
MIT 6.828 Lab 6: Network Driver (default final project) tags: mit 6.828 os 概述 本lab是6.828預設的最後一個實驗,圍繞 網路 展開。主要就做了一件事情。 從0實現網路驅動。 還提到一些比較重要的概念: 1. 記憶體映射I ...
MIT-6.828 Lab 6: Network Driver (default final project)
tags: mit-6.828 os
概述
本lab是6.828預設的最後一個實驗,圍繞網路展開。主要就做了一件事情。
從0實現網路驅動。
還提到一些比較重要的概念:
- 記憶體映射I/O
- DMA
- 用戶級線程實現原理
The Network Server
從0開始寫協議棧是很困難的,我們將使用lwIP,輕量級的TCP/IP實現,更多lwIP信息可以參考lwIP官網。對於我們來說lwIP就像一個實現了BSD socket介面的黑盒,分別有一個包輸入和輸出埠。
JOS的網路網路服務由四個進程組成:
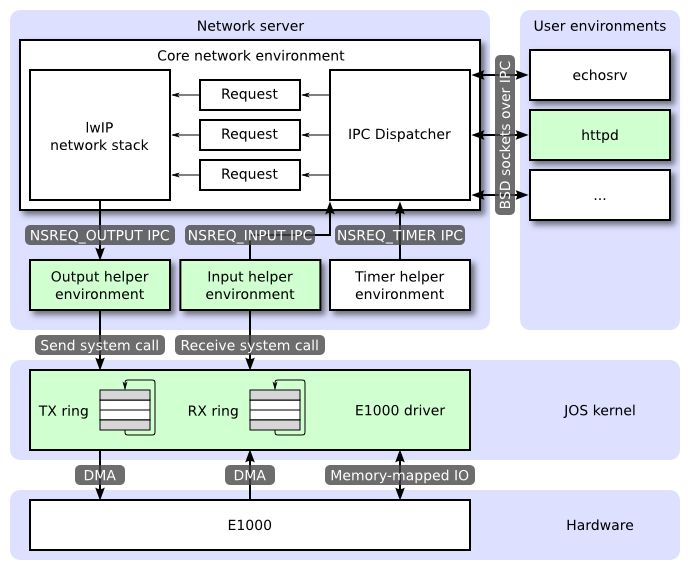
- 核心網路進程:
核心網路進程由socket調用分發器和lwIP組成。socket調用分發器和文件服務一樣。用戶進程發送IPC消息給核心網路進程。
用戶進程不直接使用nsipc_*開頭的函數調用,而是使用lib/socket.c中的函數。這樣用戶進程通過文件描述符來訪問socket。
文件服務和網路服務有很多相似的地方,但是最大的不同點在於,BSD socket調用accept和recv可能會阻塞,如果分發器調用lwIP這些阻塞的函數,自己也會阻塞,這樣就只能提供一個網路服務了。顯然是不能接受的,網路服務將使用用戶級的線程來避免這種情況。 - 包輸出進程:
lwIP通過IPC發送packets到輸出進程,然後輸出進程負責通過系統調用將這些packets轉發給設備驅動。 - 包輸入進程:
對於每個從設備驅動收到的packet,輸入進程從內核取出這些packet,然後使用IPC轉發給核心網路進程。 - 定時器進程:
定時器進程周期性地發送消息給核心網路進程,通知它一段時間已經過了,這種消息被lwIP用來實現網路超時。
仔細看上圖,綠顏色的部分是本lab需要實現的部分。分別是:
- E1000網卡驅動,並對外提供兩個系統調用,分別用來接收和發送數據。
- 輸入進程。
- 輸出進程。
- 用戶程式httpd的一部分。
Part A: Initialization and transmitting packets
內核目前還沒有時間的概念,硬體每隔10ms都會發送一個時鐘中斷。每次時鐘中斷,我們可以給某個變數加一,來表明時間過去了10ms,具體實現在kern/time.c中。
Exercise 1
在kern/trap.c中添加對time_tick()調用。實現sys_time_msec()系統調用。sys_time_msec()可以配合sys_yield()實現sleep()(見user/testtime.c)。很簡單,代碼省略了。
The Network Interface Card
