
selenium-獲取一組數組進行操作 以 縱橫中文網 中獲取24小時暢銷榜的書單為例 此文僅做 selenium 在自動化測試中怎麼獲取一組數據進行說明,不做網路爬蟲解釋 當然,使用爬蟲得到本文的結果會簡單快捷的多 區別 selenium 中的 elements 與 element 例如:list ...
selenium-獲取一組數組進行操作
以 縱橫中文網 中獲取24小時暢銷榜的書單為例
此文僅做 selenium 在自動化測試中怎麼獲取一組數據進行說明,不做網路爬蟲解釋
當然,使用爬蟲得到本文的結果會簡單快捷的多
區別 selenium 中的 elements 與 element
例如:list.find_elements_by_class_name('rank_i_bname') # 獲得 class name 為 rank_i_bname 的所有數據
list.find_element_by_class_name('rank_i_p_tit') # # 獲得 class name 為 rank_i_p_tit 的一個數據,如果有多個則只取第一個
步驟:
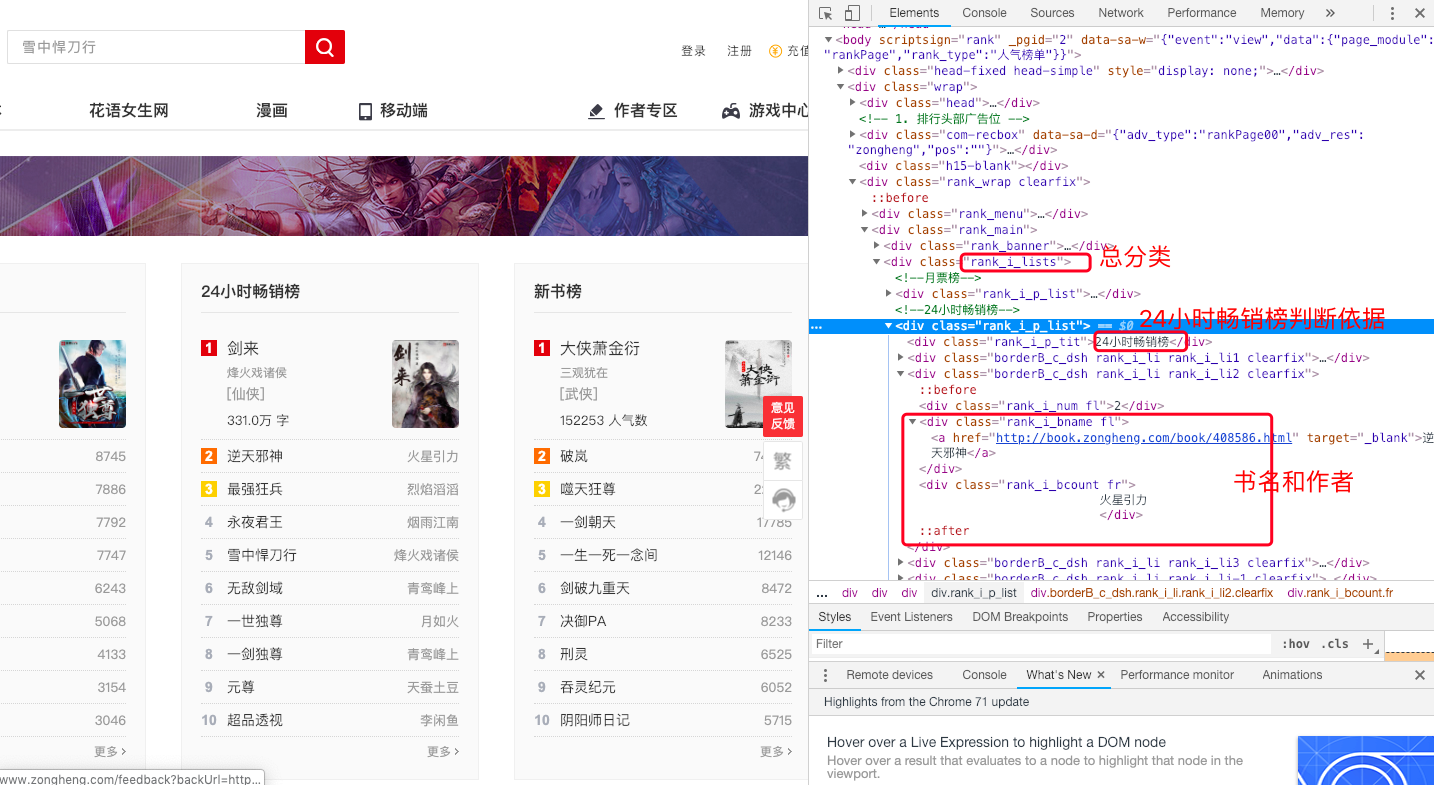
使用 selenium 定位到總分類
然後通過判斷24小時暢銷榜,進入到24小時暢銷榜的書目錄
最後獲得書名和作者
如下圖
代碼如下:
1 #coding=utf-8 2 3 from selenium import webdriver 4 import unittest 5 6 7 class getListall(unittest.TestCase): 8 9 def setUp(self): 10 11 # 縱橫小說中文網 12 base_url = 'http://book.zongheng.com/rank.html' 13 self.driver = webdriver.Chrome() 14 self.driver.implicitly_wait(10) 15 