
一、什麼是索引。 索引是用來加速查詢的技術的選擇之一,在通常情況下,造成查詢速度差異 的因素就是索引是否使用得當。當我們沒有對數據表的某一欄位段或者多個 欄位添加索引時,實際上執行的全表掃描操作,效率很低。而如果我們為某 些欄位添加索引, 在執行搜索時便可以通過掃描索引,然後再找出索 引對應的值,從 ...
一、什麼是索引。
索引是用來加速查詢的技術的選擇之一,在通常情況下,造成查詢速度差異 的因素就是索引是否使用得當。當我們沒有對數據表的某一欄位段或者多個 欄位添加索引時,實際上執行的全表掃描操作,效率很低。而如果我們為某 些欄位添加索引,mysql在執行搜索時便可以通過掃描索引,然後再找出索 引對應的值,從而提高效率。
二、索引的類型
實際上索引的類型不多,以下只是針對個人以前遇到的索引概念的解釋,有 可能某個索引有多種稱呼,只是取決於你用哪個角度去描述它。
B樹索引:採用B-trees數據結構存儲索引,比如PRIMARY KEY,UNIQUE,INDEX。Hash索引:將一個散列函數應用於每一個列值,最終的散列值都會被存入索引,用於執行查找。R樹索引:採用R-trees數據結構存儲索引,比如Spatial index。(空間數據類型的索引)- 全文索引
(FULLTEXT INDEX):一般在CHAR,VARCHAR或者TEXT列上創建此索引。可用來代替like ‘%xx%’實現模糊查詢。 - 首碼索引:只對一個列或者多個列的前幾個字元或者位元組索引。
- 唯一索引:只對一個列創建索引。
- 多列索引:對多個列創建索引。在多列索引中必須註意最左首碼這個原則。比如對於
(col1,col2,col3)這三列進行索引時,只有(col1),(col1,col2),(col1,col2,col3)才能進行索引搜索。
註意(col1,col3)也不能進行索引。 - 聚簇索引:每個
InnoDB表都有一個特殊的索引稱為聚簇索引,一般來說,當為一個表定義一個PRIMAY KEY時,InnoDB就會使用它作為聚簇索引。如果沒有定義PRIMARY KEY時,MySQL就會查找第一個非空的UNIQUE index作為聚簇索引。如果以上兩種情況都不滿足的話,InnoDB內部會在表的每一行產生一個隱藏的並且名為GEN_CLUST_INDEX的聚簇索引。這個聚簇索引是一個六個位元組長度的行ID欄位,ID值隨著新行的插入而單調增長。實際上,除了聚簇索引,其他索引都稱為二級索引。在InnoDB中,二級索引的每一行(將索引假設為行方便理解,實際上索引的存儲方式取決於具體的存儲引擎)中都包含著一個PRIMARY KEY列,InnoDB使用PRIMARY KEY這一列的列值在聚簇索引中查找相對應的數據(可以將聚簇 索引理解為中間值),從而最後得到最終的結果集。聚簇索引的數據分佈如下圖:(圖來自《高性能MySQL》)
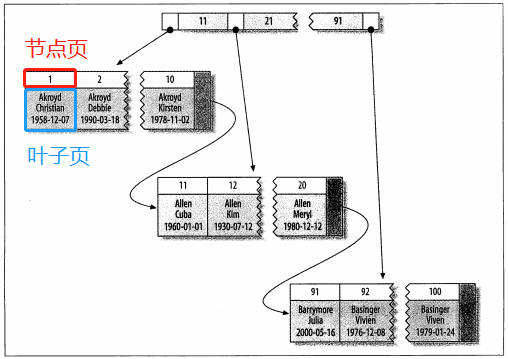
上圖中,節點頁存放是索引(對應著二級索引的PRIMARY KEY),葉子頁存放著所對應的數據,節點頁和葉子頁這個整體就稱為聚簇索引,由此可見,聚簇索引更像是一種數據存儲結構。 - 覆蓋索引:當查詢的結果集可以通過所創建的索引查找出來時,這個索引就稱為覆蓋索引。
下麵舉個例子:

