
1 前景提要 1.1 碎片化問題 分頁與分段 頁是信息的物理單位, 分頁是為了實現非連續分配, 以便解決記憶體碎片問題, 或者說分頁是由於系統管理的需要. 段是信息的邏輯單位,它含有一組意義相對完整的信息, 分段的目的是為了更好地實現共用, 滿足用戶的需要. 頁的大小固定且由系統確定, 將邏輯地址劃分 ...
1 前景提要
1.1 碎片化問題
分頁與分段
頁是信息的物理單位, 分頁是為了實現非連續分配, 以便解決記憶體碎片問題, 或者說分頁是由於系統管理的需要. 段是信息的邏輯單位,它含有一組意義相對完整的信息, 分段的目的是為了更好地實現共用, 滿足用戶的需要.
頁的大小固定且由系統確定, 將邏輯地址劃分為頁號和頁內地址是由機器硬體實現的. 而段的長度卻不固定, 決定於用戶所編寫的程式, 通常由編譯程式在對源程式進行編譯時根據信息的性質來劃分.
分頁的作業地址空間是一維的. 分段的地址空間是二維的.
內部碎片與外部碎片
在頁式虛擬存儲系統中, 用戶作業的地址空間被劃分成若幹大小相等的頁面, 存儲空間也分成也頁大小相等的物理塊, 但一般情況下, 作業的大小不可能都是物理塊大小的整數倍, 因此作業的最後一頁中仍有部分空間被浪費掉了. 由此可知, 頁式虛擬存儲系統中存在內碎片.
在段式虛擬存儲系統中, 作業的地址空間由若幹個邏輯分段組成, 每段分配一個連續的記憶體區, 但各段之間不要求連續, 其記憶體的分配方式類似於動態分區分配.由此可知, 段式虛擬存儲系統中存在外碎片.
在記憶體管理中, “內零頭”和”外零頭”個指的是什麼?
在固定式分區分配, 可變式分區分配, 頁式虛擬存儲系統, 段式虛擬存儲系統中, 各會存在何種碎片? 為什麼?
解答:
在存儲管理中
- 內碎片是指分配給作業的存儲空間中未被利用的部分
在固定式分區分配中, 為將一個用戶作業裝入記憶體, 記憶體分配程式從系統分區表中找出一個能滿足作業要求的空閑分區分配給作業, 由於一個作業的大小並不一定與分區大小相等, 因此, 分區中有一部分存儲空間浪費掉了. 由此可知, 固定式分區分配中存在內碎片.
- 外碎片是指系統中無法利用的小存儲塊.
在可變式分區分配中, 為把一個作業裝入記憶體, 應按照一定的分配演算法從系統中找出一個能滿足作業需求的空閑分區分配給作業, 如果這個空閑分區的容量比作業申請的空間容量要大, 則將該分區一分為二, 一部分分配給作業, 剩下的部分仍然留作系統的空閑分區。由此可知,可變式分區分配中存在外碎片.
簡言之
隨著存儲區的分配和釋放過程的進行, 在各個被分配出去的分區之間會存在很多的小空閑區, 暫時不能被利用, 這就是”外部碎片”.
在固定分區管理演算法中, 分給程式的記憶體空間往往大於程式所需的空間, 這剩餘部分的空間不能被其他程式所用, 這就是”內部碎片”
1.2 今日內容(buddy伙伴系統如何避免碎片)
Linux伙伴系統分配記憶體的大小要求2的冪指數頁, 這也會產生嚴重的內部碎片.
伙伴系統的基本原理已經在前面已經討論過, 一個雙鏈表即可滿足伙伴系統的所有需求, 其方案在最近幾年間確實工作得非常好。但在Linux記憶體管理方面,有一個長期存在的問題 : 在系統啟動並長期運行後,物理記憶體會產生很多碎片。該情形如下圖所示
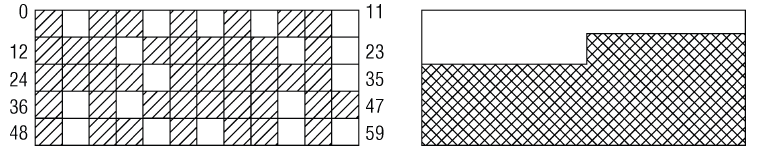
但對內核來說,碎片是一個問題. 由於(大多數)物理記憶體一致映射到地址空間的內核部分, 那麼在左圖的場景中, 無法映射比一頁更大的記憶體區. 儘管許多時候內核都分配的是比較小的記憶體, 但也有時候需要分配多於一頁的記憶體. 顯而易見, 在分配較大記憶體的情況下, 右圖中所有已分配頁和空閑頁都處於連續記憶體區的情形,是更為可取的.
