
互聯網時代里,網路爬蟲是一種高效地信息採集利器,可以快速準確地獲取網上的各種數據資源。本文使用Python庫requests、Beautiful Soup爬取CSDN博客的相關信息,利用txt文件轉存。 基礎知識: 網路爬蟲是一種高效地信息採集利器,利用它可以快速、準確地採集互聯網上的各種數據資源, ...
互聯網時代里,網路爬蟲是一種高效地信息採集利器,可以快速準確地獲取網上的各種數據資源。本文使用Python庫requests、Beautiful Soup爬取CSDN博客的相關信息,利用txt文件轉存。
基礎知識:
網路爬蟲是一種高效地信息採集利器,利用它可以快速、準確地採集互聯網上的各種數據資源,幾乎已經成為大數據時代IT從業者的必修課。簡單點說,網路爬蟲就是獲取網頁並提取和保存信息的自動化過程,分為下列三個步驟:獲取網頁、提取信息、保存數據。
1.獲取網頁
使用requests發送GET請求獲取網頁的源代碼。以獲取百度為例:
import requests response = requests.get('https://www.baidu.com') print(response.text)
2.提取信息
Beautiful Soup是Python的一個HTML或XML解析庫,速度快,容錯能力強,可以方便、高效地從網頁中提取數據。基本用法:
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.prettify()) print(soup.title.string)
Beautiful Soup方法選擇器:
find_all()查詢符合條件的所有元素,返回所有匹配元素組成的列表。API如下:
find_all(name,attrs,recursive,text,**kwargs)
find()返回第一個匹配的元素。舉個慄子:
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.find('div', attrs={'class': 'article-list'}))
3.保存數據
使用Txt文檔保存,相容性好。
使用with as語法。在with控制塊結束的時候,文件自動關閉。舉個慄子:
with open(file_name, 'a') as file_object: file_object.write("I love programming.\n") file_object.write("I love playing basketball.\n")
分析頁面:
要爬取的頁面是博客園“我的博客”:https://www.cnblogs.com/sgh1023/。
使用Chrome的開發者工具(快捷鍵F12),可以查看這個頁面的源代碼。
HTML代碼說白了其實就是一棵樹,這棵樹的根節點為html標簽,head標簽和body標簽是它的子節點,當然有時候還會有script標簽。body標簽下麵又會有許多的p標簽、div標簽、span標簽、a標簽等,共同構造了這棵大樹。
可以很容易看到這個頁面的博文列表是一個id為mainContent的div。

在class為postTitle的div裡面可以找到鏈接和標題,這就是本文爬取的目標。
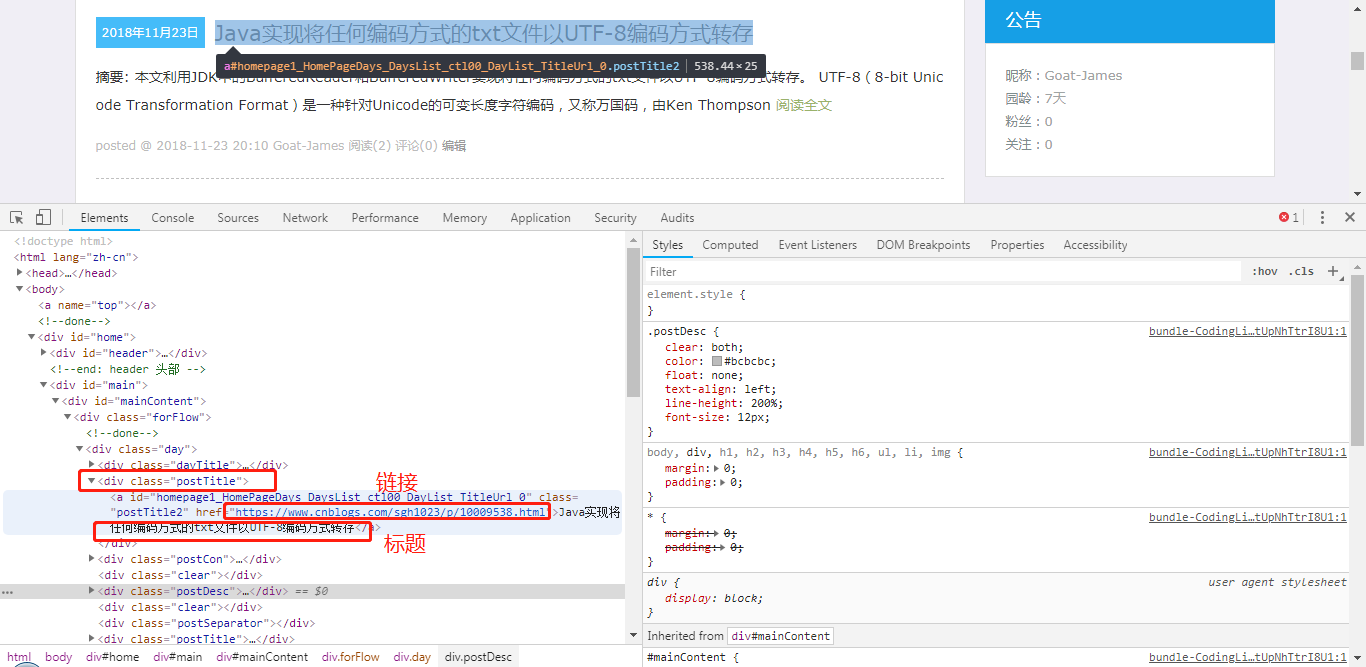
編寫代碼:
獲取網頁使用requests ,提取信息使用Beautiful Soup,存儲使用txt就可以了。
# coding: utf-8 import re import requests from bs4 import BeautifulSoup def get_blog_info(): headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) ' 'Ubuntu Chromium/44.0.2403.89 ' 'Chrome/44.0.2403.89 ' 'Safari/537.36'} html = get_page(blog_url) soup = BeautifulSoup(html, 'lxml') article_list = soup.find('div', attrs={'id': 'mainContent'}) article_item = article_list.find_all('div', attrs={'class': 'postTitle'}) for ai in article_item: title = ai.a.text link = ai.a['href'] print(title) print(link) write_to_file(title+'\t') write_to_file(link+'\n') def get_page(url): try: headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) ' 'Ubuntu Chromium/44.0.2403.89 ' 'Chrome/44.0.2403.89 ' 'Safari/537.36'} response = requests.get(blog_url, headers=headers, timeout=10) return response.text except: return "" def write_to_file(content): with open('article.txt', 'a', encoding='utf-8') as f: f.write(content) if __name__ == '__main__': blog_url = "https://www.cnblogs.com/sgh1023/" get_blog_info()
爬取結果:




