換該份數據到hive內部表中
1.1.8 分桶
分桶操作:按照用戶創建表時指定的分桶欄位進行hash散列,跟MapReduce中的HashPartitioner的原理一模一樣。
MapReduce中:按照key的hash值去模除以reductTask的個數;Hive中:按照分桶欄位的hash值去模除以分桶的個數
hive分桶操作的效果:把一個文件按照某個特定的欄位和桶數散列成多個文件好處:
1、方便抽樣;
2、提高join查詢效率
1.1.9 Hive分區
做統計的時候少統計,把我們的數據放在多個文件夾裡邊,我們統計時候,可以指定分區,這樣範圍就會小一些,這樣就減少了運行的時間。
1.1.10 Hive 的所有跟數據相關的概念
db: myhive, table: student 元數據:hivedb
Hive的元數據指的是 myhive 和 student等等的庫和表的相關的各種定義信息,該元數據都是存儲在mysql中的:
- myhive是hive中的一個資料庫的概念,其實就是HDFS上的一個文件夾,跟mysql沒有多大的關係;
- myhive是hive中的一個資料庫,那麼就會在元資料庫hivedb當中的DBS表中存儲一個記錄,這一條記錄就是myhive這個hive中數據的相關描述信息。
- hive中創建一個庫,就相當於是在hivedb中DBS(資料庫)中插入一張表, 並且在HDFS上建立相應的目錄—主目錄;
- hive中創建一個表,就相當於在hivedb中TBLS(資料庫中的表)表中插入一條記錄,並且在HDFS上項目的庫目錄下創建一個子目錄;
- 一個hive數據倉庫就依賴於一個RDBMS(關係資料庫管理系統)中的一個資料庫,一個資料庫實例對應於一個Hive數據倉庫;
- 存儲於該hive數據倉庫中的所有數據的描述信息,都統統存儲在元資料庫hivedb中。
- Hive元數據 :描述和管理這些block信息的數據,由namenode管理,一定指跟 hivedb相關,跟mysql相關;
- Hive源數據-- block塊: HDFS上的對應表的目錄下的文件HDFS上的數據和元數據。
1.1.11 源數據與元數據
myhive 和 hivedb的區別:
- myhive是hive中的資料庫: 用來存儲真實數據—源數據;
- hivedb是mysql中的資料庫: 用來多個類似myhive庫的真實數據的描述數據—元數據;
1.1.12 Hive基本命令整理
創建表:CREATE TABLE pokes (foo INT, bar STRING);
Creates a table called pokes with
two columns, the first being an integer and the other a string
創建一個新表,結構與其他一樣
hive> create table new_table like records;
創建分區表:
hive> create table logs(ts bigint,line string) partitioned by (dt
String,country String);
載入分區表數據:
hive> load data local inpath '/home/hadoop/input/hive/partitions/file1' into
table logs partition (dt='2001-01-01',country='GB');
展示表中有多少分區:
hive> show partitions logs;
展示所有表:
hive> SHOW TABLES;
lists all the tables
hive> SHOW TABLES '.*s';
lists all the table that end with 's'.
The pattern matching follows Java regular
expressions. Check out this link for documentation
顯示表的結構信息
hive> DESCRIBE invites;
shows the list of columns
更新表的名稱:
hive> ALTER TABLE source RENAME TO target;
添加新一列
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
刪除表:
hive> DROP TABLE records;
刪除表中數據,但要保持表的結構定義
hive> dfs -rmr /user/hive/warehouse/records;
從本地文件載入數據:
hive> LOAD DATA LOCAL INPATH '/home/hadoop/input/ncdc/micro-tab/sample.txt'
OVERWRITE INTO TABLE records;
顯示所有函數:
hive> show functions;
查看函數用法:
hive> describe function substr;
查看數組、map、結構
hive> select col1[0],col2['b'],col3.c from complex;
其他同oracle相同
1.1.13 hive環境搭建
hive的元數據是存放在mysql中的,首先需要安裝mysql資料庫;然後修改hive配置文件,主要是資料庫用戶、密碼、hadoop文件存放的路徑等等。--請看mysql的環境搭建