很有趣的一點是, 在大部分記憶體仍然未分配時, 就也可能發生碎片問題. 考慮下圖所示的情形.
只分配了4頁,但可分配的最大連續區只有8頁,因為伙伴系統所能工作的分配範圍只能是2的冪次.

我提到記憶體碎片只涉及內核,這隻是部分正確的。大多數現代CPU都提供了使用巨型頁的可能性,比普通頁大得多。這對記憶體使用密集的應用程式有好處。在使用更大的頁時,地址轉換後備緩衝器只需處理較少的項,降低了TLB緩存失效的可能性。但分配巨型頁需要連續的空閑物理記憶體!
很長時間以來,物理記憶體的碎片確實是Linux的弱點之一。儘管已經提出了許多方法,但沒有哪個方法能夠既滿足Linux需要處理的各種類型工作負荷提出的苛刻需求,同時又對其他事務影響不大。
目前Linux內核為解決記憶體碎片的方案提供了兩類解決方案
- 依據可移動性組織頁避免記憶體碎片
- 虛擬可移動記憶體域避免記憶體碎片
2 依據可移動性組織頁避免記憶體碎片
依據可移動性組織頁是方式物理記憶體碎片的一種可能方法.
2.1 依據可移動性組織頁
在內核2.6.24開發期間,防止碎片的方法最終加入內核。在我討論具體策略之前,有一點需要澄清。
文件系統也有碎片,該領域的碎片問題主要通過碎片合併工具解決。它們分析文件系統,重新排序已分配存儲塊,從而建立較大的連續存儲區. 理論上,該方法對物理記憶體也是可能的,但由於許多物理記憶體頁不能移動到任意位置,阻礙了該方法的實施。因此,內核的方法是反碎片(anti-fragmentation), 即試圖從最初開始儘可能防止碎片.
反碎片的工作原理如何?
為理解該方法,我們必須知道內核將已分配頁劃分為下麵3種不同類型。
| 頁面類型 | 描述 | 舉例 |
|---|---|---|
| 不可移動頁 | 在記憶體中有固定位置, 不能移動到其他地方. | 核心內核分配的大多數記憶體屬於該類別 |
| 可移動頁 | 可以隨意地移動. | 屬於用戶空間應用程式的頁屬於該類別. 它們是通過頁表映射的 如果它們複製到新位置,頁表項可以相應地更新,應用程式不會註意到任何事 |
| 可回收頁 | 不能直接移動, 但可以刪除, 其內容可以從某些源重新生成. | 例如,映射自文件的數據屬於該類別 kswapd守護進程會根據可回收頁訪問的頻繁程度,周期性釋放此類記憶體. , 頁面回收本身就是一個複雜的過程. 內核會在可回收頁占據了太多記憶體時進行回收, 在記憶體短缺(即分配失敗)時也可以發起頁面回收. |
頁的可移動性,依賴該頁屬於3種類別的哪一種. 內核使用的反碎片技術, 即基於將具有相同可移動性的頁分組的思想.
為什麼這種方法有助於減少碎片
由於頁無法移動, 導致在原本幾乎全空的記憶體區中無法進行連續分配. 根據頁的可移動性, 將其分配到不同的列表中, 即可防止這種情形. 例如, 不可移動的頁不能位於可移動記憶體區的中間, 否則就無法從該記憶體區分配較大的連續記憶體塊.
想一下, 上圖中大多數空閑頁都屬於可回收的類別, 而分配的頁則是不可移動的. 如果這些頁聚集到兩個不同的列表中, 如下圖所示. 在不可移動頁中仍然難以找到較大的連續空閑空間, 但對可回收的頁, 就容易多了.