編寫驅動需要很深的硬體以及硬體介面知識,本lab會提供一些E1000比較表層的知識,你需要學會看E1000的開發者手冊。
PCI Interface
E1000是PCI設備,意味著E1000將插到主板上的PCI匯流排上。PCI匯流排有地址,數據,中斷線允許CPU和PCI設備進行交互。PCI設備在被使用前需要被髮現和初始化。發現的過程是遍歷PCI匯流排尋找相應的設備。初始化的過程是分配I/O和記憶體空間,包括協商IRQ線。
我們已經在kern/pic.c中提供了PCI代碼。為了在啟動階段初始化PCI,PCI代碼遍歷PCI匯流排尋找設備,當它找到一個設備,便會讀取該設備的廠商ID和設備ID,然後使用這兩個值作為鍵搜索pci_attach_vendor數組,該數組由struct pci_driver結構組成。struct pci_driver結構如下:
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};如果找到一個struct pci_driver結構,PCI代碼將會執行struct pci_driver結構的attachfn函數指針指向的函數執行初始化。attachfn函數指針指向的函數傳入一個struct pci_func結構指針。struct pci_func結構的結構如下:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};其中reg_base數組保存了記憶體映射I/O的基地址, reg_size保存了以位元組為單位的大小。 irq_line包含了IRQ線。
當attachfn函數指針指向的函數執行後,該設備就算被找到了,但還沒有啟用,attachfn函數指針指向的函數應該調用pci_func_enable(),該函數啟動設備,協商資源,並且填充傳入的struct pci_func結構。
Exercise 3
實現attach函數來初始化E1000。在kern/pci.c的pci_attach_vendor數組中添加一個元素。82540EM的廠商ID和設備ID可以在手冊5.2節找到。實驗已經提供了kern/e1000.c和kern/e1000.h,補充這兩個文件完成實驗。添加一個函數,並將該函數地址添加到pci_attach_vendor這個數組中。
kern/e1000.c:
int
e1000_attachfn(struct pci_func *pcif)
{
pci_func_enable(pcif);
return 0;
}kern/pci.c:
struct pci_driver pci_attach_vendor[] = {
{ E1000_VENDER_ID_82540EM, E1000_DEV_ID_82540EM, &e1000_attachfn },
{ 0, 0, 0 },
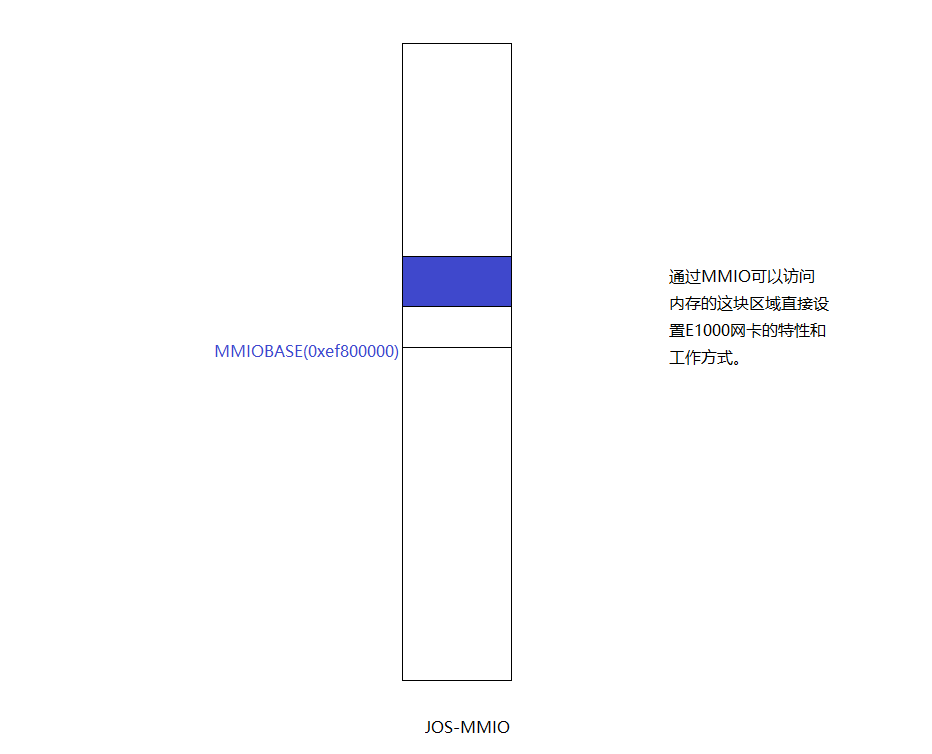
};Memory-mapped I/O
程式通過記憶體映射IO(MMIO)和E1000交互。通過MMIO這種方式,允許通過讀寫"memory"進行控制設備,這裡的"memory"並非DRAM,而是直接讀寫設備。pci_func_enable()協商MMIO範圍,並將基地址和大小保存在基地址寄存器0(reg_base[0] and reg_size[0])中,這是一個物理地址範圍,我們需要通過虛擬地址來訪問,所以需要創建一個新的內核記憶體映射。
