
Zookeeper 的核心原理 Zookeeper 的由來 各個節點的數據一致性 怎麼保證任務只在一個節點執行 如果orderserver1掛了,其他節點如何發現並接替 存在共用資源,互斥性、安全性 Apache 的Zookeeper Google 的Chubby 是一個分散式鎖服務,通過Googl ...
-
-
怎麼保證任務只在一個節點執行
-
如果orderserver1掛了,其他節點如何發現並接替
-
存在共用資源,互斥性、安全性

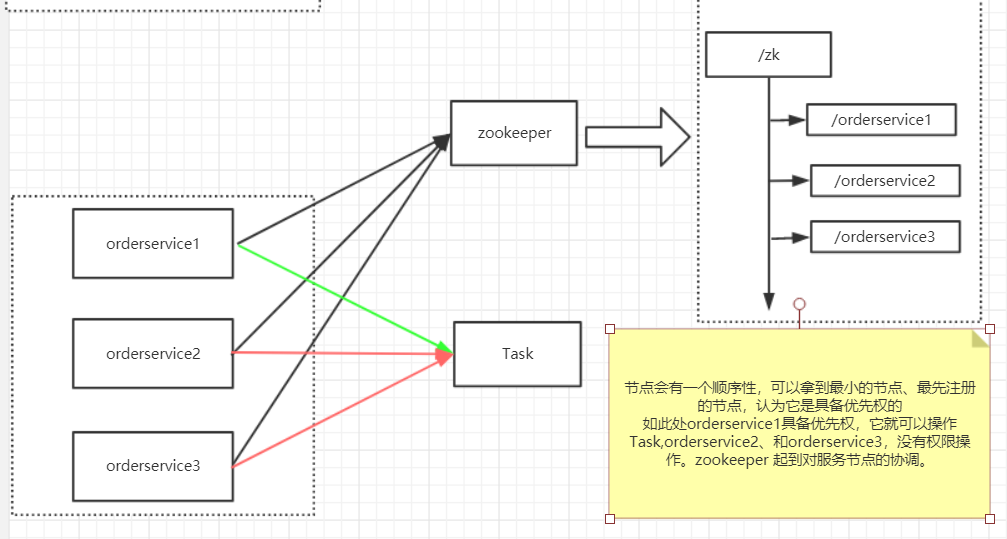
Google 的Chubby 是一個分散式鎖服務,通過Google Chubby 來解決分散式協作、Master選舉等與分散式鎖服務相關的問題
-
-
集群方案(Leader Follower)還能分擔請求,既做了高可用,又做高性能
-
-
每個節點的數據是一致的(必須要有leader)
leader master(帶中心化的) redis-cluser (無中心化的)
-
集群中的leader 掛了,怎麼辦?數據怎麼恢復?
選舉機制?數據恢復
-
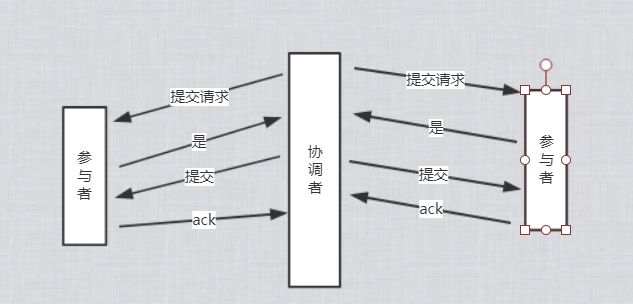
如何去保證數據一致性?(分散式事務)
2PC 協議、二階提交
-
事務詢問
-
協調者向所有的參與者發送事務內容,詢問是否可以執行事務提交操作,並開始等待各參與者的響應。
-
-
執行事務
-
各個參與者節點執行事務操作,並將Undo和Redo信息記錄到事務日誌中,儘量把提交過程中所有消耗時間的操作和準備的提前完成確保後面100%成功提交事務
-
-
各個參與者向協調者反饋事務詢問的響應
-
如果各個參與者都成功執行了事務操作,那麼就反饋給參與者yes的響應,表示事務可以執行;
-
如果參與者沒有成功執行事務,就反饋給協調者no的響應,表示事務不可以執行;
-
2pc 協議的第一個階段稱為“投票階段”,即各參與者投票表名是否需要繼續執行接下去的事務提交操作。
-
階段二:執行事務提交
在這個階段,協調者會根據各參與者的反饋情況來決定最終是否可以進行事務提交操作;
兩種可能:
-
執行事務
-
中斷事務
如果是讀請求,就直接從當前節點中讀取數據

如果是寫請求,那麼請求會轉發給leader 提交事務,然後leader將事務廣播給集群中的follower節點(註意obeserver節點不參與投票),Follower 節點給leader 一個ack (ack表示當前的節點是不是能執行這個事務),只要有超過半數節點寫入成功,那麼寫請求就會被提交。集群節點需要(2n+1)
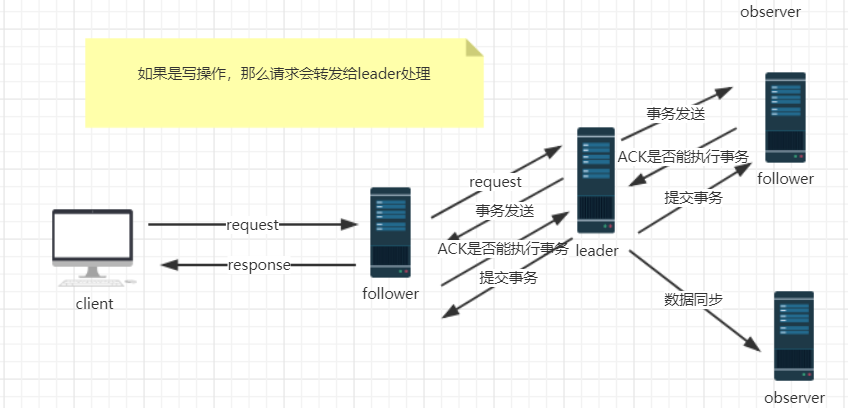
是zookeeper中的整個核心,起到了主導整個集群的作用
-
事務請求的調度和處理
-
保證事務處理的順序性
Follower角色
-
處理客戶端的非事務請求,
-
轉發事務請求給leader伺服器
-
參與事務請求Proposal 的投票(需要半數以上伺服器通過才能通知leader commit數據; Leader發起的提案, 要求Follower投票)