對於上面這個表,當執行下麵的語句時,就會使用覆蓋索引查詢。

因為我們在創建表的時候對last_name、first_name創建了多列索引,並且在查詢的時候只查詢這兩列的結果,因此MySQL會使用覆蓋索引查詢數據,這也意味著MySQL不會對實際的數據行進行查詢,因為所需結果已經可以從索引中查找出來了。
另外可以看一下下麵的SQL語句:
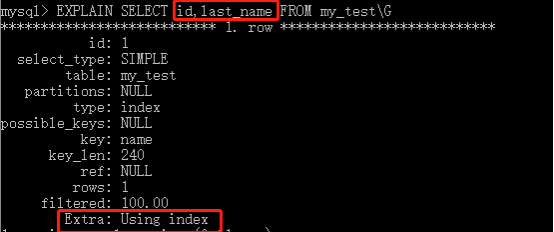
在上面的SQL語句中,我們想查詢id和last_name的值,而id是主鍵,last_name是多列索引中的最左索引,但是此時的查詢依舊使用覆蓋索引查詢。原因在於id實際是作為聚簇索引的,而多列索引自然就是二級索引了,上面提到,二級索引都包含著一列PRIMARY KEY列,而列值就是聚簇索引的索引值,因此此時MySQL可以直接使用覆蓋索引中查找出對應的結果集。
三、B樹索引和Hash索引的比較
InnoDB存儲引擎和MyISAM存儲引擎都只支持B樹索引(實際上InnoDB還支持自適應的hash索引,只是不能人為創建),MEMORY存儲引擎預設使用hash索引,但它也支持B樹索引。- 在使用
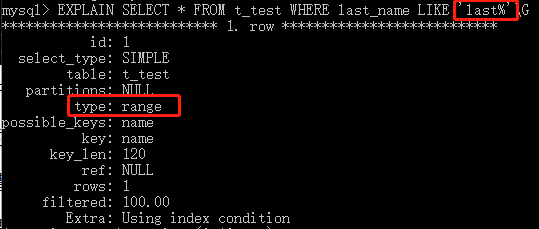
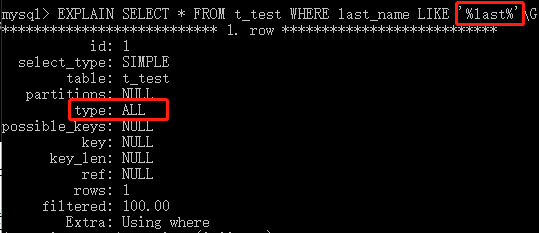
<、<=、=、>=、>、<>、!=和BETWEEN運算符,進行精確比較或者範圍比較時,使用B樹索引會帶來高效。如果匹配模式是以一個純字元串,而不是一個通配符作為開頭的,那麼B樹索引還可以用在使用like進行模式匹配的操作里。
下麵舉個例子:

- 對於
hash索引,在使用運算符=或者<=>(安全等於的意思,當比較的值含有null值的時候,來返回一個布爾值)完成精確(這裡說精確是因為hash索引是用一個hash函數對整個列值hash,而不是某幾個字元或者位元組)匹配的比較操作里,散列索引的速度非常快。