Exercise 4
使用mmio_map_region()建立記憶體映射。至此我們能通過虛擬地址bar_va來訪問E1000的寄存器。
volatile void *bar_va;
#define E1000REG(offset) (void *)(bar_va + offset)
int
e1000_attachfn(struct pci_func *pcif)
{
pci_func_enable(pcif);
bar_va = mmio_map_region(pcif->reg_base[0], pcif->reg_size[0]); //mmio_map_region()這個函數之前已經在kern/pmap.c中實現了。
//該函數從線性地址MMIOBASE開始映射物理地址pa開始的size大小的記憶體,並返回pa對應的線性地址。
uint32_t *status_reg = (uint32_t *)E1000REG(E1000_STATUS);
assert(*status_reg == 0x80080783);
return 0;
}lab3和lab4的結果是,我們可以通過直接訪問bar_va開始的記憶體區域來設置E1000的特性和工作方式。
DMA
什麼是DMA?簡單來說就是允許外部設備直接訪問記憶體,而不需要CPU參與。https://en.wikipedia.org/wiki/Direct_memory_access
我們可以通過讀寫E1000的寄存器來發送和接收數據包,但是這種方式非常慢。E1000使用DMA直接讀寫記憶體,不需要CPU參與。驅動負責分配記憶體作為發送和接受隊列,設置DMA描述符,配置E1000這些隊列的位置,之後的操作都是非同步的。
發送一個數據包:驅動將該數據包拷貝到發送隊列中的一個DMA描述符中,通知E1000,E1000從發送隊列的DMA描述符中拿到數據發送出去。
接收數據包:E1000將數據拷貝到接收隊列的一個DMA描述符中,驅動可以從該DMA描述符中讀取數據包。
發送和接收隊列非常相似,都由DMA描述符組成,DMA描述符的確切結構不是固定的,但是都包含一些標誌和包數據的物理地址。發送和接收隊列可以由環形數組實現,都有一個頭指針和一個尾指針。
這些數組的指針和描述符中的包緩衝地址都應該是物理地址,因為硬體操作DMA讀寫物理記憶體不需要通過MMU。
Transmitting Packets
首先我們需要初始化E1000來支持發送包。第一步是建立發送隊列,隊列的具體結構在3.4節,描述符的結構在3.3.3節。驅動必須為發送描述符數組和數據緩衝區域分配記憶體。有多種方式分配數據緩衝區。最簡單的是在驅動初始化的時候就為每個描述符分配一個對應的數據緩衝區。最大的包是1518位元組。
發送隊列和發送隊列描述符如下:

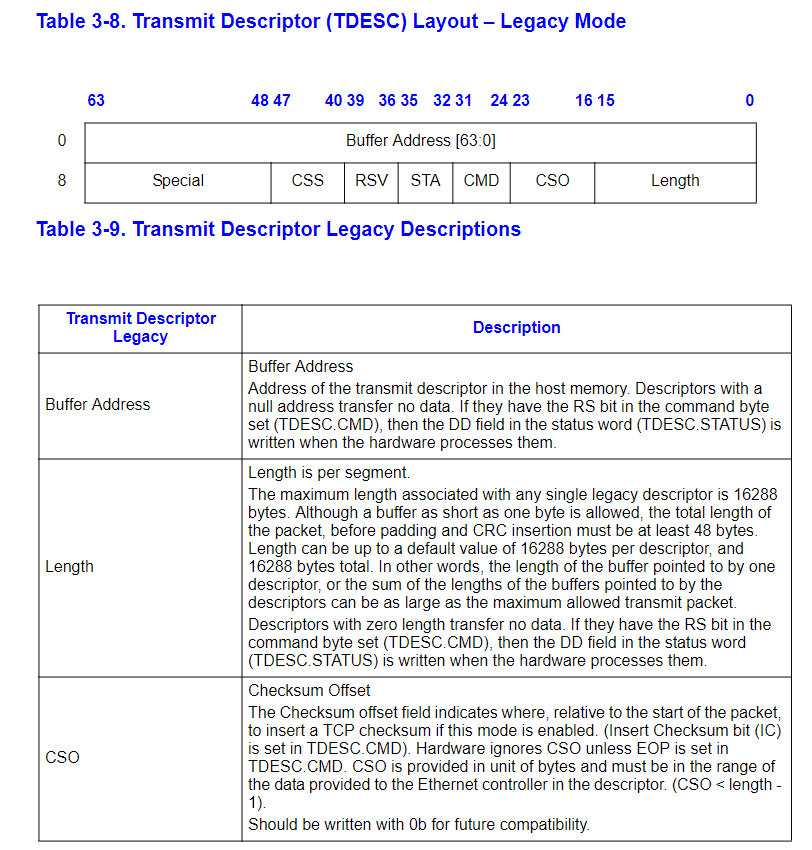
更加詳細的信息參見說明手冊。
Exercise 5
按照14.5節的描述初始化。步驟如下:
- 分配一塊記憶體用作發送描述符隊列,起始地址要16位元組對齊。用基地址填充(TDBAL/TDBAH) 寄存器。
