
轉載:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分散式發佈-訂閱消息系統。它最初由LinkedIn公司開發,之後成為Apache項目的一部分。Kafka是一個分散式的,可劃分的,冗餘備份的持久性的日誌服務。它主要用 ...
轉載:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分散式發佈-訂閱消息系統。它最初由LinkedIn公司開發,之後成為Apache項目的一部分。Kafka是一個分散式的,可劃分的,冗餘備份的持久性的日誌服務。它主要用於處理活躍的流式數據。 在大數據系統中,常常會碰到一個問題,整個大數據是由各個子系統組成,數據需要在各個子系統中高性能,低延遲的不停流轉。傳統的企業消息系統並不是非常適合大規模的數據處理。為了已在同時搞定線上應用(消息)和離線應用(數據文件,日誌)Kafka就出現了。Kafka可以起到兩個作用:
- 降低系統組網複雜度。
- 降低編程複雜度,各個子系統不在是相互協商介面,各個子系統類似插口插在插座上,Kafka承擔高速數據匯流排的作用。
- 同時為發佈和訂閱提供高吞吐量。據瞭解,Kafka每秒可以生產約25萬消息(50 MB),每秒處理55萬消息(110 MB)。
- 可進行持久化操作。將消息持久化到磁碟,因此可用於批量消費,例如ETL,以及實時應用程式。通過將數據持久化到硬碟以及replication防止數據丟失。
- 分散式系統,易於向外擴展。所有的producer、broker和consumer都會有多個,均為分散式的。無需停機即可擴展機器。
- 消息被處理的狀態是在consumer端維護,而不是由server端維護。當失敗時能自動平衡。
- 支持online和offline的場景。

- Topic:特指Kafka處理的消息源(feeds of messages)的不同分類。
- Partition:Topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的隊列。partition中的每條消息都會被分配一個有序的id(offset)。
- Message:消息,是通信的基本單位,每個producer可以向一個topic(主題)發佈一些消息。
- Producers:消息和數據生產者,向Kafka的一個topic發佈消息的過程叫做producers。
- Consumers:消息和數據消費者,訂閱topics並處理其發佈的消息的過程叫做consumers。
- Broker:緩存代理,Kafka集群中的一臺或多台伺服器統稱為broker。
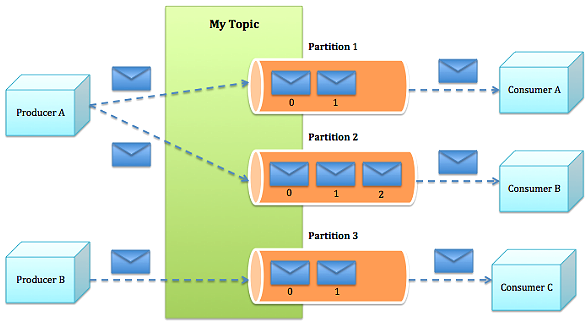
- Producer根據指定的partition方法(round-robin、hash等),將消息發佈到指定topic的partition裡面
- kafka集群接收到Producer發過來的消息後,將其持久化到硬碟,並保留消息指定時長(可配置),而不關註消息是否被消費。
- Consumer從kafka集群pull數據,並控制獲取消息的offset
- 數據磁碟持久化:消息不在記憶體中cache,直接寫入到磁碟,充分利用磁碟的順序讀寫性能
- zero-copy:減少IO操作步驟
- 數據批量發送
- 數據壓縮
- Topic劃分為多個partition,提高parallelism
- producer根據用戶指定的演算法,將消息發送到指定的partition
- 存在多個partiiton,每個partition有自己的replica,每個replica分佈在不同的Broker節點上
- 多個partition需要選取出lead partition,lead partition負責讀寫,並由zookeeper負責fail over
- 通過zookeeper管理broker與consumer的動態加入與離開
- 簡化kafka設計
- consumer根據消費能力自主控制消息拉取速度
- consumer根據自身情況自主選擇消費模式,例如批量,重覆消費,從尾端開始消費等