self.driver.get(base_url) 16 17 def test_get_list_all(self): 18 u"""獲取數組""" 19 driver = self.driver 20 # 獲取所有分類 21 lists = driver.find_elements_by_class_name('rank_i_p_list') 22 for list in lists: 23 # 獲取24小時暢銷榜下的書 24 if list.find_element_by_class_name('rank_i_p_tit').text == "24小時暢銷榜": 25 26 # 獲取書 27 names = list.find_elements_by_class_name('rank_i_bname') 28 authors = list.find_elements_by_class_name('rank_i_bcount') 29 30 # 列印獲取的數據 31 for name,author in zip(names,authors): 32 print(name.text + "," + author.text + ";") 33 34 35 def tearDown(self): 36 self.driver.quit() 37 38 39 if __name__ == '__main__': 40 unittest.main()
運行結果
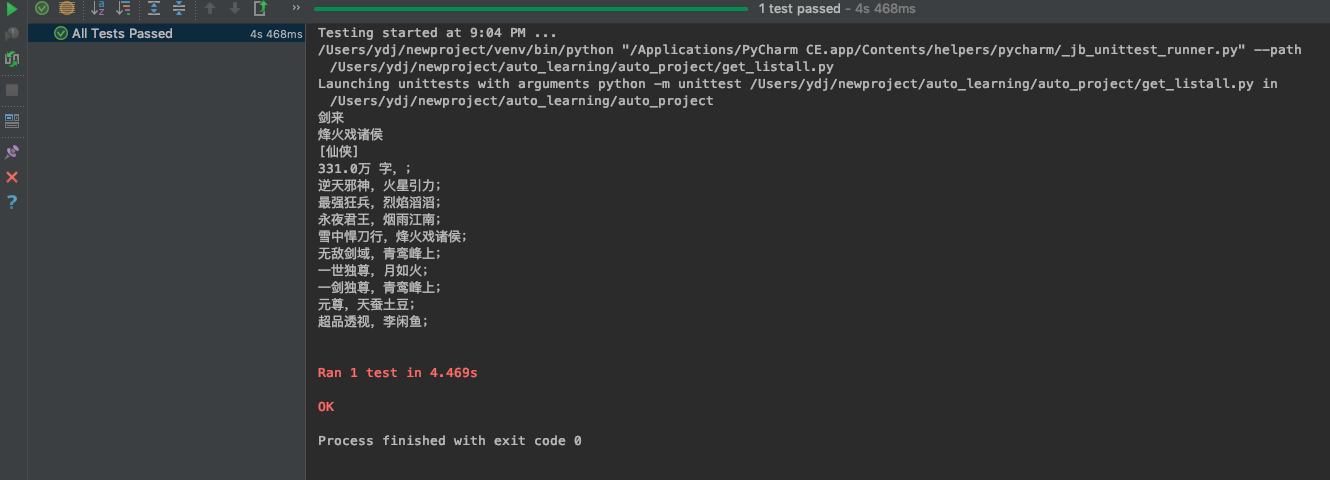
結果分析
分析結果會發現,第一個書單所獲取的信息和其他的書單信息不一致
原因:查看網頁html便可知
class=“rank_i_bname” 下的 text ,第一個書單和其他書單的信息是不一樣的
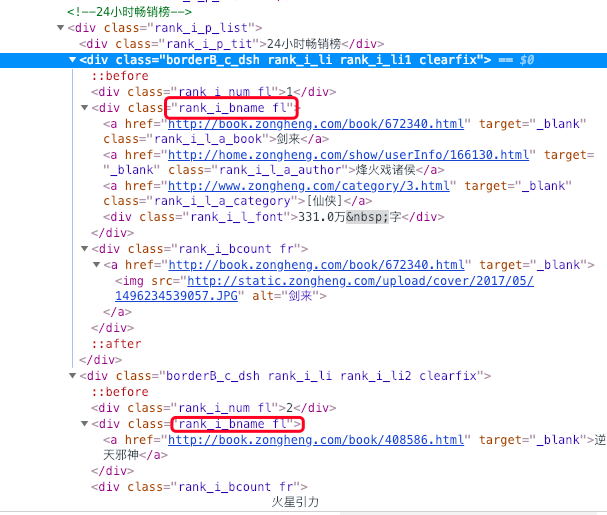
如果看起來不美觀可以將第一個書單提取處理單獨進行定位獲取信息進行列印
然後在 for 迴圈中將獲取到的書單的第一個信息不要列印
問題解決