- 設置(TDLEN)寄存器,該寄存器保存發送描述符隊列長度,必須128位元組對齊。
- 設置(TDH/TDT)寄存器,這兩個寄存器都是發送描述符隊列的下標。分別指向頭部和尾部。應該初始化為0。
- 初始化TCTL寄存器。設置TCTL.EN位為1,設置TCTL.PSP位為1。設置TCTL.CT為10h。設置TCTL.COLD為40h。
- 設置TIPG寄存器。
struct e1000_tdh *tdh;
struct e1000_tdt *tdt;
struct e1000_tx_desc tx_desc_array[TXDESCS];
char tx_buffer_array[TXDESCS][TX_PKT_SIZE];
static void
e1000_transmit_init()
{
int i;
for (i = 0; i < TXDESCS; i++) {
tx_desc_array[i].addr = PADDR(tx_buffer_array[i]);
tx_desc_array[i].cmd = 0;
tx_desc_array[i].status |= E1000_TXD_STAT_DD;
}
//設置隊列長度寄存器
struct e1000_tdlen *tdlen = (struct e1000_tdlen *)E1000REG(E1000_TDLEN);
tdlen->len = TXDESCS;
//設置隊列基址低32位
uint32_t *tdbal = (uint32_t *)E1000REG(E1000_TDBAL);
*tdbal = PADDR(tx_desc_array);
//設置隊列基址高32位
uint32_t *tdbah = (uint32_t *)E1000REG(E1000_TDBAH);
*tdbah = 0;
//設置頭指針寄存器
tdh = (struct e1000_tdh *)E1000REG(E1000_TDH);
tdh->tdh = 0;
//設置尾指針寄存器
tdt = (struct e1000_tdt *)E1000REG(E1000_TDT);
tdt->tdt = 0;
//TCTL register
struct e1000_tctl *tctl = (struct e1000_tctl *)E1000REG(E1000_TCTL);
tctl->en = 1;
tctl->psp = 1;
tctl->ct = 0x10;
tctl->cold = 0x40;
//TIPG register
struct e1000_tipg *tipg = (struct e1000_tipg *)E1000REG(E1000_TIPG);
tipg->ipgt = 10;
tipg->ipgr1 = 4;
tipg->ipgr2 = 6;
}現在初始化已經完成,接著需要編寫代碼發送數據包,提供系統調用給用戶代碼使用。要發送一個數據包,需要將數據拷貝到數據下一個數據緩存區,然後更新TDT寄存器來通知網卡新的數據包已經就緒。
Exercise 6
編寫發送數據包的函數,處理好發送隊列已滿的情況。如果發送隊列滿了怎麼辦?