但要註意, 從最初開始, 記憶體並未劃分為可移動性不同的區. 這些是在運行時形成的. 內核的另一種方法確實將記憶體分區, 分別用於可移動頁和不可移動頁的分配, 我會下文討論其工作原理. 但這種劃分對這裡描述的方法是不必要的
2.2 遷移類型
儘管內核使用的反碎片技術卓有成效,它對伙伴分配器的代碼和數據結構幾乎沒有影響。內核定義了一些枚舉常量(早期用巨集來實現)來表示不同的遷移類型, 參見include/linux/mmzone.h?v=4.7, line 38
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};| 巨集 | 類型 |
|---|---|
| MIGRATE_UNMOVABLE | 不可移動頁 |
| MIGRATE_MOVABLE | 可移動頁 |
| MIGRATE_RECLAIMABLE | 可回收頁 |
| MIGRATE_PCPTYPES | 是per_cpu_pageset, 即用來表示每CPU頁框高速緩存的數據結構中的鏈表的遷移類型數目 |
| MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, | 在罕見的情況下,內核需要分配一個高階的頁面塊而不能休眠.如果向具有特定可移動性的列表請求分配記憶體失敗,這種緊急情況下可從MIGRATE_HIGHATOMIC中分配記憶體 |
| MIGRATE_CMA | Linux內核最新的連續記憶體分配器(CMA), 用於避免預留大塊記憶體 |
| MIGRATE_ISOLATE | 是一個特殊的虛擬區域, 用於跨越NUMA結點移動物理記憶體頁. 在大型系統上, 它有益於將物理記憶體頁移動到接近於使用該頁最頻繁的CPU. |
| MIGRATE_TYPES | 只是表示遷移類型的數目, 也不代表具體的區域 |
對於MIGRATE_CMA類型, 其中在我們使用ARM等嵌入式Linux系統的時候, 一個頭疼的問題是GPU, Camera, HDMI等都需要預留大量連續記憶體,這部分記憶體平時不用,但是一般的做法又必須先預留著. 目前, Marek Szyprowski和Michal Nazarewicz實現了一套全新的Contiguous Memory Allocator. 通過這套機制, 我們可以做到不預留記憶體,這些記憶體平時是可用的,只有當需要的時候才被分配給Camera,HDMI等設備. 參照宋寶華–Linux內核最新的連續記憶體分配器(CMA)——避免預留大塊記憶體, 內核為此提供了函數is_migrate_cma來檢測當前類型是否為MIGRATE_CMA, 該函數定義在include/linux/mmzone.h?v=4.7, line 69
/* In mm/page_alloc.c; keep in sync also with show_migration_types() there */
extern char * const migratetype_names[MIGRATE_TYPES];
#ifdef CONFIG_CMA
# define is_migrate_cma(migratetype) unlikely((migratetype) == MIGRATE_CMA)
#else
# define is_migrate_cma(migratetype) false
#endif2.3 free_area的改進
對伙伴系統數據結構的主要調整, 是將空閑列表分解為MIGRATE_TYPE個列表, 可以參見free_area的定義include/linux/mmzone.h?v=4.7, line 88
struct free_area
{
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};- nr_free統計了所有列表上空閑頁的數目,而每種遷移類型都對應於一個空閑列表
這樣我們的伙伴系統的記憶體框架就如下所示

巨集for_each_migratetype_order(order, type)可用於迭代指定遷移類型的所有分配階
#define for_each_migratetype_order(order, type) \
for (order = 0; order < MAX_ORDER; order++) \
for (type = 0; type < MIGRATE_TYPES; type++)2.4 遷移備用列表fallbacks
如果內核無法滿足針對某一給定遷移類型的分配請求, 會怎麼樣?
此前已經出現過一個類似的問題, 即特定的NUMA記憶體域無法滿足分配請求時. 我們需要從其他記憶體域中選擇一個代價最低的記憶體域完成記憶體的分配, 因此內核在記憶體的結點pg_data_t中提供了一個備用記憶體域列表zonelists.
