
前面我們已經實現了七種模型,接下來我們分別會對這七種進行評估,主要通過auccuracy,precision,recall,F1-score,auc。最後畫出各個模型的roc曲線 接下來分別看看各個評分的意義 accuracy(準確率) 對於給定的測試數據集,分類器正確分類的樣本數與總樣本數之比。也 ...
前面我們已經實現了七種模型,接下來我們分別會對這七種進行評估,主要通過auccuracy,precision,recall,F1-score,auc。最後畫出各個模型的roc曲線
接下來分別看看各個評分的意義
accuracy(準確率)
對於給定的測試數據集,分類器正確分類的樣本數與總樣本數之比。也就是損失函數是0-1損失時測試數據集上的準確率。比如有100個數據,其中有70個正類,30個反類。現在分類器分為50個正類,50個反類,也就是說將20個正類錯誤的分為了反類。準確率為80/100 = 0.8
precision(精確率)
表示被”正確被檢索的item(TP)"占所有"實際被檢索到的(TP+FP)"的比例.,這個指標越高,就表示越整齊不混亂。比如還是上述的分類中。在分為反類中有30個分類正確。那麼精確率為30/50 = 0.6
recall(召回率)
所有"正確被檢索的item(TP)"占所有"應該檢索到的item(TP+FN)"的比例。在上述的分類中正類的召回率為50/70 = 0.71。一般情況下準確率高、召回率就低,召回率低、準確率高
F1-score
統計學中用來衡量二分類模型精確度的一種指標。它同時兼顧了分類模型的準確率和召回率。F1分數可以看作是模型準確率和召回率的一種加權平均,它的最大值是1,最小值是0。
![]()
auc
ROC曲線下與坐標軸圍成的面積
模型評估
先導入所需要的包
import pandas as pd import numpy as py import matplotlib.pyplot as plt from xgboost import XGBClassifier from sklearn.metrics import roc_auc_score from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import roc_curve,auc from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from lightgbm import LGBMClassifier from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn import svm data_all = pd.read_csv('D:\\data_all.csv',encoding ='gbk') X = data_all.drop(['status'],axis = 1) y = data_all['status'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=2018) #數據標準化 scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下定義一個函數實現了評價的方法以及畫出了roc曲線
def assess(y_pre, y_pre_proba): acc_score = accuracy_score(y_test,y_pre) pre_score = precision_score(y_test,y_pre) recall = recall_score(y_test,y_pre) F1 = f1_score(y_test,y_pre) auc_score = roc_auc_score(y_test,y_pre_proba) fpr, tpr, thresholds = roc_curve(y_test,y_pre_proba) plt.plot(fpr,tpr,'b',label='AUC = %0.4f'% auc_score) plt.plot([0,1],[0,1],'r--',label= 'Random guess') plt.legend(loc='lower right') plt.title('ROCcurve') plt.xlabel('false positive rate') plt.ylabel('true positive rate') plt.show()
接著我們分別對這七種模型進行評估以及得到的roc曲線圖
#LR lr = LogisticRegression(random_state = 2018) lr.fit(X_train, y_train) pre_lr = lr.predict(X_test) pre_porba_lr = lr.predict_proba(X_test)[:,1] assess(pre_lr,pre_porba_lr)
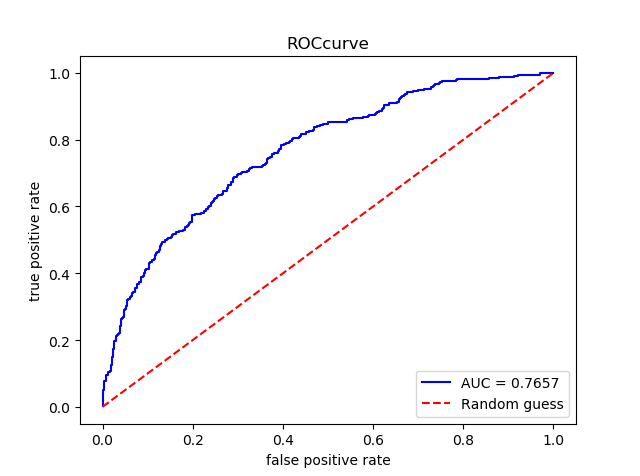
#DecisionTree dt = DecisionTreeClassifier(random_state = 2018) dt.fit(X_train , y_train) pre_dt = dt.predict(X_test) pre_proba_dt = dt.predict_proba(X_test)[:,1] assess(pre_dt,pre_proba_dt)