怎麼檢測發送隊列已滿:如果設置了發送描述符的RS位,那麼當網卡發送了一個描述符指向的數據包後,會設置該描述符的DD位,通過這個標誌位就能知道某個描述符是否能被回收。
檢測到發送隊列已滿後怎麼辦:可以簡單的丟棄準備發送的數據包。也可以告訴用戶進程進程當前發送隊列已滿,請重試,就像sys_ipc_try_send()一樣。我們採用重試的方式。
int
e1000_transmit(void *data, size_t len)
{
uint32_t current = tdt->tdt; //tail index in queue
if(!(tx_desc_array[current].status & E1000_TXD_STAT_DD)) {
return -E_TRANSMIT_RETRY;
}
tx_desc_array[current].length = len;
tx_desc_array[current].status &= ~E1000_TXD_STAT_DD;
tx_desc_array[current].cmd |= (E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS);
memcpy(tx_buffer_array[current], data, len);
uint32_t next = (current + 1) % TXDESCS;
tdt->tdt = next;
return 0;
}用一張圖來總結下發送隊列和接收隊列,相信會清晰很多:
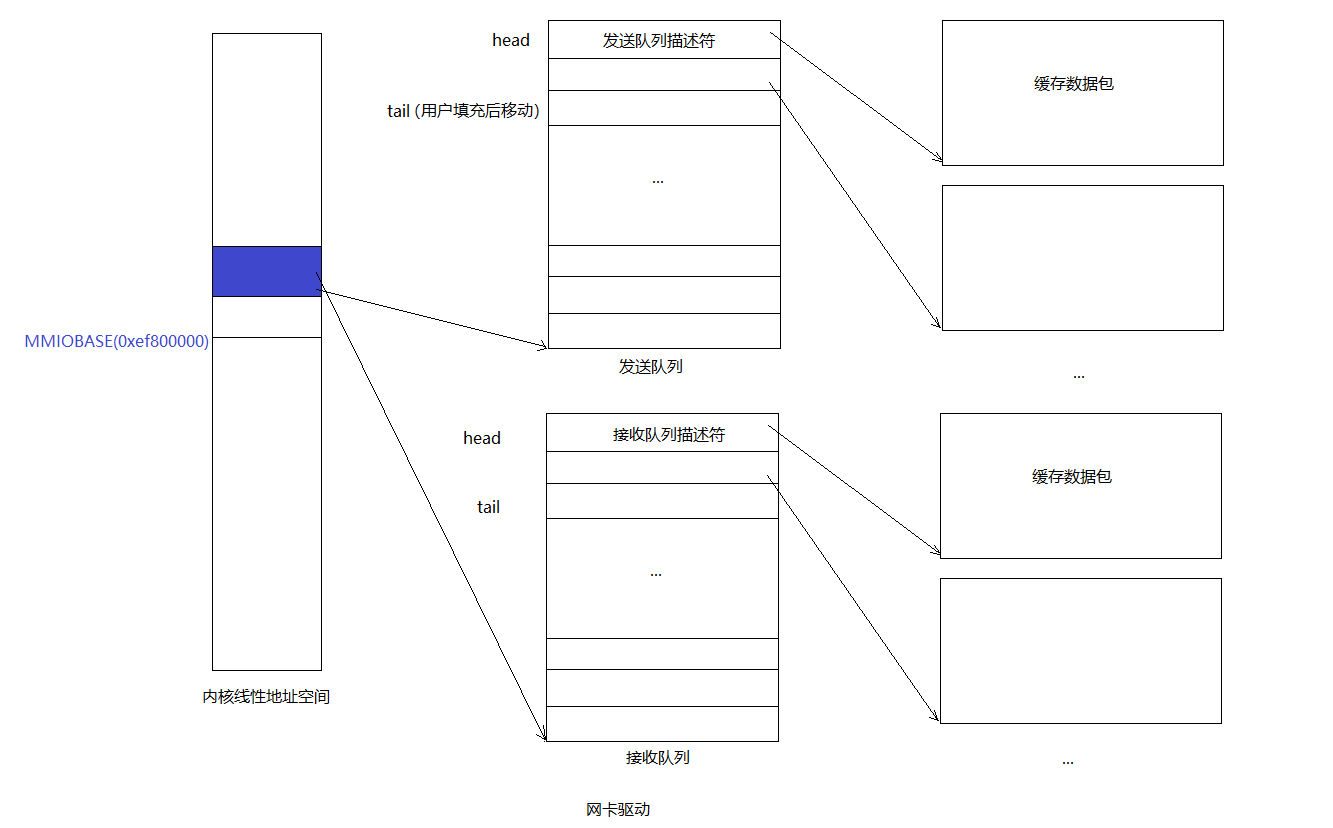
對於發送隊列來說是一個典型的生產者-消費者模型:
- 生產者:用戶進程。通過系統調用往tail指向的描述符的緩存區添加包數據,並且移動tail。
- 消費者:網卡。通過DMA的方式直接從head指向的描述符對應的緩衝區拿包數據發送出去,並移動head。
接收隊列也類似。
Exercise 7
實現發送數據包的系統調用。很簡單呀,不貼代碼了。
Transmitting Packets: Network Server
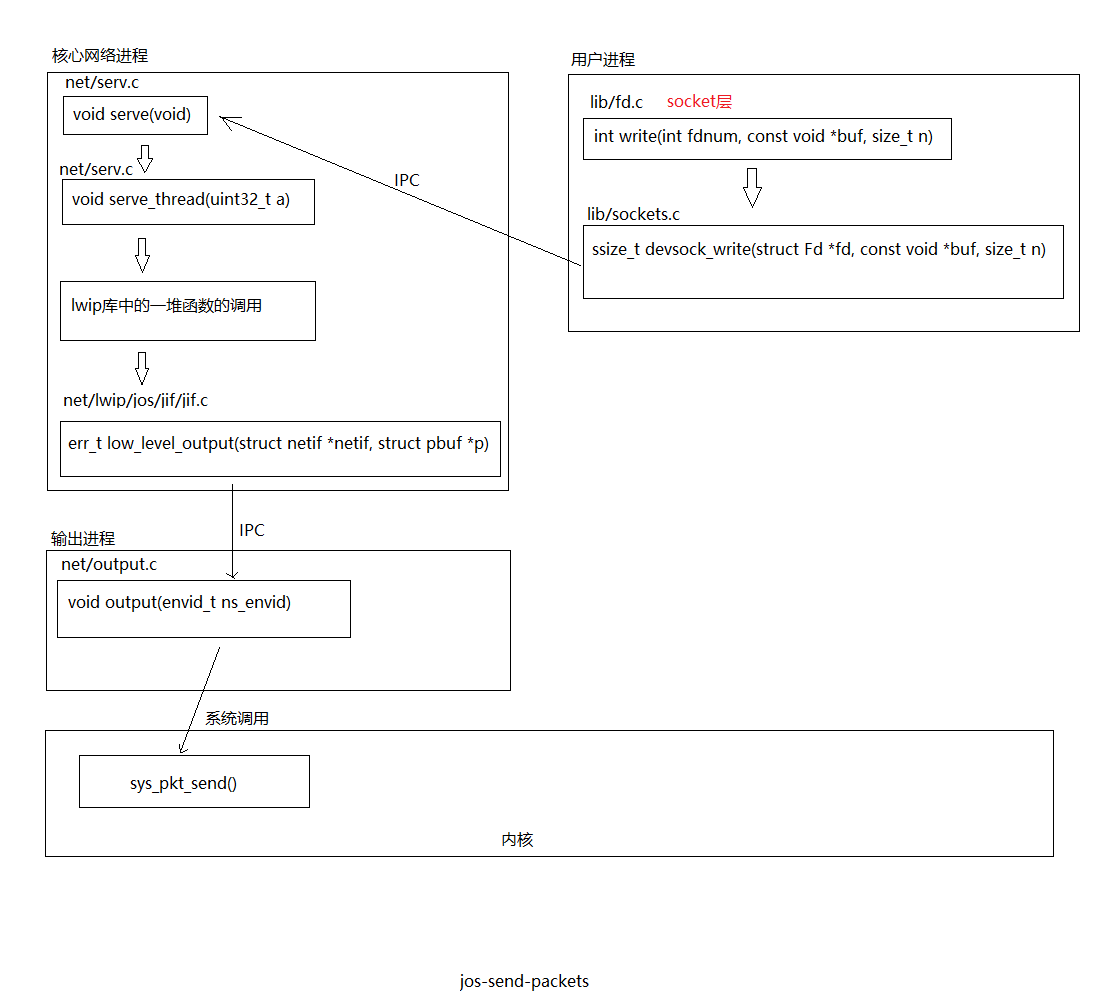
輸出協助進程的任務是,執行一個無限迴圈,在該迴圈中接收核心網路進程的IPC請求,解析該請求,然後使用系統調用發送數據。如果不理解,重新看看第一張圖。
Exercise 8
實現net/output.c.
void
output(envid_t ns_envid)
{
binaryname = "ns_output";
// LAB 6: Your code here:
// - read a packet from the network server
// - send the packet to the device driver