-
參與leader節點選舉的投票
Observer角色
是一個觀察者角色
-
瞭解集群中的狀態變化 ,和對這些狀態進行同步
-
工作原理和follower節點一樣,唯一差別是不參與事務請求的投票,不參與Leader選舉
-
Observer 只提供非事務請求,通常在於不影響集群事務處理能力的前提下,提升集群非事務處理能力
註:
表示奇數節點, zookeeper中要正常對外提供服務的話,它裡面有個投票機制,這個機制就是必須要有過半的機器正常工作,並且能夠彼此完成通信進行事務投票結果。
支持崩潰恢復的原子廣播協議,主要用於數據一致性
ZAB協議基本模式
-
崩潰恢復(恢復leader節點和恢複數據)
-
原子廣播
消息廣播過程實際是一個簡化版的二階提交。2PC
-
leader 接收到消息請求後,將消息賦予一個全局唯一的64位自增id(ZXID)。ZXID大小,實現因果有序的特征。
-
leader 為每一個follower 準備了一個FIFO隊列,將帶有zxid的消息作為一個提案(Proposal)分發給所有follower
-
當follower 收到proposal,先把proposal寫到磁碟,寫入成功後,再向leader 回覆一個ack
-
當leader接收到合法數量的ack後,leader 就會向這個follower 發送commit命令,同時會在本地執行該消息。
-
當follower 收到消息的commit以後,會提交該消息。
註:leader 的投票過程,不需要Observer 的ack,但是Observer必須要同步Leader的數據,保證數據的一致性。
-
-
當leader伺服器宕機
集群進去崩潰恢復階段
對於數據恢復來說
-
已經處理的消息不能丟失
-
當leader 收到合法數量的follower 的ack以後,就會向各個follower 廣播消息(commit命令),同時自己也會commit 這條事務消息。
-
如果follower節點收到commit命令之前,leader掛了,會導致部分節點收到commit,部分節點沒有收到。
-
ZAB協議需要保證已經處理的消息不能丟失。
-
-
被丟棄的消息不能再次出現
-
當Leader收到事務請求,還未發起事務投票之前,leader掛了
ZAB的設計思想
-
zxid 是最大的
-
如果leader選舉演算法能夠保證新選舉出來的leader伺服器擁有集群中所有機器最高編號(ZXID最大)的事務Proposal,那麼就可以保證這個新選舉出來的Leader一定具有已經提交的提案。因為所有提案被Commit之前必須有超過半數的Follower ACK,即必須有超過半數的伺服器的事務日誌上有該提案的proposal,因此,只要有合法數量的節點正常工作,就必然有一個節點保存了所有被commit消息的proposal狀態。
-
-