內核在記憶體遷移的過程中處理這種情況下的做法是類似的. 提供了一個備用列表fallbacks, 規定了在指定列表中無法滿足分配請求時. 接下來應使用哪一種遷移類型, 定義在mm/page_alloc.c?v=4.7, line 1799
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
* 該數組描述了指定遷移類型的空閑列表耗盡時
* 其他空閑列表在備用列表中的次序
*/
static int fallbacks[MIGRATE_TYPES][4] = {
// 分配不可移動頁失敗的備用列表
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
// 分配可回收頁失敗時的備用列表
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
// 分配可移動頁失敗時的備用列表
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};該數據結構大體上是自明的 :
每一行對應一個類型的備用搜索域的順序, 在內核想要分配不可移動頁MIGRATE_UNMOVABLE時, 如果對應鏈表為空, 則遍歷fallbacks[MIGRATE_UNMOVABLE], 首先後退到可回收頁鏈表MIGRATE_RECLAIMABLE, 接下來到可移動頁鏈表MIGRATE_MOVABLE, 最後到緊急分配鏈表MIGRATE_TYPES.
2.5 全局pageblock_order變數
全局變數和輔助函數儘管頁可移動性分組特性總是編譯到內核中,但只有在系統中有足夠記憶體可以分配到多個遷移類型對應的鏈表時,才是有意義的。由於每個遷移鏈表都應該有適當數量的記憶體,內核需要定義”適當”的概念. 這是通過兩個全局變數pageblock_order和pageblock_nr_pages提供的. 第一個表示內核認為是”大”的一個分配階, pageblock_nr_pages則表示該分配階對應的頁數。如果體繫結構提供了巨型頁機制, 則pageblock_order通常定義為巨型頁對應的分配階. 定義在include/linux/pageblock-flags.h?v=4.7, line 44
#ifdef CONFIG_HUGETLB_PAGE
#ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE
/* Huge page sizes are variable */
extern unsigned int pageblock_order;
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/* Huge pages are a constant size */
#define pageblock_order HUGETLB_PAGE_ORDER
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
#else /* CONFIG_HUGETLB_PAGE */
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)
#endif /* CONFIG_HUGETLB_PAGE */
#define pageblock_nr_pages (1UL << pageblock_order)在IA-32體繫結構上, 巨型頁長度是4MB, 因此每個巨型頁由1024個普通頁組成, 而HUGETLB_PAGE_ORDER則定義為10. 相比之下, IA-64體繫結構允許設置可變的普通和巨型頁長度, 因此HUGETLB_PAGE_ORDER的值取決於內核配置.
如果體繫結構不支持巨型頁, 則將其定義為第二高的分配階, 即MAX_ORDER - 1
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)如果各遷移類型的鏈表中沒有一塊較大的連續記憶體, 那麼頁面遷移不會提供任何好處, 因此在可用記憶體太少時內核會關閉該特性. 這是在build_all_zonelists函數中檢查的, 該函數用於初始化記憶體域列表. 如果沒有足夠的記憶體可用, 則全局變數page_group_by_mobility_disabled設置為0, 否則設置為1.
內核如何知道給定的分配記憶體屬於何種遷移類型?
我們將在以後講解, 有關各個記憶體分配的細節都通過分配掩碼指定.
內核提供了兩個標誌,分別用於表示分配的記憶體是可移動的(__GFP_MOVABLE)或可回收的(__GFP_RECLAIMABLE).
2.6 gfpflags_to_migratetype轉換分配標識到遷移類型
如果這些標誌都沒有設置, 則分配的記憶體假定為不可移動的. 輔助函數gfpflags_to_migratetype可用於轉換分配標誌及對應的遷移類型, 該函數定義在include/linux/gfp.h?v=4.7, line 266
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}linux-2.6.x的內核中轉換分配標誌及對應的遷移類型的輔助函數為allocflags_to_migratetype, 這個名字會有歧義的, 讓我們誤以為參數的標識中有alloc flags, 但是其實並不然, 因此後來的內核中將該函數更名為gfpflags_to_migratetype, 參見Rename it to gfpflags_to_migratetype()
在2.6.25中為如下介面
/* Convert GFP flags to their corresponding migrate type */
static inline int allocflags_to_migratetype(gfp_t gfp_flags)
{
WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (((gfp_flags & __GFP_MOVABLE) != 0) << 1) |
((gfp_flags & __GFP_RECLAIMABLE) != 0);
}如果停用了頁面遷移特性, 則所有的頁都是不可移動的. 否則. 該函數的返回值可以直接用作free_area.free_list的數組索引.