uint32_t whom;
int perm;
int32_t req;
while (1) {
req = ipc_recv((envid_t *)&whom, &nsipcbuf, &perm); //接收核心網路進程發來的請求
if (req != NSREQ_OUTPUT) {
cprintf("not a nsreq output\n");
continue;
}
struct jif_pkt *pkt = &(nsipcbuf.pkt);
while (sys_pkt_send(pkt->jp_data, pkt->jp_len) < 0) { //通過系統調用發送數據包
sys_yield();
}
}
}發送一個數據包的流程
有必要總結下發送數據包的流程,我畫了個圖,總的來說還是圖一的細化:
Part B: Receiving packets and the web server
總的來說接收數據包和發送數據包很相似。直接看原文就行。
有必要總結下用戶級線程實現。
用戶級線程實現:
具體實現在net/lwip/jos/arch/thread.c中。有幾個重要的函數重點說下。
- thread_init(void):
void
thread_init(void) {
threadq_init(&thread_queue);
max_tid = 0;
}
static inline void
threadq_init(struct thread_queue *tq)
{
tq->tq_first = 0;
tq->tq_last = 0;
}初始化thread_queue全局變數。該變數維護兩個thread_context結構指針。分別指向鏈表的頭和尾。
線程相關數據結構:
struct thread_queue
{
struct thread_context *tq_first;
struct thread_context *tq_last;
};
struct thread_context {
thread_id_t tc_tid; //線程id
void *tc_stack_bottom; //線程棧
char tc_name[name_size]; //線程名
void (*tc_entry)(uint32_t); //線程指令地址
uint32_t tc_arg; //參數
struct jos_jmp_buf tc_jb; //CPU快照
volatile uint32_t *tc_wait_addr;
volatile char tc_wakeup;
void (*tc_onhalt[THREAD_NUM_ONHALT])(thread_id_t);
int tc_nonhalt;
struct thread_context *tc_queue_link;