#SVM svc = svm.SVC(random_state = 2018) svc.fit(X_train , y_train) pre_svc = svc.predict(X_test) pre_proba_svc = svc.decision_function(X_test) assess(pre_svc,pre_proba_svc)

#RandomForest rft = RandomForestClassifier() rft.fit(X_train,y_train) pre_rft = rft.predict(X_test) pre_proba_rft = rft.predict_proba(X_test)[:,1] assess(pre_rft,pre_proba_rft)

#GBDT gb = GradientBoostingClassifier() gb.fit(X_train,y_train) pre_gb = gb.predict(X_test) pre_proba_gb = gb.predict_proba(X_test)[:,1] assess(pre_gb,pre_proba_gb)
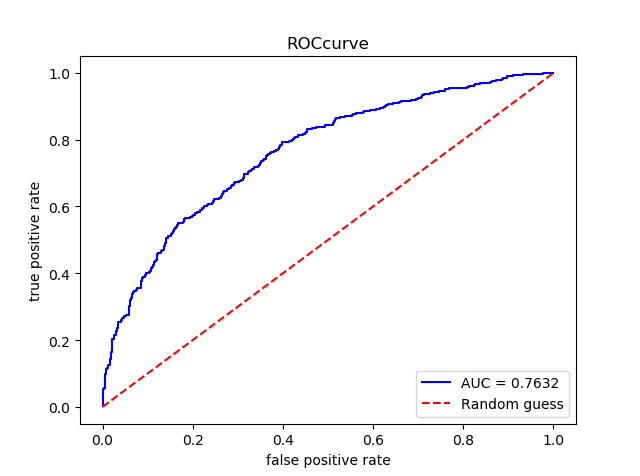
#XGBoost xgb_c = XGBClassifier() xgb_c.fit(X_train,y_train) pre_xgb = xgb_c.predict(X_test) pre_proba_xgb = xgb_c.predict_proba(X_test)[:,1] assess(pre_xgb,pre_proba_xgb)
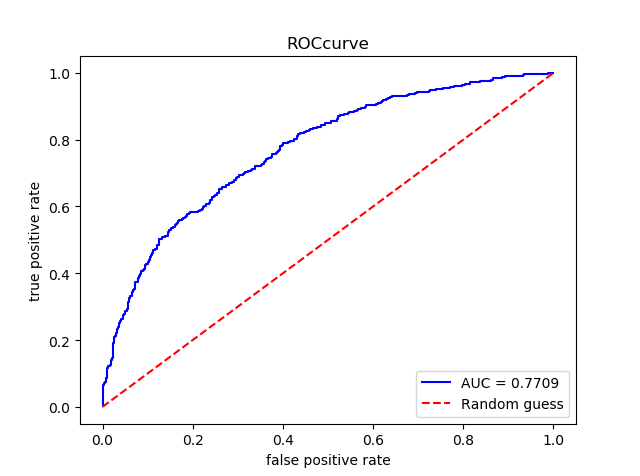
#LightGBM lgbm_c = LGBMClassifier() lgbm_c.fit(X_train,y_train) pre_lgbm = lgbm_c.predict(X_test) pre_proba_lgbm = lgbm_c.predict_proba(X_test)[:,1] assess(pre_lgbm,pre_proba_lgbm)