epoch的概念,每產生一個新的leader,那麼新的leader的epoch會+1,zxid 是64位的數據,低32位表示消息計數器(自增),每收到一條消息,這個值+1,新 leader選舉後這個值重置為0。這樣設計的原因在於,老的leader 掛了以後重啟,他不會選舉為leader,y因此此時它的zxid肯定小於當前新的leader.當老的 leader 作為 follower 接入新的 leader 後,新的 leader會讓它將所有的擁有舊的epoch號的未被COMMIT的proposal清除 .高32位會存儲epoch編號
為了保證事務順序的一致性,Zookeeper 採用了遞增的事務id號來標識事務。
所有的提議Proposal都在被提出的時候加上了zxid.
ZXID 是一個64位的數字(低32位和高32位組成)
-
低32位:表示消息計數器
-
高32位 :表示epoch,用來標識 leader 關係是否改變。 每次一個leader被選出來,都會有一個新的epoch(原來的epoch+1),標識當前屬於那個leader的統治時期。
註:
leader: 類似,有自己的年號,每次變更都會在前一個年代上加1。
/tmp/zookeeper/VERSION-2 路徑會看到一個 currentEpoch文件。文件顯示的是當前的epoch
通過命令查看事務日誌
java -cp :/opt/zookeeper/zookeeper-3.4.10/lib/slf4j-api-1.6.1.jar:/opt/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.jar org.apache.zookeeper.server.LogFormatter /tmp/zookeeper/version-2/log.100000001
註:
ZXID(事務ID)事務ID 越大,那麼表示數據越新, 最大會設置為Leader, ,
epoch ,每一輪投票,epoch 都會遞增
myid (伺服器id ,server id)
myid 越大,在leader 選舉機制中權重越大
服務啟動時的狀態都是LOOKING,觀望狀態
LEADING
FOLLOWING
OBSERVING
-
-
投票信息包含(myid,zxid,epoch)
-
-
接受來自各個伺服器的投票
-
判斷該投票是否有效
-
檢查是否來自本輪投票epoch
-
檢查是否來時LOOKING狀態的伺服器
-
-
-
處理投票
-
檢查ZXID,如果ZXID比較大,那麼設置為Leader,
-
如果ZXID相同,會檢查myid,myid比較大的,設置為leader
-
-
統計投票
-
判斷是否已經有過半機器接受到相同的投票信息
-
如果有過半機器接受,便認為已經選舉出了Leader
-
-
改變伺服器狀態
-
如果是Follower,那麼狀態變為FOLLOWING
-
如果是Leader,那麼狀態變為LEADING
-
變更狀態
-
Leader 掛後,餘下非Observer伺服器都會將自己的伺服器狀態變為LOOKING,
-
開始進入Leader選舉過程
-
-
每個Server會發起一個投票。
-
運行期間,ZXID 可能不同,然後將各自的投票發送給集群中的所有機器。
-
-
其餘與啟動時過程相同。