};其中每個thread_context結構對應一個線程,thread_queue結構維護兩個thread_context指針,分別指向鏈表的頭和尾。
- thread_create(thread_id_t tid, const char name, void (*entry)(uint32_t), uint32_t arg):
int
thread_create(thread_id_t *tid, const char *name,
void (*entry)(uint32_t), uint32_t arg) {
struct thread_context *tc = malloc(sizeof(struct thread_context)); //分配一個thread_context結構
if (!tc)
return -E_NO_MEM;
memset(tc, 0, sizeof(struct thread_context));
thread_set_name(tc, name); //設置線程名
tc->tc_tid = alloc_tid(); //線程id
tc->tc_stack_bottom = malloc(stack_size); //每個線程應該有獨立的棧,但是一個進程的線程記憶體是共用的,因為共用一個頁表。
if (!tc->tc_stack_bottom) {
free(tc);
return -E_NO_MEM;
}
void *stacktop = tc->tc_stack_bottom + stack_size;
// Terminate stack unwinding
stacktop = stacktop - 4;
memset(stacktop, 0, 4);
memset(&tc->tc_jb, 0, sizeof(tc->tc_jb));
tc->tc_jb.jb_esp = (uint32_t)stacktop; //eip快照
tc->tc_jb.jb_eip = (uint32_t)&thread_entry; //線程代碼入口
tc->tc_entry = entry;
tc->tc_arg = arg; //參數
threadq_push(&thread_queue, tc); //加入隊列中
if (tid)
*tid = tc->tc_tid;
return 0;
}該函數很好理解,直接看註釋就能看懂。
- thread_yield(void):
void
thread_yield(void) {
struct thread_context *next_tc = threadq_pop(&thread_queue);
if (!next_tc)
return;
if (cur_tc) {