2.7 pageblock_flags變數與其函數介面
最後要註意, 每個記憶體域都提供了一個特殊的欄位, 可以跟蹤包含pageblock_nr_pages個頁的記憶體區的屬性. 即zone->pageblock_flags欄位, 當前只有與頁可移動性相關的代碼使用, 參見include/linux/mmzone.h?v=4.7, line 367
struct zone
{
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
};內核提供set_pageblock_migratetype負責設置以page為首的一個記憶體區的遷移類型, 該函數定義在mm/page_alloc.c?v=4.7, line 458, 如下所示
void set_pageblock_migratetype(struct page *page, int migratetype)
{
if (unlikely(page_group_by_mobility_disabled &&
migratetype < MIGRATE_PCPTYPES))
migratetype = MIGRATE_UNMOVABLE;
set_pageblock_flags_group(page, (unsigned long)migratetype,
PB_migrate, PB_migrate_end);
}migratetype參數可以通過上文介紹的gfpflags_to_migratetype輔助函數構建. 請註意很重要的一點, 頁的遷移類型是預先分配好的, 對應的比特位總是可用, 與頁是否由伙伴系統管理無關. 在釋放記憶體時,頁必須返回到正確的遷移鏈表。這之所以可行,是因為能夠從get_pageblock_migratetype獲得所需的信息. 參見include/linux/mmzone.h?v=4.7, line 84
#define get_pageblock_migratetype(page) \
get_pfnblock_flags_mask(page, page_to_pfn(page), \
PB_migrate_end, MIGRATETYPE_MASK)2.8 /proc/pagetypeinfo獲取頁面分配狀態
最後請註意, 在各個遷移鏈表之間, 當前的頁面分配狀態可以從/proc/pagetypeinfo獲得.

2.9 可移動性的分組的初始化
在記憶體子系統初始化期間, memmap_init_zone負責處理記憶體域的page實例. 該函數定義在mm/page_alloc.c?v=4.7, line 5139, 該函數完成了一些不怎麼有趣的標準初始化工作,但其中有一件是實質性的,即所有的頁最初都標記為可移動的. 參見mm/page_alloc.c?v=4.7, line 5224
/*
* Initially all pages are reserved - free ones are freed
* up by free_all_bootmem() once the early boot process is
* done. Non-atomic initialization, single-pass.
*/
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
/* ...... */
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
/* ...... */
not_early:
if (!(pfn & (pageblock_nr_pages - 1))) {
struct page *page = pfn_to_page(pfn);
__init_single_page(page, pfn, zone, nid);
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
} else {
__init_single_pfn(pfn, zone, nid);
}
}
}在分配記憶體時, 如果必須”盜取”不同於預定遷移類型的記憶體區, 內核在策略上傾向於”盜取”更大的記憶體區. 由於所有頁最初都是可移動的, 那麼在內核分配不可移動的記憶體區時, 則必須”盜取”.
實際上, 在啟動期間分配可移動記憶體區的情況較少, 那麼分配器有很高的幾率分配長度最大的記憶體區, 並將其從可移動列表轉換到不可移動列表. 由於分配的記憶體區長度是最大的, 因此不會向可移動記憶體中引入碎片.
總而言之, 這種做法避免了啟動期間內核分配的記憶體(經常在系統的整個運行時間都不釋放)散佈到物理記憶體各處, 從而使其他類型的記憶體分配免受碎片的干擾,這也是頁可移動性分組框架的最重要的目標之一.
3 虛擬可移動記憶體域避免記憶體碎片
3.1 虛擬可移動記憶體域
依據可移動性組織頁是防止物理記憶體碎片的一種可能方法,內核還提供了另一種阻止該問題的手段 : 虛擬記憶體域ZONE_MOVABLE.