四、索引的挑選
- 一般對於出現在
WHERE子句中的列、連接子句中的列、或者出現在ORDER BY或GROUP BY子句中的列創建索引是比較好的。 - 儘量索引短小值。應儘量選用較小的數據類型。比如值的長度不超過
25個字元,那麼就不要用CHAR(200),其他數據類型同理。特別是InnoDB表來說,因為它使用的是聚簇索引,如果主鍵過長的話,會導致二級索引占用的存儲空間過大。 - 索引字元串值的首碼。當對字元串列進行索引時,應當儘可能指定首碼長度。比如某一個列的前N個字元足夠唯一的話,那麼就可以不用為整列進行索引。
五、索引的代價
索引確實可以加快檢索速度,但是它同時也降低了索引列的插入、刪除和更新值的速度,因為寫入一個行不僅是寫入一個數據行,還要更改索引。表的索引越多,需要做出的更改就越多,平均性能下降得也就越多。並且當所創建的索引過多時,mysql查詢優化器在選擇使用哪種索引方案時,也會降低一定的效率。其次,索引也會占用磁碟空間,多個索引會占據更大的空間。與沒有索引相比,使用索引很快便達到表的大小極限。
六、創建索引
- 使用
CREATE TABLE創建索引(index_name可選)

- 使用ALTER TABLE為已有表創建索引(index_name可選)

- 使用CREATE INDEX創建索引(index_name不可省略)
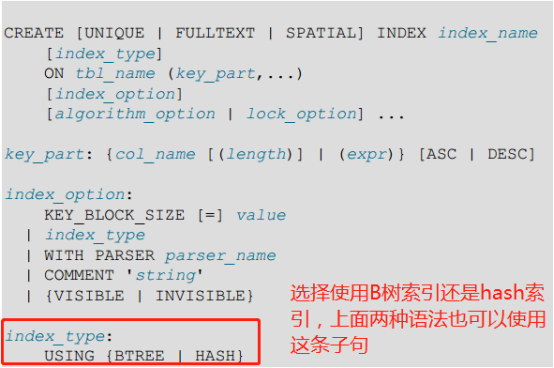
如果某個索引列在索引時使用了PRIMARY KEY或SPATIAL,則它必須為NOT NULL的。其他索引列允許包含NULL值。
如果想要限制某個索引,讓它只包含唯一值,那麼可以把這個索引創建為PRIMARY KEY或UNIQUE索引。 這兩種索引很像,主要區別有一下兩點: - 每個表只能包含一個
PRIMARY KEY。因為PRIMARY KEY的名字總是為PRIMARY,而同一個表不允許有兩個同名的索引。可以在一個表裡放置多個UNIQUE索引。 PRIMARY KEY不可以包含NULL值,而UNIQUE索引可以。如果某個UNIQUE索引包含了NULL值,那麼它就可以包含多個NULL值。因為NULL值不會與任何值相等,包括它本身。
七、刪除索引
最後,我們可以通過DROP INDEX或ALTER TABLE語句來刪除索引
- 通過DROP INDEX刪除索引

- 通過
DROP INDEX刪除索引

八、[PRIMARY|UNIQUE]KEY與[UNIQUE]INDEX的關係
首先來看一下MySQL創建表的語句:(圖來自《MySQL官方文檔》,圖太大所以省略了一部分)

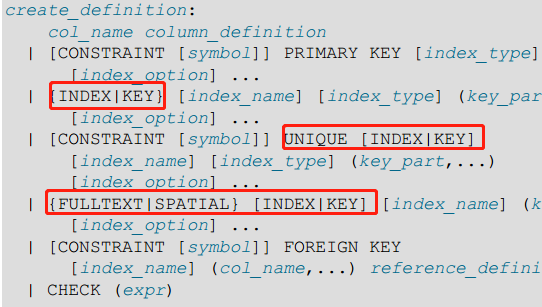
從上圖可以看出,實際上INDEX和KEY是同義詞,之所以同時存在主要是為了與其他資料庫系統做相容,另外還有以下兩個結論。
PRIMARY KEY與UNIQUE[INDEX|KEY]很相似,具體區別可以查看上面的內容。
INDEX和KEY允許出現相同的列值,但是UNIQUE[INDEX|KEY]不允許出現相同的列值。(記住NULL != NULL)
九、參考資料
- MySQL 8.0官方文檔
- 《高性能MySQL》第三版
- 《MySQL技術內幕》第五版
- https://stackoverflow.com/questions/707874/differences-between-index-primary-unique-fulltext-in-mysql