if (jos_setjmp(&cur_tc->tc_jb) != 0) //保存當前線程的CPU狀態到thread_context結構的tc_jb欄位中。
return;
threadq_push(&thread_queue, cur_tc);
}
cur_tc = next_tc;
jos_longjmp(&cur_tc->tc_jb, 1); //將下一個線程對應的thread_context結構的tc_jb欄位恢復到CPU繼續執行
}該函數保存當前進程的寄存器信息到thread_context結構的tc_jb欄位中,然後從鏈表中取下一個thread_context結構,並將其tc_jb欄位恢復到對應的寄存器中,繼續執行。
jos_setjmp()和jos_longjmp()由彙編實現,因為要訪問寄存器嘛。
ENTRY(jos_setjmp)
movl 4(%esp), %ecx // jos_jmp_buf
movl 0(%esp), %edx // %eip as pushed by call
movl %edx, 0(%ecx)
leal 4(%esp), %edx // where %esp will point when we return
movl %edx, 4(%ecx)
movl %ebp, 8(%ecx)
movl %ebx, 12(%ecx)
movl %esi, 16(%ecx)
movl %edi, 20(%ecx)
movl $0, %eax
ret
ENTRY(jos_longjmp)
// %eax is the jos_jmp_buf*
// %edx is the return value
movl 0(%eax), %ecx // %eip
movl 4(%eax), %esp
movl 8(%eax), %ebp
movl 12(%eax), %ebx
movl 16(%eax), %esi
movl 20(%eax), %edi
movl %edx, %eax
jmp *%ecx總結回顧
- 實現網卡驅動。
- 通過MMIO方式訪問網卡,直接通過記憶體就能設置網卡的工作方式和特性。
- 通過DMA方式,使得網卡在不需要CPU干預的情況下直接和記憶體交互。具體工作方式如下: 以發送數據為例,維護一個發送隊列,生產者將要發送的數據放到發送隊列中tail指向的描述符對應的緩衝區,同時更新tail指針。網卡作為消費者,從head指向的描述符對應的緩衝區拿到數據併發送出去,然後更新head指針。
- 用戶級線程實現。主要關註三個函數就能明白原理:
- thread_init()
- thread_create()
- thread_yield()
最後老規矩
具體代碼在:https://github.com/gatsbyd/mit_6.828_jos
如有錯誤,歡迎指正(*^_^*):
15313676365