該機制在內核2.6.23開發期間已經併入內核, 比可移動性分組框架加入內核早一個版本. 與可移動性分組相反, ZONE_MOVABLE特性必須由管理員顯式激活.
基本思想很簡單 : 可用的物理記憶體劃分為兩個記憶體域, 一個用於可移動分配, 一個用於不可移動分配. 這會自動防止不可移動頁向可移動記憶體域引入碎片.
這馬上引出了另一個問題 : 內核如何在兩個競爭的記憶體域之間分配可用的記憶體?
這顯然對內核要求太高,因此系統管理員必須作出決定。畢竟,人可以更好地預測電腦需要處理的場景,以及各種類型記憶體分配的預期分佈.
3.2 數據結構
kernelcore參數用來指定用於不可移動分配的記憶體數量, 即用於既不能回收也不能遷移的記憶體數量。剩餘的記憶體用於可移動分配。在分析該參數之後,結果保存在全局變數required_kernelcore中.
還可以使用參數movablecore控制用於可移動記憶體分配的記憶體數量。required_kernelcore的大小將會據此計算。如果有些聰明人同時指定兩個參數,內核會按前述方法計算出required_kernelcore的值,並取指定值和計算值中較大的一個.
全局變數required_kernelcore和required_movablecore的定義在mm/page_alloc.c?v=4.7, line 261, 如下所示
static unsigned long __initdata required_kernelcore;
static unsigned long __initdata required_movablecore;取決於體繫結構和內核配置,ZONE_MOVABLE記憶體域可能位於高端或普通記憶體域, 參見include/linux/mmzone.h?v=4.7, line 267
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};與系統中所有其他的記憶體域相反, ZONE_MOVABLE並不關聯到任何硬體上有意義的記憶體範圍. 實際上, 該記憶體域中的記憶體取自高端記憶體域或普通記憶體域, 因此我們在下文中稱ZONE_MOVABLE是一個虛擬記憶體域.
輔助函數find_zone_movable_pfns_for_nodes用於計算進入ZONE_MOVABLE的記憶體數量.
如果kernelcore和movablecore參數都沒有指定find_zone_movable_pfns_for_nodes會使ZONE_MOVABLE保持為空,該機制處於無效狀態.
談到從物理記憶體域提取多少記憶體用於ZONE_MOVABLE的問題, 必須考慮下麵兩種情況
- 用於不可移動分配的記憶體會平均地分佈到所有記憶體結點上
- 只使用來自最高記憶體域的記憶體。在記憶體較多的32位系統上, 這通常會是ZONE_HIGHMEM, 但是對於64位系統,將使用ZONE_NORMAL或ZONE_DMA32.
實際計算相當冗長,也不怎麼有趣,因此我不詳細討論了。實際上起作用的是結果
用於為虛擬記憶體域ZONE_MOVABLE提取記憶體頁的物理記憶體域,保存在全局變數movable_zone中
對每個結點來說, zone_movable_pfn[node_id]表示ZONE_MOVABLE在movable_zone記憶體域中所取得記憶體的起始地址.
zone_movable_pfn定義在mm/page_alloc.c?v=4.7, line 263
static unsigned long __meminitdata zone_movable_pfn[MAX_NUMNODES];
static bool mirrored_kernelcore;內核確保這些頁將用於滿足符合ZONE_MOVABLE職責的記憶體分配。
3.3 實現
到現在為止描述的數據結構如何應用?
類似於頁面遷移方法, 分配標誌在此扮演了關鍵角色.
具體的實現將在3.5.4節更詳細地討論. 目前只要知道所有可移動分配都必須指定__GFP_HIGHMEM和__GFP_MOVABLE即可.
由於內核依據分配標誌確定進行記憶體分配的記憶體域, 在設置了上述的標誌時, 可以選擇ZONE_MOVABLE記憶體域. 這是將ZONE_MOVABLE集成到伙伴系統中所需的唯一改變!其餘的可以通過適用於所有記憶體域的通用常式處理, 我們將在下文討論


